| The TCALIS Procedure |
| Automatic Variable Selection |
When you specify your model, you use the main and subsidiary model statements to define variable relationships and parameters. PROC TCALIS checks the variables mentioned in these statements against the variable list of the input data set. If a variable in your model is also found in your data set, PROC TCALIS knows that it is a manifest variable. Otherwise, it is either a latent variable or an invalid variable.
To save computational resources, only manifest variables defined in your model are automatically selected for analysis. For example, even if you have 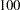 variables in your input data set, only a covariance matrix of
variables in your input data set, only a covariance matrix of 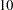 manifest variables is computed for the analysis of the model if only 10 variables are selected for analysis.
manifest variables is computed for the analysis of the model if only 10 variables are selected for analysis.
In some special circumstances, the automatic variable selection performed for the analysis might be a drawback. For example, if you are interested in modification indices connected to some of the variables that are not used in the model, automatic variable selection in the specification stage will exclude those variables from consideration in computing modification indices. Fortunately, a little trick can be done. You can use the VAR statement to include as many exogenous manifest variables as needed. Any variables in the VAR statement that are defined in the input data set but are not used in the main and subsidiary model specification statements are included in the model as exogenous manifest variables.
For example, the first three steps in a stepwise regression analysis of the Werner Blood Chemistry data (Jöreskog and Sörbom 1988, p. 111) can be performed as follows:
proc tcalis data=dixon method=gls nobs=180 print mod;
var x1-x7;
lineqs y = e;
std e = var;
run;
proc tcalis data=dixon method=gls nobs=180 print mod;
var x1-x7;
lineqs y = g1 x1 + e;
std e = var;
run;
proc tcalis data=dixon method=gls nobs=180 print mod;
var x1-x7;
lineqs y = g1 x1 + g6 x6 + e;
std e = var;
run;
In the first analysis, no independent manifest variables are included in the regression equation for dependent variable y. However, x1–x7 are specified in the VAR statement so that in computing the Lagrange multiplier tests these variables would be treated as potential predictors in the regression equation for dependent variable y. Similarly, in the next analysis, x1 is already a predictor in the regression equation, while x2–x7 are treated as potential predictors in the LM tests. In the last analysis, x1 and x6 are predictors in the regression equation, while other x-variables are treated as potential predictors in the LM tests.
Note: This procedure is experimental.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.