About Adding Data to Co-located Storage
Data Output for Co-located Storage
The unique value of SAS Visual Analytics Administrator
is that it enables administrators to add data to a data provider that
is co-located with the SAS LASR Analytic Server. SAS Visual Analytics
Hadoop is a co-located data provider that is available from SAS. In
this case, the Hadoop Distributed File System (HDFS) is used for data
output. The purpose of adding the data to a co-located data provider
is that the server can read data in parallel at very impressive rates
from a co-located data provider.
Output to SAS Visual Analytics Hadoop
In addition to the performance
advantage of using co-located data, when SAS Visual Analytics Hadoop
is used, it provides data redundancy. By default, two copies of the
data are stored in HDFS. If a machine in the cluster becomes unavailable,
another machine in the cluster retrieves the data from a redundant
block and loads the data into memory.
SAS Visual Analytics Administrator
distributes blocks evenly to the machines in the cluster so that all
the machines acting as the server have an even workload. The block
size is also optimized based on the number of machines in the cluster
and the size of the data that is being stored. Before the data is
transferred to HDFS, SAS software determines the number of machines
in the cluster, row length, and the number of rows in the data. Using
this information, SAS software calculates an optimal block size to
provide an even distribution of data. However, the block size is bounded
by a minimum size of 1 KB and a maximum size of 64 MB.
Registered Tables
Add to HDFS Option
The Add
Table window is launched by selecting the Add
to HDFS option for a table within the folder tree in
the navigation pane.
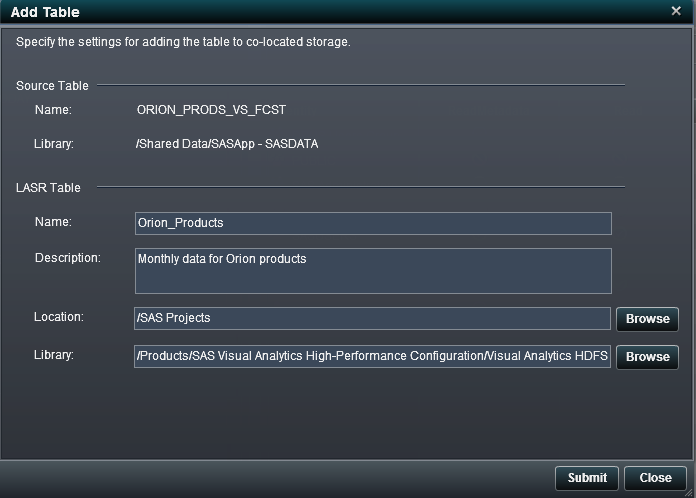
When the co-located
data provider is SAS High-Performance Deployment of Hadoop, the following options
are available in the Add Table window:
Copyright © SAS Institute Inc. All rights reserved.