What’s New in SAS/ETS 12.1
Overview
If you have used SAS/ETS
procedures in the past, you can review this chapter to learn about
the new features that have been added. When you see a new feature
that might be useful for your work, turn to the appropriate chapter
to read about the feature in detail.
In previous years, SAS/ETS ® software
was updated only with new releases of Base SAS® software,
but this is no longer the case. This means that SAS/ETS software can
be released to customers when enhancements are ready, and the goal
is to update SAS/ETS every 12 to 18 months. To mark this newfound
independence, the release numbering scheme for SAS/ETS is changing
with this release. This new numbering scheme will be maintained when
new versions of Base SAS and SAS/ETS ship at the same time. For example,
when Base SAS 9.4 is released, SAS/ETS 13.1 will be released.
AUTOREG Procedure
-
The heteroscedasticity- and autocorrelation-consistent (HAC) covariance matrix estimator is supported, which consistently estimate the covariance matrix even when the heteroscedasticity and autocorrelation structure might be unknown or misspecified. Five types of kernel functions—Bartlett, Parzen, quadratic spectral, truncated, and Tukey-Hanning kernels—are supported. The bandwidth parameter can be estimated using the Andrews (1991) method, the Newey and West (1994) method, or a flexible equation based on sample size. The prewhitening feature and adjustment of degrees of freedom are supported. The well-known Newey-West estimator is also supported.
-
Multiple structural change tests proposed by Bai and Perron (1998) are supported. Specifically, these are the test of no break versus a fixed number of breaks (
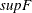 test); the equal and unequal weighted versions of
double maximum tests of no break versus an unknown number of breaks
given some upper bound (
test); the equal and unequal weighted versions of
double maximum tests of no break versus an unknown number of breaks
given some upper bound (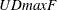 test and
test and 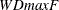 test); and the test of
test); and the test of 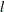 versus
versus 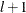 breaks (
breaks (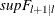 test). The tests can be applied to both pure and
partial structural change models. The p-value of each test, based
on the simulation of the limiting distribution, and the confidence
intervals of parameter estimators, including the break dates, are
also provided. The constraints on the distribution of the errors and
regressors across segments can be imposed. For estimating the covariance
matrix the HAC estimator is supported.
test). The tests can be applied to both pure and
partial structural change models. The p-value of each test, based
on the simulation of the limiting distribution, and the confidence
intervals of parameter estimators, including the break dates, are
also provided. The constraints on the distribution of the errors and
regressors across segments can be imposed. For estimating the covariance
matrix the HAC estimator is supported.
MODEL Procedure
-
The OPTIMIZE option has been added to the SOLVE statement to permit the simulation of models that include constraints on the solve variables in the model program’s system of equations. Upper and lower bounds on the solve variables can be imposed by using the BOUNDS statement, and linear or nonlinear constraints on functions of the solve variables can be imposed by using the RESTRICT statement. The OPTIMIZE option limits the solution space for simulations to the feasible region defined by constraints. When no feasible solution exists for a problem, information about how the constraints were violated are included in the OUT= data set if the OUTOBJVALS or OUTVIOLATIONS option is specified. The OPTIMIZE solution method computes constrained solutions by casting the simulation problem into a nonlinear optimization problem then solving the optimization problem.
-
Diagnostic reports that summarize the occurrence of missing values in both estimation(FIT) and simulation(SOLVE) steps have been added to the MODEL procedure. The new REPORTMISSINGS option generates tables that describe which variables in the model and which observations in the DATA= data set contribute missing values within FIT, or SOLVE calculations. The REPORTMISSINGS option produces output that is easier to interpret when debugging model and data specification problems than the ObsUsed table, which often lacks sufficient detail, or the PUT statement, which can produce too much output. The amount of diagnostic information that the REPORTMISSINGS tables include can be limited by using the MAXERRORS= option. The tables that the REPORTMISSINGS option produces can also attribute missing quantities in the model program to missing values of independent variables in the DATA= data set.
-
The ANALYZEDEP= option has been added to the MODEL procedure to provide more information on the nature of misspecification errors in simulations. When the system of equations specified in a SOLVE step does not consistently determine the solve variables, the system is partitioned into those equations that overdetermine, underdetermine, and consistently determine the solve variables. The partitioning of equations and solve variables is performed by using a Dulmage-Mendelsohn (Dulmage and Mendelsohn, 1958) decomposition of the system, which is invariant to the order in which equations and variables are specified. You can display the partitioning of the system graphically by using the BLOCK plot option in the ANALYZEDEP= option.
