Using the Text Parsing Node
This example shows you
how to use the Text Parsing node to identify
terms and their instances in a data set that contains text. This example
assumes that SAS Enterprise Miner is running, and that a diagram workspace
has been opened in a project. For information about creating a project
and a diagram, see Setting Up Your Project.
-
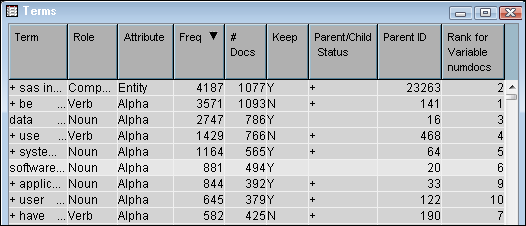
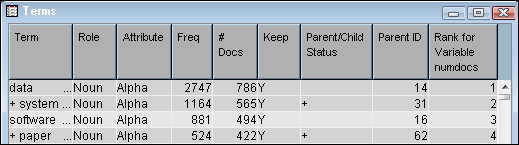
Sort the terms in the Terms table by frequency, and then select the term “software.” As the Terms table illustrates, the term “software” is a noun that occurs in 494 documents in the ABSTRACT data source, and appears a total number of 881 times.
-
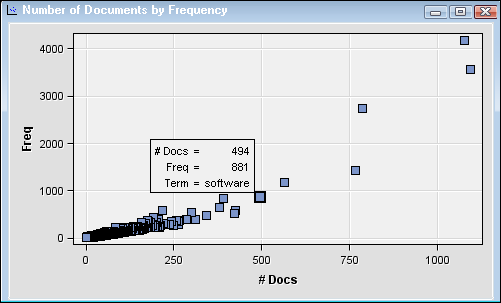
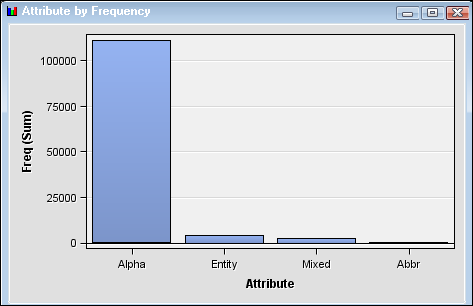
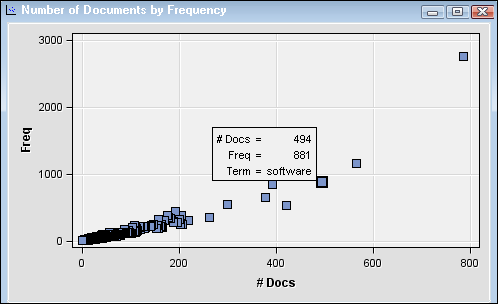
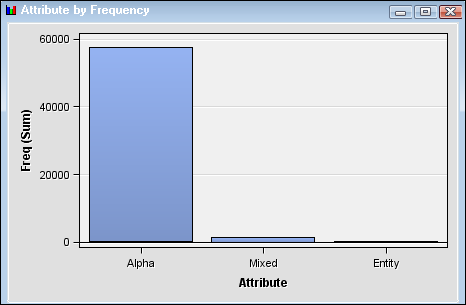
Select the Number of Documents by Frequency plot, and position the cursor over the highlighted point for information about the term “software.”The Attribute by Frequency chart shows that
Alphahas the highest frequency among attributes in the document collection. -
Return to the Terms table, and notice that the term “software” is kept in the text parsing analysis. This is illustrated by the value of
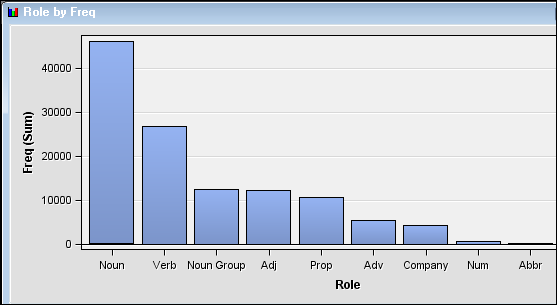
Yin the Keep column. Notice that not all terms are kept when you run the Text Parsing node with default settings.The Text Parsing node not only enables you to gather statistical data about the terms in a document collection. It also enables you to modify your output set of parsed terms by dropping terms that are a certain part of speech, type of entity, or attribute. Scroll down the list of terms in the Terms table and notice that many of the terms with a role other thanNounare kept. Assume that you want to limit your text parsing results to terms with a role ofNoun. -
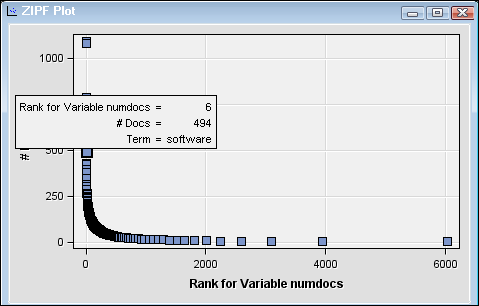
Right-click the Text Parsing node and select Run. Click Yes in the Confirmation dialog box that appears. Select Results in the Run Status dialog box when the node has finished running. Notice that the term “software” has a higher rank among terms with a role of just “noun” or “noun group” than it did when other roles were included. If you scroll down in the Terms table, you can see that just terms with a
NounorNoun Grouprole are included.