高速予測モデラ
高速予測モデラについて
高速予測モデラの概要
SAS高速予測モデラは、次の種類のデータマイニング分類および回帰問題のモデルを構築するために設計されています。
-
離散変数の値を予測する分類モデル。例としては、真か偽、購入か拒否、高/中/低、解約か継続など変数の値を予測する分類モデルなどがあります。
-
連続変数の値を予測する回帰モデル。例としては、連続値を使用して収益、売上、または成功率などの量を予測する回帰モデルなどがあります。
SAS高速予測モデラを使用してモデルを作成するには、すべての行が独立した予測変数(入力)のセットを含むデータセットと少なくとも1つの従属変数(ターゲット)を含むデータセットを指定する必要があります。SAS高速予測モデラは、変数が連続であるかカテゴリであるかを判定し、モデルに含めるべき入力変数を選択します。
モデルは、SASコードとして保存し、SAS環境に配備することができます。SASモデルのコードを使用して新しいデータをスコアリングし、その結果を使用してより詳細な情報に基づいた経営判断を行うことができます。このプロセスをモデルのスコアリングと呼びます。たとえば、スコアリングしたデータを使用してどの顧客を解約するか決定したり、不正な取引を見つけたりすることができます。
SAS高速予測モデラのサンプリング方法
SAS高速予測モデラは、複合サンプリング手法を使用しています。データサンプルに含まれるオブザベーションの数は次の要因によって異なります。
-
入力変数の数
-
データソース内のオブザベーションの合計数
-
データにまれなイベントターゲットが含まれているかどうか
-
データ内のイベント数
以下にSAS高速予測モデラが処理するオブジェクトの数を決定するために使用するガイドラインを示します。
|
入力変数の数
|
処理するオブザベーションの数
|
|---|---|
|
<100
|
80,000
|
|
100-200
|
40,000
|
|
>200
|
20,000
|
次の表の条件について、以下にいくつかの重要な点を示します。
-
処理中のオブザベーションの数は、入力変数の数により決定されます。上記の表を参照してください。
-
予測モデリングでは、バイナリターゲットをモデル化している場合、ターゲット変数のイベント水準は0または1です。イベント水準はまた、「はい」か「いいえ」を使用するようにフォーマットすることができました。以下は一例です。銀行は、顧客の信用状態が悪いかどうかを予測しようとしています。トレーニングデータでは、信用状態が悪い各顧客は「はい」に設定されています。これはその顧客にイベントが発生したことを意味します。信用状態が良い各顧客は、イベントがないと見なされます。
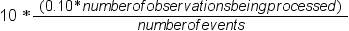
SAS高速予測モデラのデータの整理
モデルを作成する前に、予測に使用できる過去のイベントおよび特性を表す入力データが必要です。また、予測するイベントまたは値を表すターゲットデータも必要です。多くの場合、入力データは、1つの期間から派生し、ターゲットデータは、後の期間から派生します。モデルの作成に使用する入力とターゲットデータの組み合わせをトレーニングデータと呼びます。
たとえば、来年の予想売上高を予測したり、どの顧客が商談に反応するかを予測するために昨年の売上を使用することがあります。将来のイベントの実績を予測するために、過去のイベントの履歴データを使用することをモデルのトレーニングと呼びます。
最良のモデリング結果を得るには、モデルのトレーニングデータは、データの行として格納されている多くのオブザベーションの数を含む必要があります.たとえば、多くの小売業顧客モデルは、数万のオブザベーションの数を持つ入力データを使用しています。
ターゲット変数がまれなイベント(たとえば、顧客の1%だけが反応する商談)を含む場合、トレーニングデータはこれらの顧客のかなりの数をデータセットに含む必要があります。商談に反応したすべての顧客と、しなかった同数の顧客を確実に選択するために、トレーニングデータをオーバーサンプリングすることができます。オーバーサンプリングすることにより、まれなイベントターゲットを含むモデルの安定した解をより簡単に見つけることができます。
トレーニングデータ内のまれなイベントの発生を高めるためにオーバーサンプリングを行うと、人為的にトレーニングデータ内の対象となるデータの発生を自然母集団と相対的にふくらませることになります。トレーニングデータと母集団データとの差を補完するため、SAS高速予測モデラは事前確率の設定を提供します。事前確率の設定は、母集団データ内の対象となるイベントの真の比例度数を指定します。
