What’s New in SAS/STAT 12.1
Overview
In previous years, SAS/STAT ® software
was updated only with new releases of Base SAS® software,
but this is no longer the case. This means that SAS/STAT software
can be released to customers when enhancements are ready, and the
goal is to update SAS/STAT every 12 to 18 months. To mark this newfound
independence, the release numbering scheme for SAS/STAT is changing
with this release. This new numbering scheme will be maintained when
new versions of Base SAS and SAS/STAT ship at the same time. For example,
when Base SAS 9.4 is released, SAS/STAT 13.1 will be released.
New Procedures
New Experimental ADAPTIVEREG Procedure
The ADAPTIVEREG procedure
fits multivariate adaptive regression splines. The method is a nonparametric
regression technique that combines both regression splines and model
selection methods. It constructs spline basis functions in an adaptive
way by automatically selecting appropriate knot values for different
variables. The procedure performs model reduction by applying model
selection techniques. Thus, the ADAPTIVEREG procedure is both a nonparametric
regression procedure and a predictive modeling procedure.
The ADAPTIVEREG procedure
supports models with classification variables, and it provides options
for improving modeling speed. PROC ADAPTIVEREG extends the method
to data with response variables that are distributed in the exponential
family, including the binomial, Poisson, negative binomial, gamma,
and inverse Gaussian distributions. PROC ADAPTIVEREG is multithreaded,
enabling it to take advantage of multiple processors.
New Experimental QUANTLIFE Procedure
The QUANTLIFE procedure
implements two quantile regression approaches that have been developed
to account for right-censoring and provide valid estimates. Portnoy
(2003) proposed a method to estimate conditional quantile functions
from survival data by generalizing the idea of the Kaplan-Meier estimator
of the survival function, and Peng and Huang (2008) developed a quantile
regression approach motivated by the Nelson-Aalen estimator of the
cumulative hazard function. Both methods are implemented with linear
programming algorithms in the QUANTLIFE procedure. Like the standard
quantile regression method for uncensored data, these two methods
are distribution-free and are applicable to heteroscedastic data.
New Experimental QUANTSELECT Procedure
The QUANTSELECT procedure
performs model selection for linear quantile regression. It provides
capabilities similar to those offered by the GLMSELECT procedure (provides
model selection for univariate linear models) including forward, backward,
stepwise, LASSO, and adaptive LASSO selection methods. You can specify
criteria such as AIC, SBC, AICC, adjusted R1, and significance levels
to compare the fit of models, to determine when to stop the model
selection process, and to choose the final selection model. The QUANTSELECT
procedure supports constructed effects (such as smoothing splines
and polynomials) and the SPLIT option for its CLASS statement. PROC
QUANTREG produces parameter estimates progression plots and a variety
of criterion progression plots.
New STDRATE Procedure
The STDRATE procedure
computes direct and indirect standardized rates and risks for study
populations. With direct standardization, you compute the weighted
average of stratum-specific estimates in the study population, using
weights such as population-time from a standard or reference population.
With indirect standardization, you compute the weighted average of
stratum-specific estimates in the reference population by using weights
from the study population. The procedure provides summary statistics
such as rate and risk estimates (and their confidence limits) for
each stratum, as well as graphs.
Highlights of Enhancements in SAS/STAT 9.3
Some users might be
unfamiliar with updates made in SAS/STAT 9.3. The following are some
of the major enhancements that were introduced in SAS/STAT 9.3:
-
The experimental FMM procedure fits statistical models to data where the distribution of the response is a finite mixture of univariate distributions. These models are useful for applications such as estimating multimodal or heavy-tailed densities, fitting zero-inflated or hurdle models to count data with excess zeros, modeling overdispersed data, and fitting regression models with complex error distributions.
New Macros
Bayesian Analysis Postprocessing Macros
Postprocessing macros
are now available in the SAS autocall library. These macros duplicate
the corresponding summary and diagnostic capabilities provided by
the MCMC procedure and can be used with any SAS data set that contains
posterior samples. These macros are documented with the MCMC procedure.
Enhancements
CALIS Procedure
-
The BASEFUNC= and BASEFIT= options enable you to input the model fit information of the customized baseline model of your choice. With this input information, PROC CALIS computes various fit indices (mainly the incremental fit indices) based on your customized model fit rather than the fit of the default uncorrelatedness model.
