| The SURVEYLOGISTIC Procedure |
Details of the PREDPROBS= Option
You can request any of the three given types of predicted probabilities. For example, you can request both the individual predicted probabilities and the cross validated probabilities by specifying PREDPROBS=(I X).
When you specify the PREDPROBS= option, two automatic variables _FROM_ and _INTO_ are included for the single-trial syntax and only one variable, _INTO_, is included for the events/trials syntax. The _FROM_ variable contains the formatted value of the observed response. The variable _INTO_ contains the formatted value of the response level with the largest individual predicted probability.
If you specify PREDPROBS=INDIVIDUAL, the OUTPUT data set contains 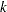 additional variables representing the individual probabilities, one for each response level, where is the maximum number of response levels across all BY groups. The names of these variables have the form IP_xxx, where xxx represents the particular level. The representation depends on the following situations:
additional variables representing the individual probabilities, one for each response level, where is the maximum number of response levels across all BY groups. The names of these variables have the form IP_xxx, where xxx represents the particular level. The representation depends on the following situations:
If you specify the events/trials syntax, xxx is either Event or Nonevent. Thus, the variable that contains the event probabilities is named IP_Event and the variable containing the nonevent probabilities is named IP_Nonevent.
If you specify the single-trial syntax with more than one BY group, xxx is 1 for the first ordered level of the response, 2 for the second ordered level of the response, and so forth, as given in the "Response Profile" table. The variable that contains the predicted probabilities Pr(Y=1) is named IP_1, where Y is the response variable. Similarly, IP_2 is the name of the variable containing the predicted probabilities Pr(Y=2), and so on.
If you specify the single-trial syntax with no BY-group processing, xxx is the left-justified formatted value of the response level (the value can be truncated so that IP_xxx does not exceed 32 characters). For example, if Y is the response variable with response levels 'None,' 'Mild,' and 'Severe,' the variables representing individual probabilities Pr(Y='None'), Pr(Y='Mild'), and Pr(Y='Severe') are named IP_None, IP_Mild, and IP_Severe, respectively.
If you specify PREDPROBS=CUMULATIVE, the OUTPUT data set contains additional variables that represent the cumulative probabilities, one for each response level, where is the maximum number of response levels across all BY groups. The names of these variables have the form CP_xxx, where xxx represents the particular response level. The naming convention is similar to that given by PREDPROBS=INDIVIDUAL. The PREDPROBS=CUMULATIVE values are the same as those output by the PREDICT=keyword, but they are arranged in variables in each output observation rather than in multiple output observations.
If you specify PREDPROBS=CROSSVALIDATE, the OUTPUT data set contains additional variables representing the cross validated predicted probabilities of the response levels, where is the maximum number of response levels across all BY groups. The names of these variables have the form XP_xxx, where xxx represents the particular level. The representation is the same as that given by PREDPROBS=INDIVIDUAL, except that for the events/trials syntax there are four variables for the cross validated predicted probabilities instead of two:
- XP_EVENT_R1E
is the cross validated predicted probability of an event when a current event trial is removed.
- XP_NONEVENT_R1E
is the cross validated predicted probability of a nonevent when a current event trial is removed.
- XP_EVENT_R1N
is the cross validated predicted probability of an event when a current nonevent trial is removed.
- XP_NONEVENT_R1N
is the cross validated predicted probability of a nonevent when a current nonevent trial is removed.
Copyright © SAS Institute, Inc. All Rights Reserved.