The SURVEYFREQ Procedure

Rao-Scott Chi-Square Test
The Rao-Scott chi-square test is a design-adjusted version of the Pearson chi-square test, which involves differences between observed and expected frequencies. For information about design-adjusted chi-square tests, see Lohr (2010, Section 10.3.2), Rao and Scott (1981), Rao and Scott (1984), Rao and Scott (1987), and Thomas, Singh, and Roberts (1996).
PROC SURVEYFREQ provides a first-order Rao-Scott chi-square test by default. If you specify the CHISQ(SECONDORDER) option, PROC SURVEYFREQ provides a second-order (Satterthwaite) Rao-Scott chi-square test. The first-order design correction depends only on the design effects of the table cell proportion estimates and, for two-way tables, the design effects of the marginal proportion estimates. The second-order design correction requires computation of the full covariance matrix of the proportion estimates. The second-order test requires more computational resources than the first-order test, but it can provide some performance advantages (for Type I error and power), particularly when the design effects are variable (Thomas and Rao 1987; Rao and Thomas 1989).
One-Way Tables
For one-way tables, the CHISQ option provides a Rao-Scott (design-based) goodness-of-fit test for one-way tables. By default, this is a test for the null hypothesis of equal proportions. If you specify null hypothesis proportions in the TESTP= option, the goodness-of-fit test uses the specified proportions.
First-Order Test
The first-order Rao-Scott chi-square statistic for the goodness-of-fit test is computed as
![\[ Q_{\mi{RS1}} = Q_{\mi{P}} ~ / ~ D \]](images/statug_surveyfreq0187.png)
where 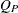 is the Pearson chi-square based on the estimated totals and D is the first-order design correction described in the section First-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1981), Rao and Scott (1984).
is the Pearson chi-square based on the estimated totals and D is the first-order design correction described in the section First-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1981), Rao and Scott (1984).
For a one-way table with C levels, the Pearson chi-square is computed as
![\[ Q_{\mi{P}} = (n / \widehat{N}) ~ \sum _ c (\widehat{N}_ c - E_ c)^2 ~ / ~ E_ c \]](images/statug_surveyfreq0189.png)
where n is the sample size, 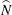 is the estimated overall total,
is the estimated overall total, 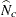 is the estimated total for level c, and
is the estimated total for level c, and 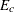 is the expected total for level c under the null hypothesis. For the null hypothesis of equal proportions, the expected total for each level is
is the expected total for level c under the null hypothesis. For the null hypothesis of equal proportions, the expected total for each level is
![\[ E_ c = \widehat{N} ~ / ~ C \]](images/statug_surveyfreq0192.png)
For specified null proportions, the expected total for level c is
![\[ E_ c = \widehat{N} ~ \times ~ P^{~ 0}_ c \]](images/statug_surveyfreq0193.png)
where 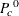 is the null proportion that you specify for level c.
is the null proportion that you specify for level c.
Under the null hypothesis, the first-order Rao-Scott chi-square 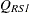 approximately follows a chi-square distribution with (C – 1) degrees of freedom. A better approximation can be obtained by the F statistic,
approximately follows a chi-square distribution with (C – 1) degrees of freedom. A better approximation can be obtained by the F statistic,
![\[ F_{\mi{1}} = Q_{\mi{RS1}} ~ / ~ (C - 1 ) \]](images/statug_surveyfreq0196.png)
which has an F distribution with 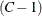 and
and 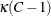 degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of
degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of  is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
First-Order Design Correction
By default for one-way tables, the first-order design correction is computed from the proportion estimates as
![\[ D = \sum _ c (1 - \widehat{P}_ c ) ~ \mr{Deff}(\widehat{P}_ c) ~ / ~ (C-1) \]](images/statug_surveyfreq0200.png)
where
![\begin{eqnarray*} \mr{Deff}(\widehat{P}_ c) & = & \widehat{\mr{Var}}(\widehat{P}_ c) ~ / ~ \mr{Var_{\tiny {srs}}}(\widehat{P}_ c) \\[.1in]& = & \widehat{\mr{Var}}(\widehat{P}_ c) ~ / ~ \left( (1 - f) ~ \widehat{P}_ c ~ (1 - \widehat{P}_ c) ~ / ~ (n-1) \right) \end{eqnarray*}](images/statug_surveyfreq0201.png)
as described in the section Design Effect. 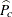 is the proportion estimate for level c,
is the proportion estimate for level c, 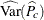 is the variance of the estimate, f is the overall sampling fraction, and n is the number of observations in the sample. The factor (1 – f) is included only for Taylor series variance estimation (VARMETHOD=TAYLOR
) when you specify the RATE=
or TOTAL=
option. For more information, see the section Design Effect.