-
The BLOCK and DETAILS options for visualizing the dependency structure among equations and variables within a model program have been improved. General form equations can now be analyzed and incorporated in the dependency analysis. Also, you can produce a graphical representation of the dependence of equations on solve variables by using the DETAILS option in the ANALYZEDEP= option. The new dependency plot can display the relationship among many more equations and variables than was previously possible by using the DepStructure table. You can also customize the dependency plot to depict a subset of the equations and variables in the model by using the new EQGROUP and VARGROUP statements.
PANEL Procedure
-
The heteroscedasticity- and autocorrelation-consistent (HAC) covariance matrix estimator is supported, which consistently estimates the covariance matrix even when the heteroscedasticity and autocorrelation structure might be unknown or misspecified. Five types of kernel functions—Bartlett, Parzen, quadratic spectral, truncated, and Tukey-Hanning kernels—are supported. The bandwidth parameter can be estimated with the Andrews method, Newey-West method, and sample size based method, or a fixed value for the bandwidth can be provided. The prewhitening feature is also available with the HAC option. The well-known Newey-West estimator is also supported.
QLIM Procedure
-
Heckman Selection Model – Two-Step Estimator. The QLIM procedure now supports Heckman’s two-step estimation method, as an alternative to maximum likelihood estimation of selection models. The standard errors of the second-step OLS estimates are corrected for consistency by default. However, if the uncorrected ones are requested for testing purposes, they are available with the UNCORRECTED option.
-
ODS Graphics plots for Bayesian and frequentist estimation methods. For the frequentist framework, the QLIM procedure can produce a graphical representation of the output that is produced with the OUTPUT statement. For the Bayesian approach, the QLIM procedure can produce the plots of the prior and the posterior predictive analysis.
SASEXCCM Interface Engine
The SASEXCCM interface
engine is now production status for CCM, STK, and IND access. The
TRS access is not supported for this release. The SASEXCCM interface
engine supports Linux X86 (LNX), Linux X64 (LAX), Solaris X64 (SAX),
Solaris SPARC (S64), and both 32-bit Windows (W32) and 64-bit Windows
(WX6).
SASEXFSD Interface Engine
The new SASEXFSD interface
engine enables SAS users to access FactSet data that are provided
by the FactSet FASTFetch Web service. This service provides access
to a number of data libraries from economic and financial data sources
such as Aspect Huntley Fundamentals, Compustat, Dun and Bradstreet
Corporation, FactSet, Ford Equity Research, Reuters, SEDAR, Toyo Keizai,
Value Line, Worldscope, CEIC, EuroStat, Global Insight, IMF International
Financial Statistics, INDB Main Economic Indicators, Markit Economics,
OECD, ONS (UK Office for National Statistics), U.S. Consumer Confidence
Survey, Thomson Analytics Insider Trading, Trucost Environmental,
SIC, and WM/Reuters.
SEVERITY Procedure
-
A new plot, the Q-Q plot, has been added. You can request this plot by specifying the PLOTS=QQPLOT or PLOTS=ALL option in the PROC SEVERITY statement. For a distribution named
dist, the quantile for a given value of the cumulative distribution function (CDF) is computed either by evaluating thedist_QUANTILE function, if it is defined for the distribution, or by inverting thedist_CDF function of the distribution. -
Standard errors and confidence intervals are now available for the empirical distribution function (EDF) estimates. They are written to the OUTCDF= data set. If you specify the PLOTS=CDFPERDIST option, then the lower and upper confidence limits of EDF estimates are plotted in the CDFDistPlot plots. You can specify the confidence level for the confidence interval by specifying the new EDFALPHA= option in the PROC SEVERITY statement. For standard EDF estimators (no censoring or truncation), the standard errors are computed using the normal approximation. For Kaplan-Meier and modified Kaplan-Meier estimators (truncation with one type of censoring), Greenwood’s formula is used. For Turnbull’s estimator (both types of censoring with or without truncation), standard errors are computed from the estimate of the covariance matrix that is computed by inverting the Hessian matrix of Turnbull’s nonparametric log-likelihood. If the Hessian matrix is singular or results in missing values for the standard errors of any of the intervals, then the normal approximation method is used.
