| The KDE Procedure |
| Binning |
Binning, or assigning data to discrete categories, is an effective and fast method for large data sets (Fan and Marron; 1994). When the sample size  is large, direct evaluation of the kernel estimate
is large, direct evaluation of the kernel estimate  at any point would involve kernel evaluations, as shown in the preceding formulas. To evaluate the estimate at each point of a grid of size
at any point would involve kernel evaluations, as shown in the preceding formulas. To evaluate the estimate at each point of a grid of size 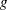 would thus require
would thus require  kernel evaluations. When you use
kernel evaluations. When you use  in the univariate case or
in the univariate case or  in the bivariate case and
in the bivariate case and  , the amount of computation can be prohibitively large. With binning, however, the computational order is reduced to , resulting in a much quicker algorithm that is nearly as accurate as direct evaluation.
, the amount of computation can be prohibitively large. With binning, however, the computational order is reduced to , resulting in a much quicker algorithm that is nearly as accurate as direct evaluation.
To bin a set of weighted univariate data  to a grid
to a grid  , simply assign each sample
, simply assign each sample  , together with its weight
, together with its weight  , to the nearest grid point
, to the nearest grid point  (also called the bin center). When binning is completed, each grid point
(also called the bin center). When binning is completed, each grid point  has an associated number
has an associated number  , which is the sum total of all the weights that correspond to sample points that have been assigned to . These s are known as the bin counts.
, which is the sum total of all the weights that correspond to sample points that have been assigned to . These s are known as the bin counts.
This procedure replaces the data 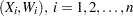 , with the smaller set
, with the smaller set  , and the estimation is carried out with these new data. This is so-called simple binning, versus the finer linear binning described in Wand (1994). PROC KDE uses simple binning for the sake of faster and easier implementation. Also, it is assumed that the bin centers
, and the estimation is carried out with these new data. This is so-called simple binning, versus the finer linear binning described in Wand (1994). PROC KDE uses simple binning for the sake of faster and easier implementation. Also, it is assumed that the bin centers  are equally spaced and in increasing order. In addition, assume for notational convenience that
are equally spaced and in increasing order. In addition, assume for notational convenience that  and, therefore,
and, therefore,  .
.
If you replace the data  , with
, with  , the weighted estimator
, the weighted estimator 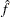 then becomes
then becomes
 |
with the same notation as used previously. To evaluate this estimator at the points of the same grid vector  is to calculate
is to calculate
 |
for  . This can be rewritten as
. This can be rewritten as
 |
where  is the increment of the grid.
is the increment of the grid.
The same idea of binning works similarly with bivariate data, where you estimate over the grid matrix  as follows:
as follows:
 |
where  , and the estimates are
, and the estimates are
 |
where  and
and  are the increments of the grid.
are the increments of the grid.
Copyright © SAS Institute, Inc. All Rights Reserved.