Working with Decision Trees
About Decision Trees
A decision tree uses
the values of one or more predictor data items to predict the values
of a target data item. A decision tree displays a series of nodes
as a tree, where the top node is the target data item, and each branch
of the tree represents a split in the values of a predictor data item.
Decision trees are also known as classification and regression trees.
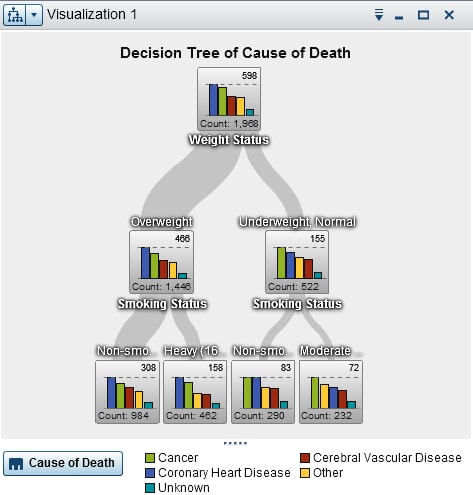
Each branch of the tree
displays the name of the predictor for the branch at the top of the
split. The thickness of the branch indicates the number of values
that are associated with each node. The predictor values for each
node are displayed above the node.
Each node in the tree
displays the data for the node either as a histogram (if the target
contains continuous data) or as a bar chart (if the target contains
discrete data). The histogram or bar chart in each node displays the
values of the target data item that are selected by the splits in
the tree. The number at the top right of the node indicates the greatest
value or frequency for the bar chart or histogram. At the bottom of
each node, the total number of data values (count) for the node is
displayed.
Decision trees in SAS
Visual Analytics use a modified version of the C4.5 algorithm.
The details table for
a decision tree contains two additional data columns, Node ID and
Parent ID. Node ID specifies a unique value for each node in the tree.
Parent ID specifies the ID of the parent node.
Data Roles for a Decision Tree
The basic data roles
for a decision tree are:
Target
specifies the target
for the decision tree. You can specify any category or measure. The
decision tree attempts to predict the values of the target data item.
The bar chart or histogram inside each node of the tree displays the
frequency of values for the target data item.
Predictors
specifies predictors
for the decision tree. You can specify one or more categories or measures
as predictors. The values of predictor data items are displayed above
the nodes in the tree. The order of the data items in the Predictors list
does not affect the tree.
Note: If a predictor does not contribute
to the predictive accuracy of the tree, then it is not used in the
tree.
Specify Properties for a Decision Tree
On the Properties tab,
you can specify the following options:
Name
specifies the name
of the visualization.
Title
specifies the title
that appears above the graph.
Note: The Title option
is disabled if you select Generate graph title.
Generate graph title
specifies that the
graph title is generated automatically based on the data items in
the visualization.
Include missing
specifies whether missing
values are included in the tree.
Frequency
specifies whether the
frequency value for each node is displayed as a count (Count)
or as a percentage (Percent).
Note: The frequency values are
based on the data that is shown in the visualization (after filters
and other data selections have been applied).
Growth strategy
specifies the parameters
that are used to create the decision tree. Select one of the following
values:
Basic
specifies a simple
tree with a maximum of two branches per split and a maximum of six
levels. For
details, see
Parameter Values for the Basic and Advanced Growth Strategies.
Advanced
specifies a complex
tree with a maximum of four branches per split and a maximum of six
levels. For
details, see
Parameter Values for the Basic and Advanced Growth Strategies.
Expert
enables you to select
the values for each of the expert parameters.
If you select Expert as
the value for Growth strategy, then the following
additional options appear:
Maximum branches
specifies the maximum
number of branches for each node split.
Maximum levels
specifies the maximum
number of levels in the tree.
Leaf size
specifies the minimum
number of values (count) for each node.
Target bins
specifies the number
of bins that are used for the target data item.
Note: This option has no effect
if the target data item contains discrete data.
Predictor bins
specifies the number
of bins that are used for predictor data items.
Note: This option has no effect
if the predictor data items contain discrete data.
Pruning
specifies the level
of pruning that is applied to the tree. Pruning removes leaves and
branches that contribute the least to the predictive accuracy of the
tree. A more Lenient pruning value specifies
that fewer leaves and branches are removed from the tree. A more Aggressive pruning
value specifies that more leaves and branches are removed from the
tree.
Reuse predictors
specifies that predictors
can be used more than once in the tree.
Explore a Node as a New Visualization
For each node in the
tree, you can explore the data values as a new histogram or bar chart
visualization. To create a new visualization for a node, right-click
on the node, and then select Create Visualization from
Node. A new visualization appears.
Note: If you create a visualization
from a node that displays a histogram, then the new histogram might
have visual differences from the histogram that is displayed in the
decision tree. For example, the bins and the extent of data on the
X axis might be different. However, the two histograms use exactly
the same data.
Calculate a Data Item from a Decision Tree
You can create a calculated
data item to represent the results of a decision tree. The calculated
data item creates values that correspond to the node IDs that can
be seen in the details table for the decision tree.
You can use the calculated
data item in filters to select the values for a decision tree node
in other types of visualizations.

Zoom a Decision Tree
You can zoom a decision
tree by using either of the following controls:
-
in the overview, select the part of the decision tree that you want to view
-
scroll the mouse wheel over the visualization to zoom in or out at the location of the cursor
Note: If the target contains discrete
data, and you zoom out on the decision tree, then each node displays
a single bar for the greatest value in that node.
When you have zoomed
in on a decision tree and scroll bars are displayed, you can reposition
the decision tree by holding down the Shift and Alt keys and dragging it.
Copyright © SAS Institute Inc. All rights reserved.