-
If you specify the SCALEMODEL statement, then the scale of the distribution depends on the values of regressors. For a given distribution family, each observation implies a different scaled version of the distribution. PROC SEVERITY needs to construct a single representative distribution from all such distributions in order to compute estimates of CDF and the probability density function (PDF) that are comparable across different distribution families. Prior to this release, the representative distribution was constructed as the weighted mixture of distributions implied by all observations. For that method, estimation of CDF or PDF for one observation requires
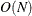 computations, where
computations, where 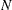 denotes the total number of observations. So estimation
of CDF or PDF for all observations requires
denotes the total number of observations. So estimation
of CDF or PDF for all observations requires 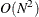 computations, which can dominate the runtime of
PROC SEVERITY even for moderately large values of . Starting with this release, you can specify the
new DFMIXTURE= option in the SCALEMODEL statement to choose one of
four methods to construct the representative mixture distribution.
The prior method is used when you specify DFMIXTURE=FULL option. The
default method is DFMIXTURE=MEAN, which uses a distribution with scale
equal to the mean of scale values. It is significantly faster than the
FULL method. The other two methods construct a mixture of
computations, which can dominate the runtime of
PROC SEVERITY even for moderately large values of . Starting with this release, you can specify the
new DFMIXTURE= option in the SCALEMODEL statement to choose one of
four methods to construct the representative mixture distribution.
The prior method is used when you specify DFMIXTURE=FULL option. The
default method is DFMIXTURE=MEAN, which uses a distribution with scale
equal to the mean of scale values. It is significantly faster than the
FULL method. The other two methods construct a mixture of 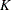 distributions each with one of scale values, which are either the
distributions each with one of scale values, which are either the 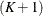 -quantiles from the sample of scale values (DFMIXTURE=QUANTILE) or the scale values
implied by randomly chosen observations (DFMIXTURE=RANDOM).
For
-quantiles from the sample of scale values (DFMIXTURE=QUANTILE) or the scale values
implied by randomly chosen observations (DFMIXTURE=RANDOM).
For 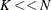 , the QUANTILE and RANDOM methods can be significantly
faster than the FULL method.
, the QUANTILE and RANDOM methods can be significantly
faster than the FULL method.
-
The DIST statement now supports two more keywords in addition to the _PREDEFINED_ keyword. If you specify the _USER_ keyword, then PROC SEVERITY includes all the custom distributions that you have defined in the libraries specified in the CMPLIB= system option. The _ALL_ keyword includes all the predefined distributions and your custom distributions. It also includes the Tweedie and scaled-Tweedie distributions that are not included by the _PREDEFINED_ keyword. The DIST statement also has two new options, LISTONLY and VALIDATEONLY. The LISTONLY option lists the names of the distributions that you have specified in the DIST statement and the distributions implied by any keywords that you specify. This option is especially useful in conjunction with the keywords. The VALIDATEONLY option validates all the specified distributions and writes the distribution’s information to the OUTMODELIFO= data set and a new ODS table, DistributionInfo. This option is especially useful in conjunction with your custom distributions, because it enables you to check whether the definitions of the functions and subroutines that make up your distribution satisfy PROC SEVERITY’s requirements.
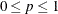 and
and 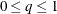 —can be specified.
—can be specified.
TCOUNTREG Procedure (Experimental)
The experimental TCOUNTREG
procedure is a transitional version of the COUNTREG procedure. The
following features have been added to the TCOUNTREG procedure:
X12 Procedure
The following features
have been added to the X12 procedure:
-
The PICKMDL statement. The PICKMDL statement causes the X12 procedure to automatically select a regARIMA model from a list of candidate models defined by the user in the MDLINFOIN= data set. The METHOD= option in the PICKMDL statement controls how the model selection is performed. The selected regARIMA model then extends the time series prior to performing the X-12-ARIMA seasonal adjustment. The PICKMDL statement is experimental for this release.
-
The SEATSDECOMP statement. The SEATSDECOMP statement first computes the B1 series by using the X-12-ARIMA method and then performs a seasonal adjustment of the B1 series by using the SEATS decomposition method. SEATS is a polynomial-based seasonal decomposition method developed by Gomez and Maravall (1997a, 1997b). You can write the resulting components to a data set by specifying the OUT= option in the SEATSDECOMP statement. The SEATSDECOMP statement is experimental in this release.
-
The AICTEST option has been added as a general option to the REGRESSION statement. The AICTEST option enables you to specify a regression effect, but the effect is not included in the regARIMA model unless the results of an AIC test determine that the effect should be included in the model. Thus, the AICTEST option can be used to automatically select regressors for the regARIMA model.