Partition Data Task
About the Partition Data Task
A partition is all or part of a logical file. The Partition Data task enables you
to create up to four partitions created by randomly sampling the input data. Partitions
can be used to develop a model. In this case, you want to train the model on part
of the data and reserve some of the data for testing. Using the Partition Data task,
you can save all the partitions to one output data set or save each partition in a separate data set.
Example: Partitioning the SASHELP.CLASSFIT Data Set
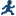
The new _Partition_ variable in the output data set specifies the partition (either
Train or Test) for the observation. For example, the data for Joyce is in the Train partition. The data for Louise is
in the Test partition. This example does not specify a random seed. As a result, the task randomly assigns 50% of the observations to the Test partition and 30% of the observations to the Train partition. If you
run this example again, you might see slightly different results.
Creating a Partitioned Data Set
To run the Partition
Data task, you must assign values to the Proportion of
cases option for each partition.
|
Role
|
Description
|
|---|---|
|
Roles
|
|
|
Stratify
by
|
specifies separate partitions
for each combination of levels. You can specify a maximum of two variables
to this role.
|
|
Partition Data
|
|
|
Number of
partitions
|
specifies the number
of partitions. You can choose to create one, two, three, or four partitions.
|
|
Proportion
of cases for partition n
|
specifies the proportion
of cases for each partition. The sum of all the partition proportions
must be less than or equal to 1.
|
|
Output Data Set
|
|
|
Partition
data sets
|
specifies whether to include all partitions in one data set or put each partition
in a separate data set. You can specify a unique name for each
output data set.
|
|
Include
non-sampled observations
|
specifies whether to include non-sampled observations in the output data set.
Note: This option applies only
if you are saving all the partitions to one data set.
|
|
Variable
name for partitioned values
|
specifies the name for the variable that contains the partitioned values.
Note: This option applies only
if you are saving all the partitions to one data set.
|
|
ID value
for partition n data
|
specifies the identifier
to use for each value in a partition.
Note: This option applies only
if you are saving all the partitions to one data set.
|
|
Show Output Data
|
|
|
Show output
data
|
specifies whether to include the output data in the results that appear on the Results tab. You can include all or a subset of the output data. The task always creates the output data set that appears on the
Output Data tab. This data set is also saved to the specified location.
|
Copyright © SAS Institute Inc. All rights reserved.