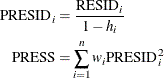After the model has been fit, predicted and residual values are usually calculated, graphed, and output. The predicted values are calculated from the estimated regression equation; the raw residuals are calculated as the observed value minus the predicted value. Often other forms of residuals, such as studentized or cumulative residuals, are used for model diagnostics. Some procedures can calculate standard errors of residuals, predicted mean values, and individual predicted values.
Consider the ith observation, where ![]() is the row of regressors,
is the row of regressors, ![]() is the vector of parameter estimates, and
is the vector of parameter estimates, and ![]() is the estimate of the residual variance (the mean squared error).
The leverage value of the ith observation is defined as
is the estimate of the residual variance (the mean squared error).
The leverage value of the ith observation is defined as
where ![]() is the design matrix for the observed data,
is the design matrix for the observed data, ![]() is an arbitrary regressor vector (possibly but not necessarily a row of
is an arbitrary regressor vector (possibly but not necessarily a row of ![]() ),
), ![]() is a diagonal matrix of observed weights, and
is a diagonal matrix of observed weights, and ![]() is the weight corresponding to
is the weight corresponding to ![]() .
.
Then the predicted mean and the standard error of the predicted mean are
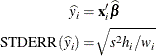
The standard error of the individual (future) predicted value ![]() is
is
If the predictor vector ![]() corresponds to an observation in the analysis data, then the raw residual for that observation and the standard error of
the raw residual are defined as
corresponds to an observation in the analysis data, then the raw residual for that observation and the standard error of
the raw residual are defined as
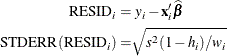
The studentized residual is the ratio of the raw residual and its estimated standard error. Symbolically,
Two types of intervals provide a measure of confidence for prediction: the confidence interval for the mean value of the response, and the prediction (or forecasting) interval for an individual observation. As discussed in the section Mean Squared Error in Chapter 3: Introduction to Statistical Modeling with SAS/STAT Software, both intervals are based on the mean squared error of predicting a target based on the result of the model fit. The difference in the expressions for the confidence interval and the prediction interval occurs because the target of estimation is a constant in the case of the confidence interval (the mean of an observation) and the target is a random variable in the case of the prediction interval (a new observation).
For example, you can construct a confidence interval for the ith observation that contains the true mean value of the response with probability ![]() . The upper and lower limits of the confidence interval for the mean value are
. The upper and lower limits of the confidence interval for the mean value are
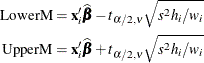
where ![]() is the tabulated t quantile with degrees of freedom equal to the degrees of freedom for the mean squared error,
is the tabulated t quantile with degrees of freedom equal to the degrees of freedom for the mean squared error, ![]() .
.
The limits for the prediction interval for an individual response are
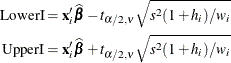
Influential observations are those that, according to various criteria, appear to have a large influence on the analysis. One measure of influence, Cook’s D, measures the change to the estimates that results from deleting an observation,
where k is the number of parameters in the model (including the intercept). For more information, see Cook (1977, 1979).
The predicted residual for observation i is defined as the residual for the ith observation that results from dropping the ith observation from the parameter estimates. The sum of squares of predicted residual errors is called the PRESS statistic: