Introduction to Statistical Modeling with SAS/STAT Software
Expectations of Random Variables and Vectors
If Y is a discrete random variable with mass function 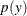 and support (possible values)
and support (possible values) 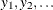 , then the expectation (expected value) of Y is defined as
, then the expectation (expected value) of Y is defined as
![\[ \mr{E}[Y] = \sum _{j=1}^\infty y_ j \, p(y_ j) \]](images/statug_intromod0284.png)
provided that 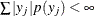 , otherwise the sum in the definition is not well-defined. The expected value of a function
, otherwise the sum in the definition is not well-defined. The expected value of a function 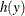 is similarly defined: provided that
is similarly defined: provided that 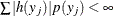 ,
,
![\[ \mr{E}[h(Y)] = \sum _{j=1}^\infty h(y_ j)\, p(y_ j) \]](images/statug_intromod0288.png)
For continuous random variables, similar definitions apply, but summation is replaced by integration over the support of
the random variable. If X is a continuous random variable with density function 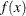 , and
, and 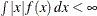 , then the expectation of X is defined as
, then the expectation of X is defined as
![\[ \mr{E}[X] = \int _{-\infty }^{\infty } x f(x) \, dx \]](images/statug_intromod0291.png)
The expected value of a random variable is also called its mean or its first moment. A particularly important function of a random variable is ![$h(Y) = (Y - \mr{E}[Y])^2$](images/statug_intromod0292.png) . The expectation of
. The expectation of 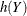 is
called the variance of Y or the second central moment of Y. When you study the properties of multiple random variables, then you might be interested in aspects of their joint distribution.
The
covariance between random variables Y and X is defined as the expected value of the function
is
called the variance of Y or the second central moment of Y. When you study the properties of multiple random variables, then you might be interested in aspects of their joint distribution.
The
covariance between random variables Y and X is defined as the expected value of the function ![$(Y-\mr{E}[Y])(X-\mr{E}[X])$](images/statug_intromod0294.png) , where the expectation is taken under the bivariate joint distribution of Y and X:
, where the expectation is taken under the bivariate joint distribution of Y and X:
![\[ \mr{Cov}[Y,X] = \mr{E}[(Y-\mr{E}[Y])(X-\mr{E}[X])] = \mr{E}[YX] - \mr{E}[Y]\mr{E}[X] = \int \int x\, y f(x,y) \, \, dx\, dy - \mr{E}[Y]\mr{E}[X] \]](images/statug_intromod0295.png)
The covariance between a random variable and itself is the variance, ![$\mr{Cov}[Y,Y] = \mr{Var}[Y]$](images/statug_intromod0296.png) .
.
In statistical applications and formulas, random variables are often collected into vectors. For example, a random sample
of size n from the distribution of Y generates a random vector of order 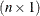 ,
,
![\[ \bY = \left[ \begin{array}{c} Y_1 \cr Y_2 \cr \vdots \cr Y_ n \end{array}\right] \]](images/statug_intromod0297.png)
The expected value of the random vector 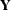 is the vector of the means of the elements of :
is the vector of the means of the elements of :
![\[ \mb{E}[\bY ] = \left[\mr{E}\left[Y_ i\right]\right] = \left[ \begin{array}{c} \mr{E}[Y_1] \cr \mr{E}[Y_2] \cr \vdots \cr \mr{E}[Y_ n] \end{array}\right] \]](images/statug_intromod0298.png)
It is often useful to directly apply rules about working with means, variances, and covariances of random vectors. To develop
these rules, suppose that and 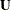 denote two random vectors with typical elements
denote two random vectors with typical elements 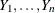 and
and 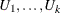 . Further suppose that
. Further suppose that 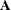 and
and 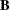 are constant (nonstochastic) matrices, that
are constant (nonstochastic) matrices, that  is a constant vector, and that the
is a constant vector, and that the 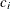 are scalar constants.
are scalar constants.
The following rules enable you to derive the mean of a linear function of a random vector:
![\begin{align*} \mr{E}[\bA ] =& \, \, \bA \\ \mr{E}[\mb{AY}+ \mb{a}] =& \, \, \bA \mr{E}[\bY ]+\mb{a} \\ \mr{E}[\bY + \bU ] =& \, \, \mr{E}[\bY ] + \mr{E}[\bU ]\\ \end{align*}](images/statug_intromod0303.png)
The covariance matrix of and 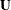 is the
is the 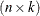 matrix whose typical element in row i, column j is the covariance between
matrix whose typical element in row i, column j is the covariance between 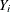 and
and 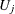 . The covariance matrix between two random vectors is frequently denoted with the
. The covariance matrix between two random vectors is frequently denoted with the 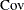 "operator."