FREQ Procedure
The Agresti-Caffo and
Miettinen-Nurminen confidence limits for the risk (proportion) difference
are now available, and any confidence limit type can now be displayed
in the risk difference plot. You can also request a continuity correction
for the Wilson confidence limits for a binomial proportion.
The PLCORR option in
the TEST statement produces Wald and likelihood ratio tests for the
polychoric correlation coefficient.
The new DF= chi-square
option specifies or adjusts the degrees of freedom for chi-square
tests. The TESTF= chi-square option now permits you to provide null
frequencies for a one-way chi-square test by using a secondary input
data set. Similarly, the TESTP= chi-square option now permits you
to provide null proportions by using a secondary input data set.
The LRCHISQ chi-square
option in the TABLES statement produces a likelihood ratio chi-square
test for one-way tables. This test can be based on a null hypothesis
of equal proportions, specified proportions, or specified frequencies.
The LRCHISQ option in the EXACT statement produces an exact likelihood
ratio chi-square test for one-way tables.
The EXACT statement
can now produce Barnard’s exact unconditional test for the
risk difference as well as an exact likelihood ratio goodness-of-fit
test.
The MAXLEVELS=n option
in the TABLES statement specifies the maximum number of variable levels
to display in one-way frequency tables; it also applies to one-way
frequency plots.
GLIMMIX Procedure
LIFETEST Procedure
The LIFETEST procedure
now supports a WEIGHT statement. For survival plot enhancements, the
MAXLEN= option of the ATRISK option specifies a maximum number of
characters that can be used in displaying stratum labels, and the
OUTSIDE option of the ATRISK option specifies that the at-risk table
be drawn outside the plot area. If you assign a label to a strata
variable, that label is used in all tables and graphs.
LOGISTIC Procedure
PROC LOGISTIC provides
partial proportional odds logistic regression with the UNEQUALSLOPES
option in the MODEL statement. The ESTIMATE, LSMEANS, LSMESTIMATE,
SLICE, and STORE statements can now be used for a stratified analysis.
The PCORR option in the MODEL statement computes the partial correlation
statistic for each model parameter (excluding the intercept).
The ID statement specifies
variables in the DATA= data set that are used for labeling ROC curves
and influence diagnostic plots.
PHREG Procedure
SEQDESIGN Procedure
The MODEL=INPUTNEVENTS
option in the SAMPLESIZE statement specifies the number of events
from a fixed-sample study of survival data. There are two new INPUTEVENTS
options for the sample size computation: ACCRUAL= and LOSS=. The ACCRUAL=
option specifies the method for individual accrual. The LOSS= option
specifies the individual loss to follow-up in the sample size computation.
The STOP=BOTH option
in the DESIGN statement specifies the condition of early stopping
for the design. The new BETABOUNDARY=BINDING suboption computes the
Type I error probability with the acceptance boundary, and the new
BETABOUNDARY=NONBINDING suboption computes the Type I error probability
without the acceptance boundary.
SEQTEST Procedure
The BETABOUNDARY option
in the PROC SEQTEST statement specifies whether the 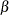 boundary is used in the computation of the Type
I error level
boundary is used in the computation of the Type
I error level  . The BETABOUNDARY=BINDING option computes the Type
I error probability with the (acceptance) boundary, and the BETABOUNDARY=NONBINDING
suboption computes the Type I error probability without the boundary.
. The BETABOUNDARY=BINDING option computes the Type
I error probability with the (acceptance) boundary, and the BETABOUNDARY=NONBINDING
suboption computes the Type I error probability without the boundary.
boundary is used in the computation of the Type
I error level . The BETABOUNDARY=BINDING option computes the Type
I error probability with the (acceptance) boundary, and the BETABOUNDARY=NONBINDING
suboption computes the Type I error probability without the boundary.
What’s Changed
FREQ Procedure
MCMC Procedure
Random-effects parameter
names are constructed using the formatted values rather than the unformatted
values.
If the MISSING= option
is not specified, PROC MCMC samples all missing values (including
partial missing in some cases) by default. Observations for which
the procedure failed to identify proper sampling algorithms are discarded
prior to the simulation. If the MISSING= option is explicitly specified
(AC or CC), the option is honored.
SURVEYSELECT Procedure
PROC SURVEYSELECT now
uses the Mersenne-Twister random number generator by default. In previous
releases, PROC SURVEYSELECT used the RANUNI random number generator.
To reproduce samples that PROC SURVEYSELECT selected in releases prior
to SAS/STAT 12.1, you can use the RANUNI option with the SEED= option
(for the same input data set and selection parameters).