is the variance of the estimate, f is the overall sampling fraction, and n is the number of observations in the sample. The factor (1 – f) is included only for Taylor series variance estimation (VARMETHOD=TAYLOR
) when you specify the RATE=
or TOTAL=
option. For more information, see the section Design Effect.
If you specify the CHISQ(MODIFIED)
or LRCHISQ(MODIFIED)
option, the design correction is computed by using null hypothesis proportions instead of proportion estimates. By default,
null hypothesis proportions are equal proportions for all levels of the one-way table. Alternatively, you can specify null
proportion values in the TESTP=
option. The modified design correction 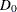 is computed from null hypothesis proportions as
is computed from null hypothesis proportions as
![\[ D_0 = \sum _ c (1 - P^{~ 0}_ c) ~ \mr{Deff}_0(\widehat{P}_{c}) ~ / ~ (C-1) \]](images/statug_surveyfreq0205.png)
where
![\begin{eqnarray*} \mr{Deff}_0(\widehat{P}_ c) & = & \widehat{\mr{Var}}(\widehat{P}_ c) ~ / ~ \mr{Var_{\tiny {srs}}}(P^{~ 0}_ c) \\[0.1in]& = & \widehat{\mr{Var}}(\widehat{P}_ c) ~ / ~ \left( (1 - f) P^{~ 0}_ c ~ (1 - P^{~ 0}_ c) ~ / ~ (n-1) \right) \end{eqnarray*}](images/statug_surveyfreq0206.png)
The null hypothesis proportion is 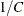 for equal proportions (the default), or is the null proportion that you specify for level c if you use the TESTP= option.
for equal proportions (the default), or is the null proportion that you specify for level c if you use the TESTP= option.
Second-Order Test
The second-order (Satterthwaite) Rao-Scott chi-square statistic for the goodness-of-fit test is computed as
![\[ Q_{\mi{RS2}} = Q_{\mi{RS1}} ~ / ~ ( 1 + \hat{a}^2 ) \]](images/statug_surveyfreq0208.png)
where is the first-order Rao-Scott chi-square statistic described in the section First-Order Test and 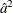 is the second-order design correction described in the section Second-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
is the second-order design correction described in the section Second-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
Under the null hypothesis, the second-order Rao-Scott chi-square 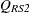 approximately follows a chi-square distribution with
approximately follows a chi-square distribution with 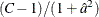 degrees of freedom. The corresponding F statistic is
degrees of freedom. The corresponding F statistic is
![\[ F_{\mi{RS2}} = Q_{\mi{RS2}} ~ / ~ (C - 1 ) \]](images/statug_surveyfreq0212.png)
which has an F distribution with and 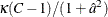 degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
Second-Order Design Correction
The second-order (Satterthwaite) design correction for one-way tables is computed from the eigenvalues of the estimated design
effects matrix 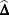 , which are known as generalized design effects. The design effects matrix is computed as
, which are known as generalized design effects. The design effects matrix is computed as
![\[ \widehat{\bDelta } ~ = ~ (n-1)/(1-f) ~ \left( {\mr{\mb{Cov_{\tiny {srs}}}}(\widehat{\mb{P}})}^{-1} ~ \widehat{\mb{Cov}}(\widehat{\mb{P}}) \right) \]](images/statug_surveyfreq0215.png)
where  is the covariance under multinomial sampling (srs with replacement) and
is the covariance under multinomial sampling (srs with replacement) and 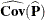 is the covariance matrix of the first (C – 1) proportion estimates. For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
is the covariance matrix of the first (C – 1) proportion estimates. For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
