Rapid Predictive Modeler
About the Rapid Predictive Modeler
Overview of the Rapid Predictive Modeler
SAS Rapid Predictive Modeler is designed to build models for the following types of data mining classification and regression problems:
-
classification models that predict the value of a discrete variable. Some examples are classification models that predict the value of a variable, such as True or False; Purchase or Decline; High, Medium, or Low; and Churn or Continues.
-
regression models that predict the value of a continuous variable. Some examples are regression models that might predict amounts such as revenue, sales, or success rate by using continuous values.
To create a model by using the SAS Rapid Predictive Modeler, you must supply a data set, where every row contains a set of independent predictor variables (known as inputs)
and at least one dependent variable (known as a target). The SAS Rapid Predictive Modeler decides whether variables are
continuous or categorical, and chooses the input variables that should be included
in the model.
Your model can be saved
as SAS code and then deployed in a SAS environment. You can use the
SAS model code to score new data, and then use the results to make
more informed business decisions. This process is called model scoring.
For example, you can use scored data to decide which customers to
select for churn, or to detect transactions that might be fraudulent.
Sampling Strategies for the SAS Rapid Predictive Modeler
The SAS Rapid Predictive
Modeler uses a composite sampling approach. The number of observations
that are included in the data sample depend on these factors:
-
number of input variables
-
total number of observations in the data source
-
whether the data contains rare event targets
-
number of events in the data
Here are the guidelines
that the SAS Rapid Predictive Modeler uses to determine the number
of observations that are processed:
|
Number of Input Variables
|
Number of Observations
Processed
|
|---|---|
|
<100
|
80,000
|
|
100–200
|
40,000
|
|
>200
|
20,000
|
To understand the conditions
in the following table, here are some key points:
-
The number of observations being processed is determined by the number of input variables. See the preceding table.
-
In predictive modeling, if you are modeling a binary target, your target variable has an event level of 0 or 1. The event level could also be formatted to use No or Yes. Here is an example. A bank is trying to predict whether a customer will have bad credit. In the training data, each customer with bad credit is set to Yes, which means an event occurred for that customer. Each customer with good credit is considered a non-event.
|
Condition
|
Rare Event
|
|
|---|---|---|
|
Yes
|
No
|
|
|
total number of observations < number of observations being processed
OR
total number of events < (0.10*number of observations being processed)
|
Sample the data so that
there is a 10:1 ratio of non-events to events.
|
no sampling
|
|
total number of events > (0.10*number of observations being processed)
|
Sample the following
proportion of the rare events:
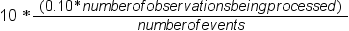 |
stratified sampling
|
Organizing Data for the SAS Rapid Predictive Modeler
Before you can build
a model, you need input data that represents historical events and
characteristics that can be used for prediction. You also need target
data that represents the event or value that you want to predict.
In many cases, the input data is derived from one time period and
the target data is derived from a later time period. The combined
input and target data that you use to develop your model is called training
data.
For example, you might
mine last year's sales receipts to predict next year's expected revenue
or to predict which customers will respond to a special offer. Using
historical data from past events to predict performance on future
events is called model training.
For the best model results, your model training data should contain a large number
of observations stored as rows of data. For example, many retail customer models use input data that
has tens of thousands of observations.
If your target variable contains a rare event (for example, an offer that perhaps
only 1% of your customers will respond to), you must ensure that your training data
contains a significant number of these customers in your data set. You might want to oversample your training data to make sure you select all customers
who accepted the offer, and provide an equal number of customers who did not accept.
Oversampling makes it easier for a model with a rare event target to find a stable
solution.
When you perform oversampling to boost rare event occurrences in your training data,
you artificially inflate the occurrence of targeted events in your training data relative
to the natural population. To compensate for the difference between the training data
and the population data, the SAS Rapid Predictive Modeler provides you with a prior probability setting. Prior probability settings specify
the true proportional frequencies of the targeted event in the population data.