"operator."
![\begin{align*} \mr{Cov}[\bY ,\bU ] =& \left[\mr{Cov}[Y_ i,U_ j]\right] \\ =& \, \, \mr{E}\left[ \left(\bY -\mr{E}[\bY ]\right) \left(\bU -\mr{E}[\bU ]\right)^\prime \right] = \mr{E}\left[\mb{YU}’\right] - \mr{E}[\bY ]\mr{E}[\bU ]’ \\[0.1in] =& \left[\begin{array}{lllll} \mr{Cov}[Y_1,U_1] & \mr{Cov}[Y_1,U_2] & \mr{Cov}[Y_1,U_3] & \cdots & \mr{Cov}[Y_1,U_ k] \cr \mr{Cov}[Y_2,U_1] & \mr{Cov}[Y_2,U_2] & \mr{Cov}[Y_2,U_3] & \cdots & \mr{Cov}[Y_2,U_ k] \cr \mr{Cov}[Y_3,U_1] & \mr{Cov}[Y_3,U_2] & \mr{Cov}[Y_3,U_3] & \cdots & \mr{Cov}[Y_3,U_ k] \cr \vdots & \vdots & \vdots & \ddots & \vdots \cr \mr{Cov}[Y_ n,U_1] & \mr{Cov}[Y_ n,U_2] & \mr{Cov}[Y_ n,U_3] & \cdots & \mr{Cov}[Y_ n,U_ k] \cr \end{array}\right] \end{align*}](images/statug_intromod0307.png)
The variance matrix of a random vector is the covariance matrix between and itself. The variance matrix is frequently denoted with the 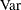 "operator."
"operator."
![\begin{align*} \mr{Var}[\bY ] =& \, \, \mr{Cov}[\bY ,\bY ] = \left[\mr{Cov}[Y_ i,Y_ j]\right] \\ =& \, \, \mr{E}\left[ \left(\bY -\mr{E}[\bY ]\right) \left(\bY -\mr{E}[\bY ]\right)^\prime \right] = \mr{E}\left[\mb{YY}’\right] - \mr{E}[\bY ]\mr{E}[\bY ]’ \\[0.1in] =& \left[\begin{array}{lllll} \mr{Cov}[Y_1,Y_1] & \mr{Cov}[Y_1,Y_2] & \mr{Cov}[Y_1,Y_3] & \cdots & \mr{Cov}[Y_1,Y_ n] \cr \mr{Cov}[Y_2,Y_1] & \mr{Cov}[Y_2,Y_2] & \mr{Cov}[Y_2,Y_3] & \cdots & \mr{Cov}[Y_2,Y_ n] \cr \mr{Cov}[Y_3,Y_1] & \mr{Cov}[Y_3,Y_2] & \mr{Cov}[Y_3,Y_3] & \cdots & \mr{Cov}[Y_3,Y_ n] \cr \vdots & \vdots & \vdots & \ddots & \vdots \cr \mr{Cov}[Y_ n,Y_1] & \mr{Cov}[Y_ n,Y_2] & \mr{Cov}[Y_ n,Y_3] & \cdots & \mr{Cov}[Y_ n,Y_ n] \cr \end{array}\right] \\[0.15in] =& \left[\begin{array}{lllll} \mr{Var}[Y_1] & \mr{Cov}[Y_1,Y_2] & \mr{Cov}[Y_1,Y_3] & \cdots & \mr{Cov}[Y_1,Y_ n] \cr \mr{Cov}[Y_2,Y_1] & \mr{Var}[Y_2] & \mr{Cov}[Y_2,Y_3] & \cdots & \mr{Cov}[Y_2,Y_ n] \cr \mr{Cov}[Y_3,Y_1] & \mr{Cov}[Y_3,Y_2] & \mr{Var}[Y_3] & \cdots & \mr{Cov}[Y_3,Y_ n] \cr \vdots & \vdots & \vdots & \ddots & \vdots \cr \mr{Cov}[Y_ n,Y_1] & \mr{Cov}[Y_ n,Y_2] & \mr{Cov}[Y_ n,Y_3] & \cdots & \mr{Var}[Y_ n] \cr \end{array}\right] \\ \end{align*}](images/statug_intromod0309.png)
Because the variance matrix contains variances on the diagonal and covariances in the off-diagonal positions, it is also
referred to as
the variance-covariance matrix of the random vector .