By default, the srs covariance matrix is computed from the proportion estimates as
![\[ \mr{\mb{Cov_{\tiny {srs}}}}(\widehat{\mb{P}}) ~ = ~ \mr{Diag}(\widehat{\mb{P}}) - \widehat{\mb{P}} ~ \widehat{\mb{P}}^{~ \prime } \]](images/statug_surveyfreq0218.png)
where 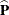 is an array of (C – 1) proportion estimates. If you specify the CHISQ(MODIFIED)
or LRCHISQ(MODIFIED)
option, the srs covariance matrix is computed from the null hypothesis proportions
is an array of (C – 1) proportion estimates. If you specify the CHISQ(MODIFIED)
or LRCHISQ(MODIFIED)
option, the srs covariance matrix is computed from the null hypothesis proportions 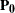 as
as
![\[ \mr{\mb{Cov_{\tiny {srs}}}}(\mb{P_0}) ~ = ~ \mr{Diag}({\mb{P_0}}) - \mb{P_0} ~ \mb{P_0}^\prime \]](images/statug_surveyfreq0221.png)
where is an array of (C – 1) null hypothesis proportions. The null hypothesis proportions equal by default. If you use the TESTP= option to specify null hypothesis proportions, is an array of (C – 1) proportions that you specify.
The second-order design correction is computed as
![\[ \hat{a}^2 ~ = ~ \left( \sum _{c=1}^{C-1}{ d_ c^2 / (C-1)\bar{d}^2 } \right) - 1 \]](images/statug_surveyfreq0222.png)
where 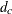 are the eigenvalues of the design effects matrix and
are the eigenvalues of the design effects matrix and 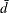 is the average of the eigenvalues.
is the average of the eigenvalues.
Two-Way Tables
For two-way tables, the CHISQ option provides a Rao-Scott (design-based) test of association between the row and column variables. PROC SURVEYFREQ provides a first-order Rao-Scott chi-square test by default. If you specify the CHISQ(SECONDORDER) option, PROC SURVEYFREQ provides a second-order (Satterthwaite) Rao-Scott chi-square test.
First-Order Test
The first-order Rao-Scott chi-square statistic is computed as
where is the Pearson chi-square based on the estimated totals and D is the design correction described in the section First-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1984), and Rao and Scott (1987).
For a two-way tables with R rows and C columns, the Pearson chi-square is computed as
![\[ Q_{\mi{P}} = (n / \widehat{N}) ~ \sum _ r \sum _ c (\widehat{N}_{rc} - E_{rc})^2 ~ / ~ {E_{rc}} \]](images/statug_surveyfreq0225.png)
where n is the sample size, is the estimated overall total, 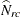 is the estimated total for table cell (r, c), and
is the estimated total for table cell (r, c), and 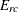 is the expected total for table cell (r,c) under the null hypothesis of no association,
is the expected total for table cell (r,c) under the null hypothesis of no association,
![\[ E_{rc} = \widehat{N}_{r \cdot } ~ \widehat{N}_{\cdot c} ~ / ~ \widehat{N} \]](images/statug_surveyfreq0124.png)
Under the null hypothesis of no association, the first-order Rao-Scott chi-square approximately follows a chi-square distribution with (R – 1)(C – 1) degrees of freedom. A better approximation can be obtained by the F statistic,
![\[ F_{\mi{1}} = Q_{\mi{RS1}} ~ / ~ (R - 1 ) (C - 1 ) \]](images/statug_surveyfreq0227.png)
which has an F distribution with 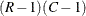 and
and 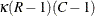 degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
First-Order Design Correction
By default for a first-order test, PROC SURVEYFREQ computes the design correction from proportion estimates. If you specify the CHISQ(MODIFIED) or LRCHISQ(MODIFIED) option for a first-order test, the procedure computes the design correction from null hypothesis proportions.