The data that you mine using the SAS Rapid Predictive Modeler should be organized
into rows (observations) and columns (variables). One of the columns should represent
a target variable.
Consider the following
example:
|
Name
|
Age
|
Gender
|
Income
|
Treatment
|
Purchase
|
|---|---|---|---|---|---|
|
Ricardo
|
29
|
M
|
33000
|
Y
|
Y
|
|
Susan
|
35
|
F
|
51000
|
Y
|
N
|
|
Jeremy
|
49
|
M
|
110000
|
N
|
Y
|
Name
a column that contains ID values for each observation. The SAS Rapid Predictive Modeler does not process ID variable columns for analytical
content.
Age, Gender, Income, and Treatment
input columns that are used by the SAS Rapid Predictive Modeler.
Purchase
a target column.
When you configure your table of input data, you can also designate a frequency column.
The values in the frequency column are nonnegative integers and must sum to 1.
By using the Variables
to exclude from the model role, you can also select columns that you want the SAS Rapid Predictive Modeler
to ignore during your analysis.
Training data always
requires input and target variable values. Data that you use for scoring
requires only input variable values; a target column is optional.
When the model is used to make predictions from new data, the target
column is not required. When the model is used to monitor effectiveness,
the target column is required. Data that you use for scoring also
typically includes an ID column.
Reserved Prefixes for Variables
SAS Enterprise Miner uses several default prefixes for generated nodes. If one of the variables in your input data uses any of these prefixes, you might
see an error in the SAS log. If any of the variables in your input data set use these prefixes, it is recommended that you change the name of the variable in
the input data set.
Assigning Data to Roles
To run the Rapid Predictive
Modeler, you must assign a variable to the Dependent variable role.
|
Role
|
Description
|
|---|---|
|
Roles
|
|
|
Dependent
variable
|
specifies the value that you want to predict or classify. The dependent variable is also known as the target variable.
|
|
Decisions
and Priors
|
specifies this information:
|
|
Additional Roles
|
|
|
Variables
to exclude from the model
|
specifies the variables
that you do not want to include in your analysis.
|
|
Frequency
count
|
specifies the variable
to use to represent the frequency value. The data is treated as if
each case is replicated as many times as the value of the frequency
variable.
|
|
ID variables
|
specifies variables
that are useful for reporting and scoring selection functions. These
variables are not included in the analysis.
|
Setting the Model Options
Choosing a Model
With these options, you can specify the complexity level of the model that you want
to build. The modeling methods are in a hierarchy: the intermediate method includes basic and intermediate models,
and the advanced method includes basic, intermediate, and advanced models.
The models that you
create using the basic method will probably run faster than the models
that you create using the intermediate method, but the basic method
also might create a less accurate model. The same is often true when
you compare the models that you create with the intermediate and advanced
methods.
SAS Enterprise Miner modeling functions are executed when you run the SAS Rapid Predictive
Modeler. The modeling functions that the software runs depend on the selected modeling method.
Modeling Methods
You can choose from
these modeling methods:
Basic
The basic method samples the data only if you have a rare target event, and then partitions
the data by using the target as a stratification variable. Next, the basic method performs a one-level variable selection step. The
input variables that were selected are then binned according to the strength of their
relationship to the target and passed to a forward stepwise regression model.
Intermediate
The intermediate method is an extension of the basic method. Several variable selection
techniques are performed and then followed by multiple variable transformations. A decision tree, a regression model, and a logistic regression are used as modeling techniques. Variable interactions are represented using the
node variable that was exported from a decision tree. The intermediate method also runs
the basic method, and then chooses the best performing model.
Advanced
The advanced method is an extension of the intermediate method and includes a neural
network model, an advanced regression analysis, and ensemble models. The advanced method also runs the intermediate and basic methods,
and then chooses the best performing model.
Understanding the Models for the SAS Rapid Predictive Modeler
The SAS Rapid Predictive Modeler provides you with basic, intermediate, and advanced
models. The models increase in
sophistication and complexity.
-
The basic model is a simple regression analysis.
-
The intermediate model includes a more sophisticated analysis, plus the analysis from the basic model, and chooses the better model.
-
The advanced model includes an even more sophisticated analysis, plus the analyses from the basic and intermediate models, and chooses the best model.
Basic
The basic model performs
a series of three data mining operations.
-
Variable Selection: The basic model chooses the top 100 variables for modeling.
-
Transformation: The basic model performs an Optimal Binning transformation on the top 100 variables selected for modeling. The Optimal Binning transformation compensates for missing variable values, so missing value imputation is not performed.
-
Modeling: The basic model uses a forward regression model. The forward regression model chooses variables one at a time in a stepwise process. The stepwise process adds one variable at a time to the linear equation until the variable contributions are insignificant. The forward regression model seeks to exclude variables with no predictive ability (or variables that are highly correlated with other predictor variables) from the analytic analysis.
Intermediate
The intermediate model
performs a series of seven data mining operations.
-
Variable Selection: The intermediate model chooses the top 200 variables for modeling.
-
Transformation: The intermediate model performs a best power transformation on the 200 variables that were selected for modeling. The best power transformations are a subset of the general class of transformations that are known as Box-Cox transformations. The best power transformation evaluates a subset of exponential power transformations, and then chooses the transformation that has the best results for the specified criterion.
-
Imputation: The intermediate model performs an imputation to replace missing variables with the average variable values. The imputation operation also creates indicator variables that enable observations that contain imputed variable values to be identified.
-
Variable Selection: The intermediate model uses the chi-square and R-square criteria tests to remove variables that are not related to the target variable.
-
Union of Variable Selection Techniques: The intermediate model merges the set of variables that were selected by the chi-square and R-square criteria tests.
-
Modeling: The intermediate model submits the training data to three competing model algorithms. The models are a decision tree, a logistic regression, and a stepwise regression. In the case of the logistic regression model, the training data is first submitted to a decision tree that creates a NODE_ID variable that is passed as input to the regression model. The NODE_ID variable is created to enable variable interaction models.
-
Champion Model Selection: The intermediate model performs an analytic assessment of the predictive or classification performance of the competing models. The model that demonstrates the best predictive or classification performance is selected to perform the modeling analysis. The intermediate model for champion model selection evaluates the performance of not only the intermediate models, but also the basic models.
After the SAS Rapid Predictive Modeler chooses the intermediate champion model, it
compares the predictive performance of
the intermediate champion model to the basic model, and then chooses the better model
as the result.
Advanced
The advanced model
performs a series of seven data mining operations.
-
Variable Selection: The advanced model chooses the top 400 variables for modeling.
-
Transformation: The advanced model performs the multiple transformation algorithm on the 400 variables that were selected for modeling. The multiple transformation operation creates several variable transformations that are intended for use in later variable selections. Multiple transformations result in an increase in the number of input variables. Because of the increase in input variables, SAS Rapid Predictive Modeler selects the best 400 input variables from the output that was generated by the multiple transformation algorithm.
-
Imputation: The advanced model performs an imputation to replace missing variables with the average variable values. The imputation operation also creates indicator variables that enable the user to identify observations that contain imputed variable values.
-
Variable Selection: The advanced model uses the chi-square and R-square criteria tests to remove variables that are not related to the target variable. AOV16 variables are created during the R-square analysis.
-
Union of Variable Selection Techniques: The advanced model merges the set of variables that were selected by the chi-square and R-square criteria tests.
