Predictive Regression Modeling
About the Predictive Regression Modeling
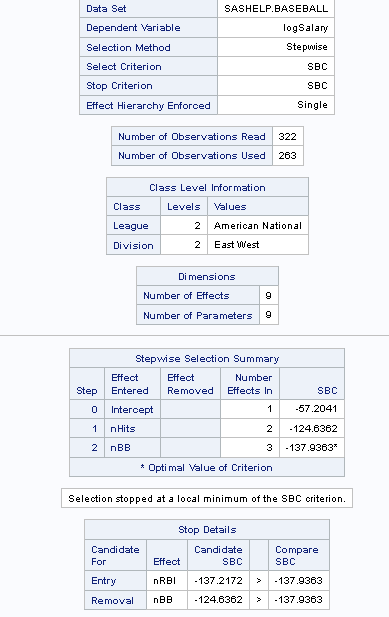
The task is predictive
in that it selects the most influential effects based on observed
data. This task enables you to logically partition your data into
disjoint subsets for model training, validation, and testing. The
Predictive Regression Modeling task focuses on the standard independently
and identically distributed general linear model for univariate responses
and offers great flexibility and insight into the model selection
algorithm. This task can also create a scored data set. The results
for this task make it easy to explore the selected model in more detail
with other tasks, such as the Linear Regression task.

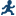
Assigning Data to Roles
To run the Predictive
Regression Modeling task, you must assign a column to the Dependent
variable role and a column to the Classifcation
variables role or the Continuous variables role.
Building a Model
Create a Nested Effect
Nested effects are specified
by following a main effect or crossed effect with a classification
variable or list of classification variables enclosed in parentheses.
The main effect or crossed effect is nested within the effects listed
in parentheses. Here are examples of nested effects: B(A), C(B*A),
D*E(C*B*A). In this example, B(A) is read "B nested within A."
Create N-Way Factorial
For example, if you
select the Height, Weight, and Age variables and then specify the
value of N as 2, when you click N-way Factorial,
these model effects are created: Age, Height, Weight, Age*Height,
Age*Weight, and Height*Weight. If N is set to a value greater than
the number of variables in the model, N is effectively set to the
number of variables.
Selecting a Model
Setting the Options for the Final Model
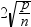
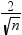
Copyright © SAS Institute Inc. All rights reserved.