Example: Partitioning the SASHELP.CLASSFIT Data Set
-
TipIf the data set is not available from the drop-down list, click
 . In the Choose a Table window,
expand the library that contains the data set that you want to use.
Select the data set for the example and click OK.
The selected data set should now appear in the drop-down list.
. In the Choose a Table window,
expand the library that contains the data set that you want to use.
Select the data set for the example and click OK.
The selected data set should now appear in the drop-down list.
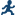

The new _Partition_
variable in the output data set specifies the partition (either Train
or Test) for the observation. For example, the data for Joyce is in
the Test partition. The data for Janet is in the Test partition. This
example does not specify a random seed. As a result, the task randomly
assigns 50% of the observations to the Test partition and 30% of the
observations to the Train partition. If you run this example again,
you might see slightly different results.
Copyright © SAS Institute Inc. All rights reserved.