-
Modeling: The advanced model submits the training data to four competing model algorithms. The models are a decision tree model, a neural network model, a backward regression model, and an ensemble model. The neural network model conducts limited searches in order to find an optimal feed-forward network. Backward regression is a linear regression model that eliminates variables by removing one variable at a time until the R-squared scores drop significantly. The ensemble model creates new models by combining the posterior probabilities (for class targets) or the predicted values (for interval targets) from multiple predecessor input models. The new ensemble model is then used to score new data. The ensemble model that you use in the advanced model is created from the output of the basic model, the champion model from the intermediate model, and the champion model from the advanced model.
-
Champion Model Selection: The advanced model performs an analytic assessment of the predictive or classification performance of the competing decision tree, neural, and regression models. The model that demonstrates the best predictive or classification performance is then used as an input, along with the champion model from the basic and intermediate models, to create an ensemble model. Then the newly created advanced ensemble model, decision tree model, neural model, and backward regression model are analytically compared to select the best model from the sample space of all basic, intermediate, and advanced champion models.
After the SAS Rapid Predictive Modeler selects a champion model, it runs and compares
the predictive performance of the
advanced model to the champion models for the intermediate and basic models, and then
chooses the best performing champion model as the result.
Setting the Report Options
About the Reports
The reports identify significant terms in the model and generate common business graphics,
such as lift charts. The results include statistics for training and validation data.
The SAS Rapid Predictive Modeler process divides the input data into training data
and validation data. Training data
is used to compute the parameters for each model, resulting in the training fit statistics. Validation data is then scored with each model, resulting in the validation fit
statistics. The validation fit statistics are used to compare models and detect overfitting.
If the training statistics are significantly better than the validation statistics,
then you would suspect overfitting, which occurs when the model is trained to detect
random signals in the data. Models with the best validation statistics are generally
preferred.
The SAS Rapid Predictive Modeler automatically generates a concise set of core reports
that provide a summary of the
data source and variables that were used for modeling, a ranking of the important predictor variables, multiple fit statistics that evaluate the accuracy
of the model, and a model scorecard.
About the Standard Reports for the SAS Rapid Predictive Modeler
Here are the standard
reports that are automatically generated by the SAS Rapid Predictive
Modeler:
Gains chart
Gains chart plots are available only for models that have class target variables. This chart shows
percentiles of the data ranked by predicted value. Lift is a measure of the ratio of the number of target events that the model identified,
compared to the number of target events that were found by random selection.
Receiver Operating Characteristic plot (ROC)
The Receiver Operating Characteristic plot shows the maximum predictive power of a
model for the entire sample (rather than
for a single decile). The data is plotted as sensitivity versus (1 – specificity). The separation between
the model curve and the diagonal line (which represents a random selection model) is called the Kolmogorov-Smirnov (KS) value. Higher KS values represent more powerful
models.
Scorecard
The results include a scorecard so that the model's characteristics can be interpreted
for business purposes. When the software builds a scorecard, each interval variable
is binned into distinct ranges of values. Then, each variable is ranked by model importance
and scaled to a maximum of 1,000 points. The distinct value for each variable then receives a portion of the scaled point total.
Project information
The project information
shows which user created the model, when the model was created, and
where the model's component files are stored.
Setting the Output Options
|
Option
|
Description
|
|---|---|
|
Output Data Set
|
|
|
Save Enterprise
Miner project data
|
specifies whether to save the SAS Enterprise Miner data from this task. A model from
the SAS Rapid Predictive Modeler is an example of a SAS Enterprise Miner project.
When you save SAS Enterprise Miner
data, you can use the SAS Enterprise Miner interface to open and edit the model that
you created using the SAS Rapid Predictive Modeler. In SAS Enterprise Miner, you can
save and export your analysis for use outside of SAS Enterprise Miner, and register
your model with a SAS Metadata Repository.
|
|
Export scoring
code
|
saves the scoring code from this task to the specified location. You can then run this code to score other
sets of data in other SAS products.
|
|
Score input
data set
|
specifies the name of the output data set that contains the scored values. The values in the input data set are scored by the
model that the SAS Rapid Predictive Modeler builds.
|
Copyright © SAS Institute Inc. All rights reserved.