この例では、
テキストクラスタノードを使用して、SAS Users Group International (SUGI)の概要をクラスタリングします。この例では、SAS Enterprise Minerが実行されていること、およびダイアグラムワークスペースがプロジェクトで開かれていることを前提としています。プロジェクトとダイアグラムの作成に関する詳細は、
プロジェクトの設定を参照してください。
注: SAS Users Group Internationalは、現在ではSAS Global Forumとなっています。
次の手順を実行します。
-
SAMPSIO.ABSTRACT用のデータソースを作成します。変数TITLEの役割を
IDに変更します。
注: SAMPSIO.ABSTRACTデータセットには、1998~2001年までのSUGIミーティング(SUGI 23~26)のために用意された1,238件の論文に関する情報が含まれています。変数TITLEの値は、SUGI論文のタイトルになります。変数TEXTは、SUGI論文の概要を含んでいます。
-
SAMPSIO.ABSTRACTデータソースをダイアグラムワークスペースに追加します。
-
ツールバー上で
テキストマイニングタブを選択し、
テキスト解析ノードをダイアグラムワークスペースへとドラッグします。
-
データ入力ノードを
テキスト解析ノードに接続します。
-
テキスト解析ノードを選択した後、
停止リストプロパティの省略記号ボタンをクリックします。
-
テーブルの交換ボタンをクリックし、SAMPSIO.SUGISTOPを停止リストとして選択した後、
OKをクリックします。確認ダイアログボックスで
はいを選択します。
OKをクリックして、
停止リストプロパティのダイアログボックスを終了します。
-
-
エンティティの種類を無視するプロパティの省略記号ボタンをクリックし、
エンティティの種類を無視するダイアログボックスを開きます。
-
すべてのエンティティの種類を選択します。ただし、次のものは除きます。
Location、
Organization、
Person、
Product。
OKをクリックします。
-
テキストマイニングタブを選択し、
テキストフィルタノードをダイアグラムワークスペースへとドラッグします。
-
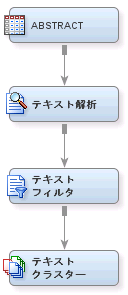
テキスト解析ノードを
テキストフィルタノードに接続します。
-
テキストマイニングタブを選択し、
テキストクラスタノードをダイアグラムワークスペースへとドラッグします。
-
テキストフィルタノードを
テキストクラスタノードに接続します。この時点で、プロセスフローダイアグラムは次のようになります。
-
テキストクラスタノードを右クリックし、
実行を選択します。
確認ダイアログボックスで
はいをクリックします。
-
同ノードの実行完了後に表示される
実行ステータスダイアログボックス内で
結果をクリックします。
-
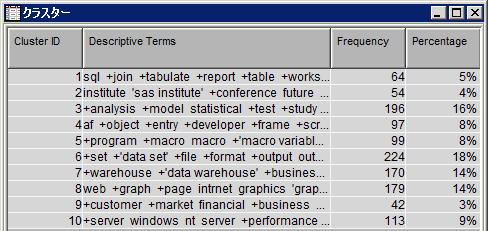
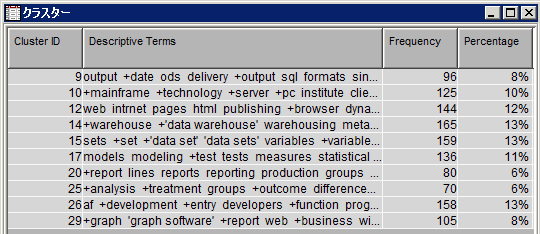
クラスタテーブルには、各クラスタのID、クラスタを構成している記述語、各クラスタの統計値が含まれています。
-
-
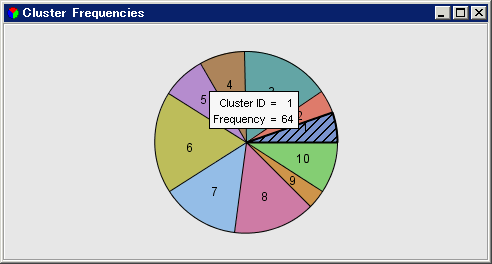
クラスタ頻度ウィンドウを選択し、クラスタを頻度別に表した円グラフを確認します。マウスポインタをセクション上に置くと、そのクラスタの頻度がツールチップ内に表示されます。
-
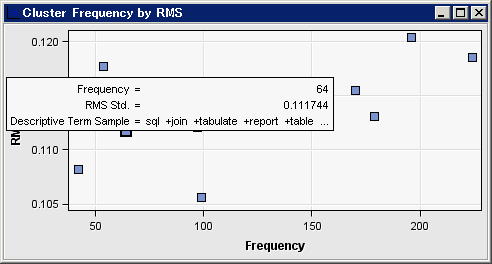
クラスタ頻度とRMSウィンドウを選択した後、強調表示されているクラスタ上にマウスポインタを置きます。
最初のクラスタとそれ以外のクラスタは距離に関してどう異なるでしょうか?
