Truncated Regression
Example: Truncated Regression
To create this example:
-
Create the Work.Cigar data set. For more information, see CIGAR Data Set.
-
TipIf the data set is not available from the drop-down list, click
 . In the Choose a Table window,
expand the library that contains the data set that you want to use.
Select the data set for the example and click OK.
The selected data set should now appear in the drop-down list.
. In the Choose a Table window,
expand the library that contains the data set that you want to use.
Select the data set for the example and click OK.
The selected data set should now appear in the drop-down list.
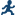
Assigning Data to Roles
To perform a truncated
regression analysis, you must assign an input data set. To filter the input data
source, click  .
.
.
You also must assign
a variable to the Dependent variable role.
|
Role
|
Description
|
|---|---|
|
Roles
|
|
|
Dependent
variable
|
specifies the numeric
variable for the analysis.
|
|
Continuous
variables
|
specifies
the independent covariates (regressors) for the regression model.
If you do not specify a continuous variable, the task fits a model
that contains only an intercept.
|
|
Categorical
variables
|
specifies
the classification variables. The task generates dummy variables for
each level of the categorical variable.
|
|
Additional Roles
|
|
|
Group analysis
by
|
enables you to obtain separate
analyses of observations for each unique group.
|
Setting the Model Options
To create a truncated
regression model:
-
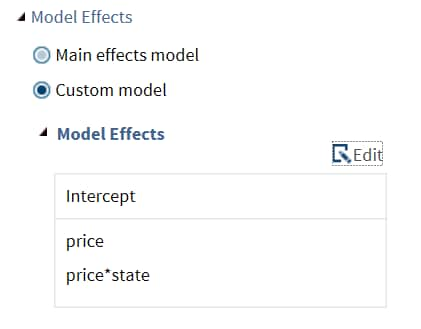
You can display the main effects model or create a custom model. To create a custom model, select the Custom Model option, and then click Edit. The Model Effects Builder opens. All continuous variables and categorical variables are listed in the Variables pane.
-
To create a main effect, select the variable in the Variables pane, and then click Add.
-
To create a crossed effect, select the variables in the Variables pane. (You can use Ctrl to select multiple variables.) Then click Cross.
When you finish, click OK. The effects that you specified now appear on the Model tab.Here is an example of model effects on the Model tab. -
Setting the Options
|
Option Name
|
Description
|
|---|---|
|
Methods
|
|
|
Covariance
matrix estimator
|
specifies the method
to calculate the covariance matrix of parameter estimates.
You can use the default
value, or you can choose from these covariance types:
|
|
Optimization
|
|
|
Method
|
specifies the optimization
method to use.
|
|
Maximum
number of iterations
|
specifies the maximum
number of iterations in the optimization process. You can use the
default value, or you can specify a custom value.
|
|
Statistics
|
|
|
Select the statistics
to display in the results.
Here are the additional
statistics that you can include in the results:
|
|
Copyright © SAS Institute Inc. All rights reserved.