Viewing Block Information
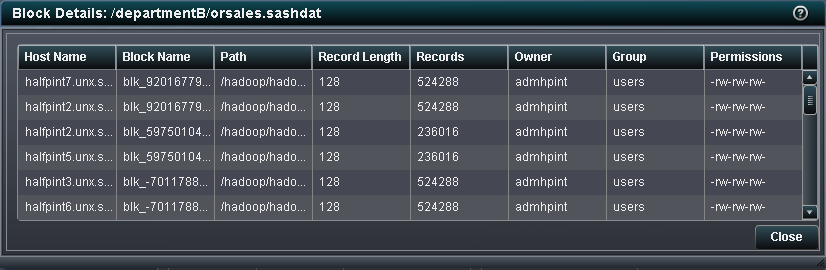
View Block Details

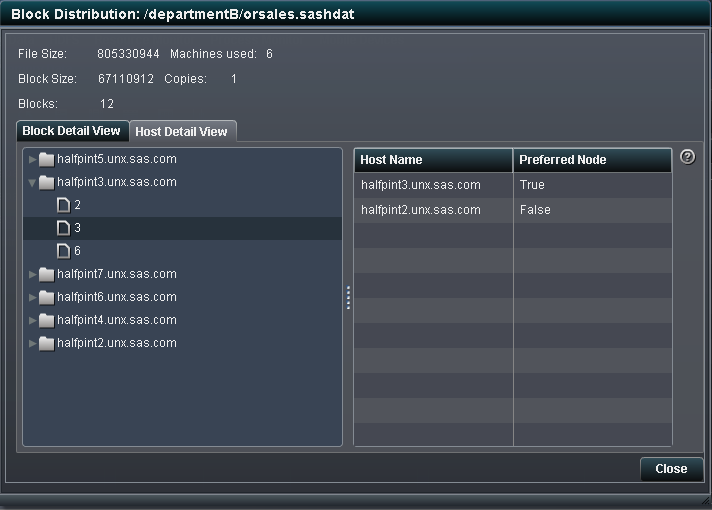
View Block Distribution
The files added to HDFS
are stored as blocks. One block is the preferred block, and additional
copies of the blocks are used to provide data redundancy. The Block
Distribution dialog box offers two ways to view this
information. The Block Detail View tab enables
you to select a block number and view the host names that store the
original or redundant blocks. The Node Detail View enables
you to select a host name and view the block numbers that are stored
on the machine.
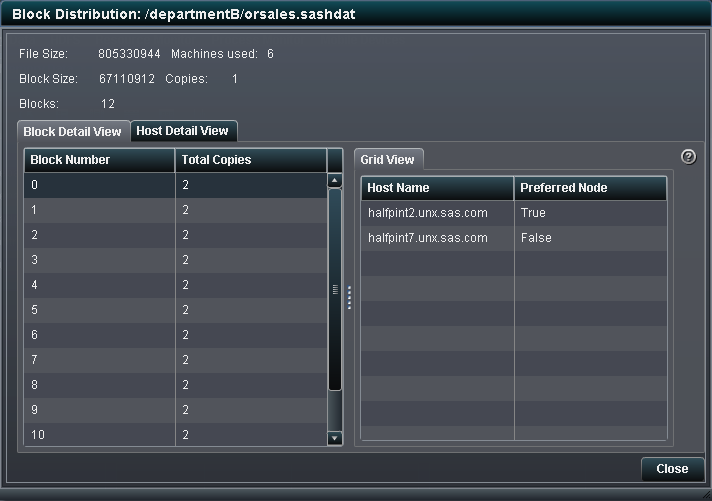
On the Block
Detail View tab, you can select a block number to view
how many copies of the block exist and the host names for the machines
that store the blocks. The value in the Total Copies column
equals the number of redundant copies of the block plus the original
block. You can select the column heading to sort the rows. In an ideal
distribution, the number of total copies is equal for all blocks.
On the Node
Detail View tab, you can expand a host name node and
then view the block numbers that are stored on that machine. When
you select the block number, this host name and any additional machines
with copies of the block are identified in the host name list. The
following display shows an example: