| The NLIN Procedure |
| Notation for Nonlinear Regression Models |
This section briefly introduces the basic notation for nonlinear regression models that applies in this chapter. Additional notation is introduced throughout as needed.
The 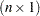 vector of observed responses is denoted as
vector of observed responses is denoted as 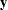 . This vector is the realization of an random vector
. This vector is the realization of an random vector 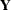 . The NLIN procedure assumes that the variance matrix of this random vector is
. The NLIN procedure assumes that the variance matrix of this random vector is 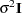 . In other words, the observations have equal variance (are homoscedastic) and are uncorrelated. By defining the special variable _WEIGHT_ in your NLIN programming statements, you can introduce heterogeneous variances. If a _WEIGHT_ variable is present, then
. In other words, the observations have equal variance (are homoscedastic) and are uncorrelated. By defining the special variable _WEIGHT_ in your NLIN programming statements, you can introduce heterogeneous variances. If a _WEIGHT_ variable is present, then 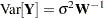 , where
, where 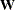 is a diagonal matrix containing the values of the _WEIGHT_ variable.
is a diagonal matrix containing the values of the _WEIGHT_ variable.
The mean of the random vector is represented by a nonlinear model that depends on parameters  and regressor (independent) variables
and regressor (independent) variables 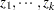 :
:
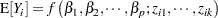 |
In contrast to linear models, the number of regressor variables (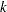 ) does not necessarily equal the number of parameters (
) does not necessarily equal the number of parameters ( ) in the mean function
) in the mean function  . For example, the model fitted in the next subsection contains a single regressor and two parameters.
. For example, the model fitted in the next subsection contains a single regressor and two parameters.
To represent the mean of the vector of observations, boldface notation is used in an obvious extension of the previous equation:
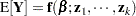 |
The vector  , for example, is an vector of the values for the first regressor variables. The explicit dependence of the mean function on
, for example, is an vector of the values for the first regressor variables. The explicit dependence of the mean function on 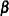 and/or the
and/or the  vectors is often omitted for brevity.
vectors is often omitted for brevity.
In summary, the stochastic structure of models fit with the NLIN procedure is mathematically captured by
 |
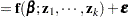 |
|||
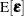 |
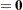 |
|||
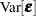 |
 |
Note that the residual variance 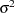 is typically also unknown. Since it is not estimated in the same fashion as the other parameters, it is often not counted in the number of parameters of the nonlinear regression. An estimate of is obtained after the model fit by the method of moments based on the residual sum of squares.
is typically also unknown. Since it is not estimated in the same fashion as the other parameters, it is often not counted in the number of parameters of the nonlinear regression. An estimate of is obtained after the model fit by the method of moments based on the residual sum of squares.
A matrix that plays an important role in fitting nonlinear regression models is the 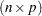 matrix of the first partial derivatives of the mean function
matrix of the first partial derivatives of the mean function  with respect to the model parameters. It is frequently denoted as
with respect to the model parameters. It is frequently denoted as
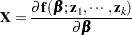 |
The use of the symbol 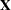 —common in linear statistical modeling—is no accident here. The first derivative matrix plays a similar role in nonlinear regression to that of the matrix in a linear model. For example, the asymptotic variance of the nonlinear least-squares estimators is proportional to
—common in linear statistical modeling—is no accident here. The first derivative matrix plays a similar role in nonlinear regression to that of the matrix in a linear model. For example, the asymptotic variance of the nonlinear least-squares estimators is proportional to 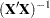 , and projection-type matrices in nonlinear regressions are based on
, and projection-type matrices in nonlinear regressions are based on  . Also, fitting a nonlinear regression model can be cast as an iterative process where a nonlinear model is approximated by a series of linear models in which the derivative matrix is the regressor matrix. An important difference between linear and nonlinear models is that the derivatives in a linear model do not depend on any parameters (see previous subsection). In contrast, the derivative matrix
. Also, fitting a nonlinear regression model can be cast as an iterative process where a nonlinear model is approximated by a series of linear models in which the derivative matrix is the regressor matrix. An important difference between linear and nonlinear models is that the derivatives in a linear model do not depend on any parameters (see previous subsection). In contrast, the derivative matrix  is a function of at least one element of . It is this dependence that lies at the core of the fact that estimating the parameters in a nonlinear model cannot be accomplished in closed form, but it is an iterative process that commences with user-supplied starting values and attempts to continually improve on the parameter estimates.
is a function of at least one element of . It is this dependence that lies at the core of the fact that estimating the parameters in a nonlinear model cannot be accomplished in closed form, but it is an iterative process that commences with user-supplied starting values and attempts to continually improve on the parameter estimates.
Copyright © SAS Institute, Inc. All Rights Reserved.