| The ANOVA Procedure |
| Output Data Set |
The OUTSTAT= option in the PROC ANOVA statement produces an output data set that contains the following:
the BY variables, if any
_TYPE_, a new character variable. This variable has the value ‘ANOVA’ for observations corresponding to sums of squares; it has the value ‘CANCORR’, ‘STRUCTUR’, or ‘SCORE’ if a canonical analysis is performed through the MANOVA statement and no M= matrix is specified.
_SOURCE_, a new character variable. For each observation in the data set, _SOURCE_ contains the name of the model effect from which the corresponding statistics are generated.
_NAME_, a new character variable. The variable _NAME_ contains the name of one of the dependent variables in the model or, in the case of canonical statistics, the name of one of the canonical variables (CAN1, CAN2, and so on).
four new numeric variables, SS, DF, F, and PROB, containing sums of squares, degrees of freedom,
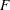 values, and probabilities, respectively, for each model or contrast sum of squares generated in the analysis. For observations resulting from canonical analyses, these variables have missing values.
values, and probabilities, respectively, for each model or contrast sum of squares generated in the analysis. For observations resulting from canonical analyses, these variables have missing values. if there is more than one dependent variable, then variables with the same names as the dependent variables represent
for _TYPE_=‘ANOVA’, the crossproducts of the hypothesis matrices
for _TYPE_=‘CANCORR’, canonical correlations for each variable
for _TYPE_=‘STRUCTUR’, coefficients of the total structure matrix
for _TYPE_=‘SCORE’, raw canonical score coefficients
The output data set can be used to perform special hypothesis tests (for example, with the IML procedure in SAS/IML software), to reformat output, to produce canonical variates (through the SCORE procedure), or to rotate structure matrices (through the FACTOR procedure).
Copyright © SAS Institute, Inc. All Rights Reserved.