Second-order tests, which you request by specifying the CHISQ(SECONDORDER) or LRCHISQ(SECONDORDER) option, are computed by applying both first-order and second-order design corrections to the weighted chi-square statistic. For second-order tests for two-way tables, PROC SURVEYFREQ always uses null hypothesis proportions to compute both the first-order and second-order design corrections.
The first-order design correction D that is based on proportion estimates is computed as
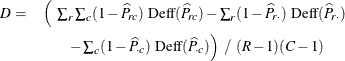
where
![\begin{eqnarray*} \mr{Deff}(\widehat{P}_{rc}) & = & \widehat{\mr{Var}}(\widehat{P}_{rc}) ~ / ~ \mr{Var_{\tiny {srs}}}(\widehat{P}_{rc}) \\[.1in]& = & \mr{\mr{Var}}(\widehat{P}_{rc}) ~ / ~ \left( (1 - f) ~ \widehat{P}_{rc} ~ (1 - \widehat{P}_{rc}) ~ / ~ (n-1) \right) \end{eqnarray*}](images/statug_surveyfreq0231.png)
as described in the section Design Effect. 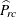 is the estimate of the proportion in table cell (r, c),
is the estimate of the proportion in table cell (r, c), 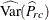 is the variance of the estimate, f is the overall sampling fraction, and n is the number of observations in the sample. The factor (1 – f) is included only for Taylor series variance estimation (VARMETHOD=TAYLOR
) when you specify the RATE=
or TOTAL=
option. For more information, see the section Design Effect.
is the variance of the estimate, f is the overall sampling fraction, and n is the number of observations in the sample. The factor (1 – f) is included only for Taylor series variance estimation (VARMETHOD=TAYLOR
) when you specify the RATE=
or TOTAL=
option. For more information, see the section Design Effect.
The design effects for the estimate of the proportion in row r and the estimate of the proportion in column c (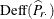 and
and 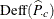 , respectively) are computed in the same way.
, respectively) are computed in the same way.
If you specify the CHISQ(MODIFIED)
or LRCHISQ(MODIFIED)
option for a first-order Rao-Scott test, or if you request a second-order test for a two-way table (CHISQ(SECONDORDER)
or LRCHISQ(SECONDORDER)
), the procedure computes the design correction from the null hypothesis cell proportions instead of the estimated cell proportions.
For two-way tables, the null hypothesis cell proportions are computed as the products of the corresponding row and column
proportion estimates. The modified design correction (based on null hypothesis proportions) is computed as
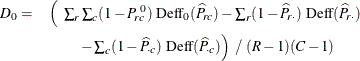
where
![\[ P^{~ 0}_{rc} = \widehat{P}_{r \cdot } ~ \times ~ \widehat{P}_{\cdot c} \]](images/statug_surveyfreq0235.png)
and
![\begin{eqnarray*} \mr{Deff}_0(\widehat{P}_{rc}) & = & \widehat{\mr{Var}}(\widehat{P}_{rc}) ~ / ~ \mr{Var_{\tiny {srs}}}(P^{~ 0}_{rc}) \\[0.1in]& = & \widehat{\mr{Var}}(\widehat{P}_{rc}) ~ / ~ \left( (1 - f) ~ P^{~ 0}_{rc} ~ (1 - P^{~ 0}_{rc}) ~ / ~ (n-1) \right) \end{eqnarray*}](images/statug_surveyfreq0236.png)
Second-Order Test
The second-order (Satterthwaite) Rao-Scott chi-square statistic for two-way tables is computed as
where is the first-order Rao-Scott chi-square statistic described in the section First-Order Test and is the second-order design correction described in the section Second-Order Design Correction. For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
Under the null hypothesis, the second-order Rao-Scott chi-square approximately follows a chi-square distribution with 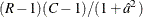 degrees of freedom. The corresponding F statistic is
degrees of freedom. The corresponding F statistic is
![\[ F_{\mi{RS2}} = Q_{\mi{RS2}} ~ (1 + \hat{a}^2) ~ / ~ (R - 1) (C - 1 ) \]](images/statug_surveyfreq0238.png)
which has an F distribution with and 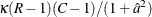 degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
degrees of freedom under the null hypothesis (Thomas and Rao 1984, 1987). The value of is the degrees of freedom for the variance estimator. The degrees of freedom computation depends on the sample design and
the variance estimation method. For more information, see the section Degrees of Freedom.