If the elements of the covariance matrix ![$\mr{Cov}[\bY ,\bU ]$](images/statug_intromod0310.png) are zero, the random vectors are
uncorrelated. If and are normally distributed, then a zero covariance matrix implies that the vectors are stochastically independent. If the off-diagonal
elements of the variance matrix
are zero, the random vectors are
uncorrelated. If and are normally distributed, then a zero covariance matrix implies that the vectors are stochastically independent. If the off-diagonal
elements of the variance matrix ![$\mr{Var}[\bY ]$](images/statug_intromod0311.png) are zero, the elements of the random vector are uncorrelated. If is normally distributed, then a diagonal variance matrix implies that its elements are stochastically independent.
are zero, the elements of the random vector are uncorrelated. If is normally distributed, then a diagonal variance matrix implies that its elements are stochastically independent.
Suppose that and are constant (nonstochastic) matrices and that denotes a scalar constant. The following results are useful in manipulating covariance matrices:
![\begin{align*} \mr{Cov}[\mb{AY},\bU ] =& \, \, \bA \mr{Cov}[\bY ,\bU ] \\ \mr{Cov}[\bY ,\mb{BU}] =& \, \, \mr{Cov}[\bY ,\bU ]\bB ’ \\ \mr{Cov}[\mb{AY},\mb{BU}] =& \, \, \bA \mr{Cov}[\bY ,\bU ]\bB ’ \\ \mr{Cov}[c_1\bY _1+c_2\bU _1,c_3\bY _2+c_4\bU _2] =& \, \, c_1c_3 \mr{Cov}[\bY _1,\bY _2] + c_1c_4 \mr{Cov}[\bY _1,\bU _2] \\ +& \, \, c_2c_3 \mr{Cov}[\bU _1,\bY _2] + c_2c_4 \mr{Cov}[\bU _1,\bU _2] \end{align*}](images/statug_intromod0312.png)
Since ![$\mr{Cov}[\bY ,\bY ] = \mr{Var}[\bY ]$](images/statug_intromod0313.png) , these results can be applied to produce the following results, useful in manipulating variances of random vectors:
, these results can be applied to produce the following results, useful in manipulating variances of random vectors:
![\begin{align*} \mr{Var}[\bA ] =& \, \, \mb{0} \\ \mr{Var}[\mb{AY}] =& \, \, \bA \mr{Var}[\bY ]\bA ’ \\ \mr{Var}[\bY +\mb{x}] =& \, \, \mr{Var}[\bY ] \\ \mr{Var}[\mb{x}’\bY ] =& \, \, \mb{x}’\mr{Var}[\bY ]\mb{x} \\ \mr{Var}[c_1\bY ] =& \, \, c_1^2 \mr{Var}[\bY ] \\ \mr{Var}[c_1\bY +c_2\mb{U}]=& \, \, c_1^2\mr{Var}[\bY ] + c_2^2\mr{Var}[\mb{U}] + 2c_1c_2\mr{Cov}[\bY ,\mb{U}] \end{align*}](images/statug_intromod0314.png)
Another area where expectation rules are helpful is quadratic forms in random variables. These forms arise particularly in
the study of linear statistical models and in linear statistical inference. Linear inference is statistical inference about
linear function of random variables, even if those random variables are defined through nonlinear models. For example, the
parameter estimator 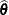 might be derived in a nonlinear model, but this does not prevent statistical questions from being raised that can be expressed
through linear functions of
might be derived in a nonlinear model, but this does not prevent statistical questions from being raised that can be expressed
through linear functions of 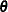 ; for example,
; for example,
![\[ H_0\colon \left\{ \begin{array}{cc} \theta _1 - 2\theta _2 = 0 \cr \theta _2 - \theta _3 = 0 \end{array}\right. \]](images/statug_intromod0317.png)
if is a matrix of constants and is a random vector, then
![\[ \mr{E}[\bY ’\mb{AY}] = \mr{trace}(\bA \mr{Var}[\bY ]) + \mr{E}[\bY ]’\bA \mr{E}[\bY ] \]](images/statug_intromod0318.png)