| The MODECLUS Procedure |
Overview: MODECLUS Procedure
The MODECLUS procedure clusters observations in a SAS data set by using any of several algorithms based on nonparametric density estimates. The data can be numeric coordinates or distances. PROC MODECLUS can perform approximate significance tests for the number of clusters and can hierarchically join nonsignificant clusters. The significance tests are empirically validated by simulations with sample sizes ranging from 20 to 2000.
PROC MODECLUS produces output data sets containing density estimates and cluster membership, various cluster statistics including approximate 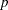 -values, and a summary of the number of clusters generated by various algorithms, smoothing parameters, and significance levels.
-values, and a summary of the number of clusters generated by various algorithms, smoothing parameters, and significance levels.
Most clustering methods are biased toward finding clusters possessing certain characteristics related to size (number of members), shape, or dispersion. Methods based on the least squares criterion (Sarle; 1982), such as 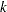 -means and Ward’s minimum variance method, tend to find clusters with roughly the same number of observations in each cluster. Average linkage (see
Chapter 29,
The CLUSTER Procedure
) is somewhat biased toward finding clusters of equal variance. Many clustering methods tend to produce compact, roughly hyperspherical clusters and are incapable of detecting clusters with highly elongated or irregular shapes. The methods with the least bias are those based on nonparametric density estimation (Silverman 1986, pp. 130–146; Scott 1992, pp. 125–190) such as density linkage (see
Chapter 29,
The CLUSTER Procedure
), Wong and Lane (1983), and Wong and Schaack (1982). The biases of many commonly used clustering methods are discussed in
Chapter 11,
Introduction to Clustering Procedures.
-means and Ward’s minimum variance method, tend to find clusters with roughly the same number of observations in each cluster. Average linkage (see
Chapter 29,
The CLUSTER Procedure
) is somewhat biased toward finding clusters of equal variance. Many clustering methods tend to produce compact, roughly hyperspherical clusters and are incapable of detecting clusters with highly elongated or irregular shapes. The methods with the least bias are those based on nonparametric density estimation (Silverman 1986, pp. 130–146; Scott 1992, pp. 125–190) such as density linkage (see
Chapter 29,
The CLUSTER Procedure
), Wong and Lane (1983), and Wong and Schaack (1982). The biases of many commonly used clustering methods are discussed in
Chapter 11,
Introduction to Clustering Procedures.
PROC MODECLUS implements several clustering methods by using nonparametric density estimation. Such clustering methods are referred to hereafter as nonparametric clustering methods. The methods in PROC MODECLUS are related to, but not identical to, methods developed by Gitman (1973), Huizinga (1978), Koontz and Fukunaga (1972a, 1972b), Koontz, Narendra, and Fukunaga (1976), Mizoguchi and Shimura (1980), Wong and Lane (1983).
Details of the algorithms are provided in the section Clustering Methods.
For nonparametric clustering methods, a cluster is loosely defined as a region surrounding a local maximum of the probability density function (see the section Significance Tests for a more rigorous definition). Given a sufficiently large sample, nonparametric clustering methods are capable of detecting clusters of unequal size and dispersion and with highly irregular shapes. Nonparametric methods can also obtain good results for compact clusters of equal size and dispersion, but they naturally require larger sample sizes for good recovery than clustering methods that are biased toward finding such "nice" clusters.
For coordinate data, nonparametric clustering methods are less sensitive to changes in scale of the variables or to affine transformations of the variables than are most other commonly used clustering methods. Nevertheless, it is necessary to consider questions of scaling and transformation, since variables with large variances tend to have more of an effect on the resulting clusters than those with small variances. If two or more variables are not measured in comparable units, some type of standardization or scaling is necessary; otherwise, the distances used by the procedure might be based on inappropriate apples-and-oranges computations. For variables with comparable units of measurement, standardization or scaling might still be desirable if the scale estimates of the variables are not related to their expected importance for defining clusters. If you want two variables to have equal importance in the analysis, they should have roughly equal scale estimates. If you want one variable to have more of an effect than another, the former should be scaled to have a greater scale estimate than the latter. The STD option in the PROC MODECLUS statement scales all variables to equal variance. However, the variance is not necessarily the most appropriate scale estimate for cluster analysis. In particular, outliers should be removed before using PROC MODECLUS with the STD option. A variety of scale estimators including robust estimators are provided in the STDIZE procedure (for detailed information, see Chapter 82, The STDIZE Procedure ). Additionally, the ACECLUS procedure provides another way to transform the variables to try to improve the separation of clusters.
Since clusters are defined in terms of local maxima of the probability density function, nonlinear transformations of the data can change the number of population clusters. The variables should be transformed so that equal differences are of equal practical importance. An interval scale of measurement is required. Ordinal or ranked data are generally inappropriate, since monotone transformations can produce any arbitrary number of modes.
Unlike the methods in the CLUSTER procedure, the methods in the MODECLUS procedure are not inherently hierarchical. However, PROC MODECLUS can do approximate nonparametric significance tests for the number of clusters by obtaining an approximate -value for each cluster, and it can hierarchically join nonsignificant clusters.
Another important difference between the MODECLUS procedure and many other clustering methods is that you do not tell PROC MODECLUS how many clusters you want. Instead, you specify a smoothing parameter (see the section Density Estimation) and, optionally, a significance level, and PROC MODECLUS determines the number of clusters. You can specify a list of smoothing parameters, and PROC MODECLUS performs a separate cluster analysis for each value in the list.
Copyright © SAS Institute, Inc. All Rights Reserved.