Second-Order Design Correction
The second-order (Satterthwaite) design correction for two-way tables is computed from the eigenvalues of the estimated design
effects matrix , which are known as generalized design effects. The design effects matrix is defined as
![\[ \widehat{\bDelta } ~ = ~ (n-1)/(1-f) ~ \left( {\mr{\mb{Cov_{\tiny {srs}}}}(\widehat{\mb{P}})}^{-1} ~ \mb{H} ~ \widehat{\mb{Cov}}(\widehat{\mb{P}}) ~ \mb{H}^{~ \prime } \right) \]](images/statug_surveyfreq0240.png)
where is the covariance matrix of the 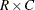 proportion estimates and is the covariance under multinomial sampling (srs with replacement). For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
proportion estimates and is the covariance under multinomial sampling (srs with replacement). For more information, see Rao and Scott (1979), Rao and Scott (1981), and Rao and Thomas (1989).
The second-order design correction is computed from the design effects matrix as
![\[ \hat{a}^2 ~ = ~ \left( \sum _{i=1}^{K}{ d_ c^2 / K \bar{d}^2 } \right) - 1 \]](images/statug_surveyfreq0242.png)
where K = (R – 1)(C – 1), are the eigenvalues of , and is the average eigenvalue.
The srs covariance matrix is computed as
![\[ \mr{\mb{Cov_{\tiny {srs}}}}(\widehat{\mb{P}}) ~ = ~ \widehat{\mb{P}}_\mb {r} \otimes \widehat{\mb{P}}_{\mb{c}} \]](images/statug_surveyfreq0243.png)
where 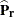 is an
is an 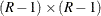 matrix that is constructed from the array of (R – 1) row proportion estimates
matrix that is constructed from the array of (R – 1) row proportion estimates 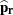 as
as
![\[ \widehat{\mb{P}}_{\mb{r}} ~ = ~ \mr{Diag}(\widehat{\mb{p}}_{\mb{r}}) - \widehat{\mb{p}}_{\mb{r}} ~ \widehat{\mb{p}}_{\mb{r}}^{~ \prime } \]](images/statug_surveyfreq0247.png)
Similarly, 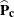 is a
is a 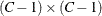 matrix that is constructed from the array of (C – 1) column proportion estimates
matrix that is constructed from the array of (C – 1) column proportion estimates 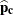 as
as
![\[ \widehat{\mb{P}}_{\mb{c}} ~ = ~ \mr{Diag}(\widehat{\mb{p}}_{\mb{c}}) - \widehat{\mb{p}}_{\mb{c}} ~ \widehat{\mb{p}}_{\mb{c}}^{~ \prime } \]](images/statug_surveyfreq0251.png)
The 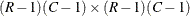 matrix
matrix 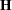 is computed as
is computed as
![\[ \mb{H} ~ = ~ \mb{J_ r} \otimes \mb{J_ c} ~ - ~ ( \widehat{\mb{p}}_{\mb{r}} ~ \mb{l}_{\mb{r}}^{~ \prime } ) \otimes \mb{J_ c} ~ - ~ \mb{J_ r} \otimes ( \widehat{\mb{p}}_{\mb{r}} ~ \mb{l}_{\mb{r}}^{~ \prime } ) \]](images/statug_surveyfreq0254.png)
where 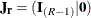 ,
, 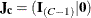 ,
, 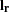 is an
is an 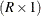 array of ones, and
array of ones, and 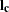 is an
is an 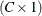 array of ones. For more information, see Rao and Scott (1979, p. 61).
array of ones. For more information, see Rao and Scott (1979, p. 61).