| Type I SS and Estimable Functions |
In PROC GLM, the Type I SS and the associated hypotheses they test are byproducts of the modified sweep operator used to compute a generalized 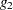 -inverse of
-inverse of  and a solution to the normal equations. For the model
and a solution to the normal equations. For the model  , the Type I SS for each effect are as follows:
, the Type I SS for each effect are as follows:
Effect |
Type I SS |
|
|
|
|
|
|
|
|
|



Note that some other SAS/STAT procedures compute Type I hypotheses by sweeping (for example, PROC MIXED and PROC GLIMMIX), but their test statistics are not necessarily equivalent to the results of using those procedures to fit models that contain successively more effects.
The Type I SS are model-order dependent; each effect is adjusted only for the preceding effects in the model.
There are numerous ways to obtain a Type I hypothesis matrix 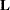 for each effect. One way is to form the matrix and then reduce to an upper triangular matrix by row operations, skipping over any rows with a zero diagonal. The nonzero rows of the resulting matrix associated with
for each effect. One way is to form the matrix and then reduce to an upper triangular matrix by row operations, skipping over any rows with a zero diagonal. The nonzero rows of the resulting matrix associated with  provide an such that
provide an such that
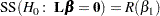 |
The nonzero rows of the resulting matrix associated with  provide an such that
provide an such that
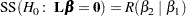 |
The last set of nonzero rows (associated with 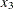 ) provide an such that
) provide an such that
 |
Another more formalized representation of Type I generating sets for , , and , respectively, is
 |
where
 |
and
 |
Using the Type I generating set  (for example), if an is formed from linear combinations of the rows of such that is of full row rank and of the same row rank as , then SS
(for example), if an is formed from linear combinations of the rows of such that is of full row rank and of the same row rank as , then SS .
.
In the GLM procedure, the Type I estimable functions displayed symbolically when the E1 option is requested are
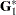 |
 |
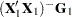 |
|||
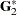 |
|
 |
|||
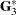 |
|
 |
As can be seen from the nature of the generating sets  , , and
, , and 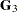 , only the Type I estimable functions for
, only the Type I estimable functions for  are guaranteed not to involve the
are guaranteed not to involve the 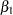 and
and 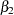 parameters. The Type I hypothesis for can (and often does) involve parameters, and likewise the Type I hypothesis for often involves and parameters.
parameters. The Type I hypothesis for can (and often does) involve parameters, and likewise the Type I hypothesis for often involves and parameters.
There are, however, a number of models for which the Type I hypotheses are considered appropriate. These are as follows:
balanced ANOVA models specified in proper sequence (that is, interactions do not precede main effects in the MODEL statement and so forth)
purely nested models (specified in the proper sequence)
polynomial regression models (in the proper sequence)