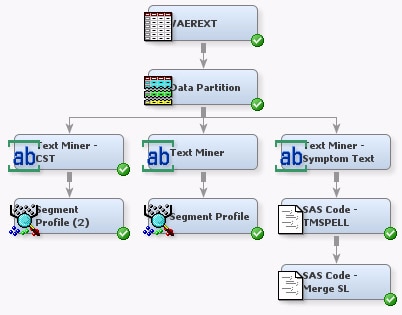
You can redo clustering
to explore the improvements to results from cleaning the SYMPTOM_TEXT
variable. Complete the following steps:
-
Verify
that the Cluster property settings for the Text Miner — CST
node are the same as in previous examples.
-
Right-click
the Text Miner — CST node, and select
Run. Click
Yes in the Confirmation dialog box.
Click
OK in the Run Status dialog box when
the node has finished running.
-
Select
the

button for the Interactive property in the Text
Miner — CST node property panel to open the Interactive Results
window. Look at the Clusters table.
-
Compare
these results to the first Text Miner node results from
View Interactive Results.
Does the clustering seem to have improved with the cleaned SYMPTOM_TEXT
data?
-
Close
the Interactive Results window.
-
Right-click
the Segment Profile node, and select
Copy from the menu. Right-click on an empty space in the diagram workspace,
and select
Paste from the menu.
-
Connect
the Text Miner — CST node to the Segment Profile (2) node.
-
Click
the
for the
Variables property
for the Segment Profile (2) node to open the Variables — Prof2
window. Make sure that the PROB variables and the _SVD_ variables
have a Use value of
No.
-
Click
OK to save the variables settings and close the Variables
— Prof2 window.
-
Right-click
the Segment Profile (2) node and select
Run. Click
Yes in the Confirmation dialog box.
-
Click
Results in the Run Status dialog box to open the Results
window when the node has finished running. Note the significant relationships
in the table. Do the relationships appear clearer with the cleaned
text than they did with the uncleaned text?
-
Close
the Results window.