-
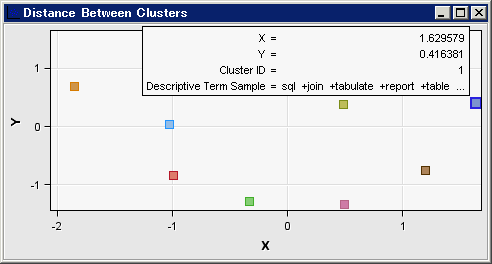
クラスタ間の距離ウィンドウを選択した後、強調表示されているクラスタ上にマウスポインタを置き、XY座標グリッド内で最初のクラスタの位置を確認します。
距離を比較したいその他のクラスタ上にマウスポインタを置きます。
-
期待値最大化クラスタリングアルゴリズムにより取得したクラスタリングの結果を、階層クラスタリングアルゴリズムを使用した場合の結果と比較します。
-
-
指定値または最大数プロパティで
指定値を選択します。
-
-
クラスタアルゴリズムプロパティで
階層を選択します。
-
テキストクラスタノードを右クリックし、
実行を選択します。
確認ダイアログボックスで
はいをクリックします。
-
同ノードの実行完了後に表示される
実行ステータスダイアログボックス内で
結果をクリックします。
-
このテーブルには10個のクラスタがありますが、クラスタIDの範囲は1~10ではないことに注意してください。
-
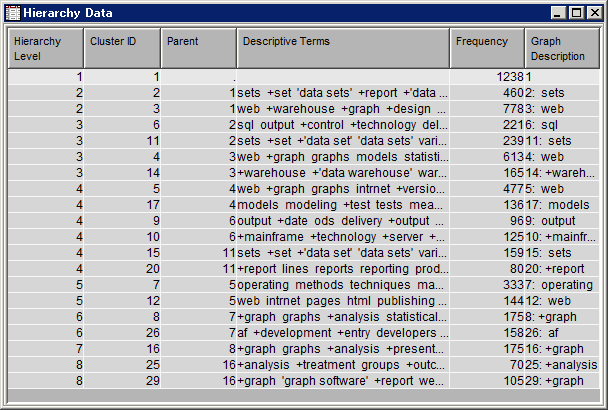
Hierarchy Dataテーブルを選択し、
クラスタテーブル内に非表示されているクラスタに関する詳細情報を確認します。
-
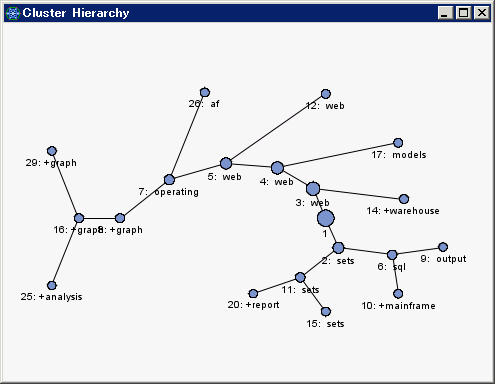
クラスタ階層グラフを選択し、クラスタの階層的なグラフィカル表現を確認します。
-