To set the Text Miner node properties:
-
Select
the
Text Mining tab on the toolbar and drag
and drop a Text Miner node into the diagram workspace. Connect the
Data Partition node to the Text Miner node.
-
Select the Text Miner
node to view its properties. Details about the node appear in the
Properties panel. Set the following Parse properties:
-
Set
Terms in Single
Document to
Yes to include all
terms that occur only in a single document.
-
Set
Different Parts
of Speech to
No. For the VAERS
data, this setting offers a more compact set of terms.
-
Click the

button for the Synonyms property. The Select a SAS
Table window opens. Select
No data set to be specified. Click
OK.
-
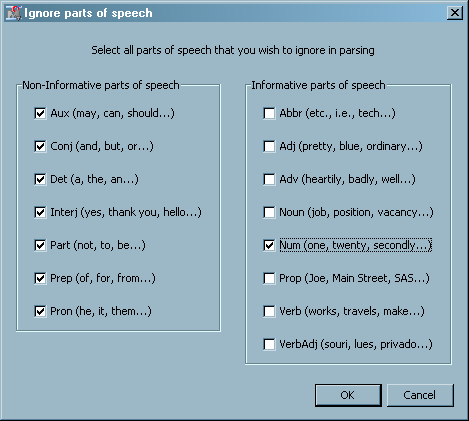
Click the
button for the Ignore Parts of Speech property, and
select the following items, which represent parts of speech:
Any terms with the
parts of speech that you select in the Ignore parts of speech dialog
box are ignored during parsing. The selections indicated here ensure
that the analysis ignores low-content words such as prepositions and
determiners.
-
Set
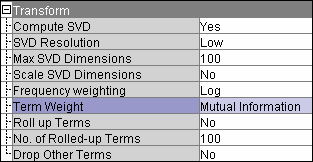
Term Weight to
Mutual Information so that terms will be differentially weighted when they correspond
to serious reactions.
-
Set the
following Cluster properties:
-
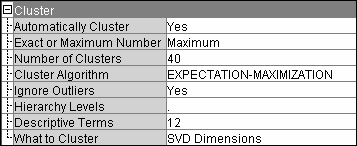
Set
Automatically Cluster to
Yes to answer the question: "What are
some categories of reactions that people are experiencing?" You want
to categorize these adverse events.
-
Set
Descriptive Terms to
12 to ease cluster labeling.
-
Set
Ignore Outliers to
Yes.
-
Right-click
the Text Miner node in the diagram workspace, and select
Run.
-
Click
Yes in the Confirmation dialog box when you are prompted
with a question that asks whether you want to run the path.
-
Click
OK in the Run Status dialog box that appears after the
Text Miner node has finished running. The Text Miner node Parse Variable
property has been populated with the SYMPTOM_TEXT variable.