In matrix notation, a linear model is written as
where ![]() is the
is the ![]() design matrix (rows are observations and columns are the regressors),
design matrix (rows are observations and columns are the regressors), ![]() is the
is the ![]() vector of unknown parameters, and
vector of unknown parameters, and ![]() is the
is the ![]() vector of unobservable model errors. The first column of
vector of unobservable model errors. The first column of ![]() is usually a vector of 1s and is used to estimate the intercept term.
is usually a vector of 1s and is used to estimate the intercept term.
The statistical theory of linear models is based on strict classical assumptions. Ideally, you measure the response after controlling all factors in an experimentally determined environment. If you cannot control the factors experimentally, some tests must be interpreted as being conditional on the observed values of the regressors.
Other assumptions are as follows:
-
The form of the model is correct (all important explanatory variables have been included). This assumption is reflected mathematically in the assumption of a zero mean of the model errors,
![$\mr {E}[\bepsilon ] = \mb {0}$](images/statug_introreg0051.png) .
.
-
Regressor variables are measured without error.
-
The expected value of the errors is 0.
-
The variance of the error (and thus the dependent variable) for the ith observation is
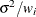 , where
, where 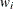 is a known weight factor. Usually,
is a known weight factor. Usually, 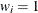 for all i and thus
for all i and thus 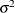 is the common, constant variance.
is the common, constant variance.
-
The errors are uncorrelated across observations.
When hypotheses are tested, or when confidence and prediction intervals are computed, an additional assumption is made that the errors are normally distributed.