SAS高速予測モデラを使用してマイニングするデータは、行(オブザベーション)と列(変数)に整理する必要があります。いずれかの列がターゲット変数を表す必要があります。
名前
各オブザベーションのID値を含む列。SAS高速予測モデラは、ID変数列の分析内容を処理しません。
年齢、性別、収入、および処理
SAS高速予測モデラが使用する入力列。
購入
ターゲット列。
入力データのテーブルを設定するとき、度数列を指定することができます。度数列の値は負ではない整数で、合計が1になる必要があります。
モデルから除く変数役割を使用して、分析時にSAS高速予測モデラに無視させる列を選択することもできます。
トレーニングデータは、常に入力変数値とターゲット変数値を必要とします。スコアリングに使用するデータは、入力変数値のみ必要とし、ターゲット列はオプションです。新しいデータから予測を行うためにモデルを使用する場合、ターゲット列は不要です。有効性を観察するためにモデルを使用する場合、ターゲット列は必要です。スコアリングに使用するデータは、通常、ID列を含みます。
役割へのデータの割り当て
高速予測モデラを実行するには、従属変数役割に変数を割り当てる必要があります。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
従属変数
|
予測または分類する値を指定します。従属変数は、ターゲット変数とも呼ばれます。
|
|
ディシジョンと事前確率
|
次の情報を指定します。
|
|
追加役割
|
|
|
モデルから除く変数
|
分析に含めたくない変数を指定します。
|
|
度数カウント
|
度数値を表すために使用する変数を指定します。データは、それぞれのケースが度数変数の値と同じ回数だけ複製されているかのように扱われます。
|
|
ID変数
|
レポートとスコアリング選択機能に有用な変数を指定します。これらの変数は、分析に含まれません。
|
モデルオプションの設定
モデルの選択
これらのオプションを使用すると、構築するモデルの複雑さレベルを指定することができます。モデリング手法は、階層になっています。中間手法は基本と中間モデルを含み、詳細手法は基本と中間、および詳細モデルを含みます。
基本手法を使用して作成したモデルは、おそらく中間手法を使用して作成したモデルよりも速く実行されますが、基本手法は、あまり正確ではないモデルを作成する可能性もあります。中間手法と詳細手法で作成したモデルを比較するときも多くの場合同じです。
SAS高速予測モデラを実行するとSASエンタープライズマイナーモデリング機能が実行されます。ソフトウェアが実行するモデリング機能は、選択したモデリング手法に依存します。
モデリング手法
以下のモデリング手法から選択できます。
基本
基本手法はまれなターゲットイベントがある場合にのみサンプリングし、ターゲットを層別変数として使用してデータを分割します。次に、基本手法は、1レベル変数選択手順を実行します。選択された入力変数は、ターゲットとの関係の強さに応じてビニングされ、増加ステップワイズ回帰モデルに渡されます。
中間
中間手法は、基本手法を拡張したものです。いくつかの変数選択手法が実行され、次に複数の変数変換が行われます。モデリング技法としてディシジョンツリー、回帰モデル、およびロジスティック回帰が用いられています。変数の交互作用は、ディシジョンツリーからエクスポートされたノード変数を使用して表されます。中間手法は、基本手法も実行し、その後最大の実績のモデルを選択します。
詳細
詳細手法は、中間手法を拡張したもので、ニューラルネットワークモデル、詳細回帰分析、およびアンサンブルモデルを含みます。詳細手法は、中間手法と基本手法も実行し、その後最大の実績のモデルを選択します。
SAS高速予測モデラのモデルについて
SAS高速予測モデラは、基本、中間、および詳細モデルを提供します。モデルは、この順に洗練され複雑になります。
-
基本モデルは、簡単な回帰分析です。
-
中間モデルは、より高度な分析と基本モデルの分析を含み、より良いモデルを選択します。
-
詳細モデルは、さらに高度な分析と基本および中間モデルの分析を含み、最善のモデルを選択します。
基本
基本モデルは、一連の3つのデータマイニング操作を行います。
-
変数選択:基本モデルは、モデリングのために、上位100の変数を選択します。
-
変換:基本モデルは、モデリングのために選択済み上位100の変数に最適ビニング変換を行います。最適ビニング変換は、欠損値の補完が行われないよう欠損変数の値を補正します。
-
モデリング:基本モデルは、増加回帰モデルを使用します。増加回帰モデルは、段階的プロセスで変数を1つずつ選択します。段階的プロセスは、変数の寄与が軽微になるまで線形方程式に変数を1つずつ追加します。増加回帰モデルは、解析的分析から予測能力がない変数(あるいは他の予測変数と強い相関がある変数)を除外しようとします。
中間
中間モデルは、一連の7つのデータマイニング操作を行います。
-
変数選択:中間モデルは、モデリングのために、上位200の変数を選択します。
-
変換:中間モデルは、モデリングのために選択された200の変数の最善べき乗変換を行います。最善べき乗変換は、Box-Cox変換として知られている変換の一般的なクラスのサブセットです。最善べき乗変換は、指数べき乗変換のサブセットを評価し、その後、指定された基準の最善の結果を持つ変換を選択します。
-
補完:中間モデルは、欠損変数を平均変数値で置き換えるために補完を行います。補完操作は、特定する補完変数値を含むオブザベーションを可能にするインジケータ変数も作成します。
-
変数選択:中間モデルは、ターゲット変数に関連していない変数を削除するために、カイ2乗とR2乗基準テストを使用しています。
-
変数選択手法の集合:中間モデルは、カイ2乗とR2乗基準テストで選択された変数のセットをマージします。
-
モデリング:中間モデルは、トレーニングデータを3つの競合モデルアルゴリズムにサブミットします。モデルは、ディシジョンツリー、ロジスティック回帰、およびステップワイズ回帰です。ロジスティック回帰モデルの場合、トレーニングデータは、まず回帰モデルへの入力として渡されるNODE_ID変数を作成するディシジョンツリーにサブミットされます。NODE_ID変数は、変数の交互作用モデルを可能にするために作成されます。
-
チャンピオンモデル選択:中間モデルは、競合モデルの予測または分類性能の解析評価を行います。最良の予測または分類性能を示すモデルが、モデリング分析を行うために選択されます。チャンピオンモデル選択のための中間モデルは、中間モデルだけでなく、基本モデルの性能も評価します。
SAS高速予測モデラは、中間チャンピオンモデルを選択した後、中間チャンピオンモデルの予測性能を基本モデルと比較し、より良いモデルを選択します。
詳細
詳細モデルは、一連の7つのデータマイニング操作を行います。
-
変数選択:詳細モデルは、モデリングのために、上位400の変数を選択します。
-
変換:詳細モデルは、モデリングのために選択された400の変数に複数の変換アルゴリズムを実行します。複数の変換操作は、後の変数選択で使用するいくつかの変数変換を作成します。複数の変換により、入力変数の数が増加します。入力変数が増加するため、SAS高速予測モデラは複数の変換アルゴリズムから生成された出力から最善の400個の入力変数を選択します。
-
補完:詳細モデルは、欠損変数を平均変数値で置き換えるために補完を行います。補完操作は、補完変数値を含むオブザベーションの特定を可能にするインジケータ変数も作成します。
-
変数選択:詳細モデルは、ターゲット変数に関連していない変数を削除するために、カイ2乗とR2乗基準テストを使用しています。R2乗分析時にAOV16変数が作成されます。
-
変数選択手法の集合:詳細モデルは、カイ2乗とR2乗基準テストで選択された変数のセットをマージします。
-
モデリング:詳細モデルは、トレーニングデータを4つの競合モデルアルゴリズムにサブミットします。モデルは、ディシジョンツリーモデル、ニューラルネットワークモデル、減少回帰モデル、およびアンサンブルモデルです。ニューラルネットワークモデルは、最適なフィードフォワードネットワークを見つけるため限られた検索を行います。減少回帰は、R2乗スコアが大幅に低下するまで変数を1つずつ除去して排除する線形回帰モデルです。アンサンブルモデルは、複数の先行入力モデルから(クラスターゲットの)事後確率または(間隔ターゲットの)予測値を組み合わせることによって、新しいモデルを作成します。そして新しいアンサンブルモデルは新しいデータをスコアリングするために使用されます。詳細モデルで使用するアンサンブルモデルは、基本モデルの出力、中間モデルのチャンピオンモデル、および詳細モデルのチャンピオンモデルから作成されます。
-
チャンピオンモデル選択:詳細モデルは、競合ディシジョンツリー、ニューラル、および回帰モデルの予測または分類性能の解析評価を行います。その後、最良の予測または分類性能を示すモデルがアンサンブルモデルを作成するために基本と中間モデルからのチャンピオンモデルとともに、入力として使用されます。そして、新たに作成された詳細アンサンブルモデル、ディシジョンツリーモデル、ニューラルモデル、および減少回帰モデルを分析比較して、すべての基本、中間、および詳細チャンピオンモデルのサンプル空間から最適なモデルを選択します。
SAS高速予測モデラは、チャンピオンモデルを選択した後、詳細モデルの予測性能を中間と基本モデルのチャンピオンモデルと比較し、最善のチャンピオンモデルを選択します。
レポートオプションの設定
レポートについて
レポートは、モデル内の重要な項を特定し、リフトチャートなど一般的なビジネスグラフィックスを生成します。結果には、トレーニングおよび検証データの統計量が含まれています。SAS高速予測モデラプロセスは、入力データをトレーニングデータと検証データに分割します。トレーニングデータは、各モデルのパラメータを計算に使用し、トレーニング当てはめの統計量をもたらします。その後、検証データが各モデルでスコアリングされ、検証当てはめの統計量をもたらします。検証当てはめの統計量はモデルを比較して、過剰当てはめを検出するために使用されます。トレーニング統計量が検証の統計量よりも大幅に優れている場合は、モデルがデータのランダム信号を検出するようトレーニングされているとき発生する過剰当てはめが疑われます。最高の検証統計量を持つモデルが一般的に好まれます。
SAS高速予測モデラは、モデリングに使用されたデータソースと変数の要約、重要な予測変数のランキング、モデルの精度を評価する複数の当てはめの統計量、およびモデルスコアカードを提供する簡潔なコアレポートのセットを自動的に生成します。
SAS高速予測モデラの標準レポートについて
以下にSAS高速予測モデラが自動的に生成する標準レポートを示します。
ゲインチャート
ゲインチャートプロットは、クラスターゲット変数を持つモデルにのみ使用できます。このチャートは、予測値によってランク付けされるデータのパーセント点を示しています。リフトは、ランダム選択により発見されたターゲットイベントの数と比較して、モデルが識別したターゲットイベントの数の比率の尺度です。
受信者操作特性プロット(ROC)
受信者操作特性プロットは、(単一の十分位値ではなく)サンプル全体のモデルの最大予測力を示しています。データは、感度対(1-特異度)としてプロットされています。モデル曲線と対角線(ランダム選択モデルを表す)の間の分離は、コルモゴロフ
- スミルノフ(KS)値と呼ばれています。KS値が高いほど、より強力なモデルを表します。
スコアカード
結果には、モデルの特徴をビジネス目的に解釈できるようにスコアカードが含まれています。ソフトウェアがスコアカードを作成するとき、各間隔変数は、値の異なる範囲にビニングされます。その後、各変数は、モデルの重要度によってランク付けされ、最大1,000ポイントにスケーリングされます。そして、各変数の個別の値は、スケーリングされたポイントの合計の一部を受け取ります。
プロジェクト情報
プロジェクト情報は、だれがモデルを作成したか、いつモデルが作成されたか、およびどこにモデルのコンポーネントファイルが保存されているかを示します。
出力オプションの設定
|
オプション
|
説明
|
|---|---|
|
出力データセット
|
|
|
エンタープライズマイナープロジェクトデータを保存
|
このタスクからSASエンタープライズマイナーデータを保存するかどうかを指定します。SAS高速予測モデラのモデルは、SASエンタープライズマイナープロジェクトの一例です。SASエンタープライズマイナーデータを保存すると、SASエンタープライズマイナーのインターフェイスを使用してSAS高速予測モデラを使用して作成したモデルを開いて編集するすることができます。SASエンタープライズマイナーでは、SASエンタープライズマイナーの外で使用するために分析を保存してエクスポートすることができ、SASメタデータリポジトリを使用してモデルを登録できます。
|
|
スコアリングコードをエクスポートする
|
指定した場所に、このタスクからスコアリングコードを保存します。その後、このコードを実行して他のSAS製品のデータセットをスコアリングすることができます。
|
|
入力データセットをスコアリングする
|
スコアリング値を含む出力データセットの名前を指定します。入力データセット内の値は、SAS高速予測モデラが作成するモデルによってスコアリングされます。
|