| The PHREG Procedure |
| PROC PHREG Statement |
You can specify the following options in the PROC PHREG statement.
- ALPHA=number
specifies the level of significance
 for
for 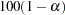 % confidence intervals. The value number must be between 0 and 1; the default value is 0.05, which results in 95% intervals. This value is used as the default confidence level for limits computed by the BASELINE, BAYES, CONTRAST, HAZARDRATIO, and MODEL statements. You can override this default by specifying the ALPHA= option in the separate statements.
% confidence intervals. The value number must be between 0 and 1; the default value is 0.05, which results in 95% intervals. This value is used as the default confidence level for limits computed by the BASELINE, BAYES, CONTRAST, HAZARDRATIO, and MODEL statements. You can override this default by specifying the ALPHA= option in the separate statements. - COVOUT
adds the estimated covariance matrix of the parameter estimates to the OUTEST= data set. The COVOUT option has no effect unless the OUTEST= option is specified.
- COVM
requests that the model-based covariance matrix (which is the inverse of the observed information matrix) be used in the analysis if the COVS option is also specified. The COVM option has no effect if the COVS option is not specified.
- COVSANDWICH <(AGGREGATE)>
- COVS <(AGGREGATE)>
requests the robust sandwich estimate of Lin and Wei (1989) for the covariance matrix. When this option is specified, this robust sandwich estimate is used in the Wald tests for testing the global null hypothesis, null hypotheses of individual parameters, and the hypotheses in the CONTRAST and TEST statements. In addition, a modified score test is computed in the testing of the global null hypothesis, and the parameter estimates table has an additional StdErrRatio column, which contains the ratios of the robust estimate of the standard error relative to the corresponding model-based estimate. Optionally, you can specify the keyword AGGREGATE enclosed in parentheses after the COVSANDWICH (or COVS) option, which requests a summing up of the score residuals for each distinct ID pattern in the computation of the robust sandwich covariance estimate. This AGGREGATE option has no effects if the ID statement is not specified.
- DATA=SAS-data-set
names the SAS data set containing the data to be analyzed. If you omit the DATA= option, the procedure uses the most recently created SAS data set.
- INEST=SAS-data-set
names the SAS data set that contains initial estimates for all the parameters in the model. BY-group processing is allowed in setting up the INEST= data set. See the section INEST= Input Data Set for more information.
- MULTIPASS
requests that, for each Newton-Raphson iteration, PROC PHREG recompile the risk sets corresponding to the event times for the (start,stop) style of response and recomputes the values of the time-dependent variables defined by the programming statements for each observation in the risk sets. If the MULTIPASS option is not specified, PROC PHREG computes all risk sets and all the variable values and saves them in a utility file. The MULTIPASS option decreases required disk space at the expense of increased execution time; however, for very large data, it might actually save time since it is time-consuming to write and read large utility files. This option has an effect only when the (start,stop) style of response is used or when there are time-dependent explanatory variables.
- NAMELEN=n
specifies the length of effect names in tables and output data sets to be n characters, where n is a value between 20 and 200. The default length is 20 characters.
- NOPRINT
suppresses all displayed output. Note that this option temporarily disables the Output Delivery System (ODS); see Chapter 20, Using the Output Delivery System, for more information.
- NOSUMMARY
suppresses the summary display of the event and censored observation frequencies.
- OUTEST=SAS-data-set
creates an output SAS data set that contains estimates of the regression coefficients. The data set also contains the convergence status and the log likelihood. If you use the COVOUT option, the data set also contains the estimated covariance matrix of the parameter estimators. See the section OUTEST= Output Data Set for more information.
- PLOTS<(global-plot-options)> = plot-request
- PLOTS<(global-plot-options)> = (plot-request <...<plot-request>>)
controls the baseline functions plots produced through ODS Graphics. Each observation in the COVARIATES= data set in the BASELINE statement represents a set of covariates for which a curve is produced for each plot request and for each stratum. You can use the ROWID= option in the BASELINE statement to specify a variable in the COVARIATES= data set for identifying the curves produced for the covariate sets. If the ROWID= option is not specified, the curves produced are identified by the covariate values if there is only a single covariate or by the observation numbers of the COVARIATES= data set if the model has two or more covariates. If the COVARIATES= data set is not specified, a reference set of covariates consisting of the reference levels for the CLASS variables and the average values for the continuous variables is used. For plotting more than one curve, you can use the OVERLAY= option to group the curves in separate plots. When you specify one plot request, you can omit the parentheses around the plot request. Here are some examples:
plots=survival plots=(survival cumhaz)
You must enable ODS Graphics before requesting plots, for example, like this:
ods graphics on; proc phreg plots(cl)=survival; model Time*Status(0)=X1-X5; baseline covariates=One; run; ods graphics off;The global plot options include the following:- CL<=EQTAIL | HPD>
displays the pointwise interval limits for the specified curves. For the classical analysis, CL displays the confidence limits. For the Bayesian analysis, CL=EQTAIL displays the equal-tail credible limits and CL=HPD displays the HPD limits. Specifying just CL in a Bayesian analysis defaults to CL=HPD.
- OVERLAY <=overlay-option>
- specifies how the curves for the various strata and covariate sets are overlaid. If the STRATA statement is not specified, specifying OVERLAY without any option will overlay the curves for all the covariate sets. The available overlay options are as follows:
- BYGROUP
- GROUP
overlays, for each stratum, all curves for the covariate sets that have the same GROUP= value in the COVARIATES= data set in the same plot.
- INDIVIDUAL
- IND
displays, for each stratum, a separate plot for each covariate set.
- BYROW
- ROW
displays, for each covariate set, a separate plot containing the curves for all the strata.
- BYSTRATUM
- STRATUM
displays, for each stratum, a separate plot containing the curves for all sets of covariates.
The default is OVERLAY=BYGROUP if the GROUP= option is specified in the BASELINE statement or if the COVARIATES= data set contains the _GROUP_ variable; otherwise the default is OVERLAY=INDIVIDUAL.
- TIMERANGE=(<min> <,max>)
- TIMERANGE=<min> <,max>
- RANGE=(<min> <,max>)
- RANGE=<min> <,max>
specifies the range of values on the time axis to clip the display. The min and max values are the lower and upper bounds of the range. By default, min is 0 and max is the largest event time.
The plot requests include the following:
- CUMHAZ
plots the estimated cumulative hazard function for each set of covariates in the COVARIATES= data set in the BASELINE statement. If the COVARIATES= data set is not specified, the estimated cumulative hazard function is plotted for the reference set of covariates consisting of reference levels for the CLASS variables and average values for the continuous variables.
- MCF
plots the estimated mean cumulative function for each set of covariates in the COVARIATES= data set in the BASELINE statement. If the COVARIATES= data set is not specified, the estimated mean cumulative function is plotted for the reference set of covariates consisting of reference levels for the CLASS variables and average values for the continuous variables.
- NONE
suppresses all the plots in the procedure. Specifying this option is equivalent to disabling ODS Graphics for the entire procedure.
- SURVIVAL
plots the estimated survivor function for each set of covariates in the COVARIATES= data set in the BASELINE statement. If COVARIATES= data set is not specified, the estimated survivor function is plotted for the reference set of covariates consisting of reference levels for the CLASS variables and average values for the continuous variables.
- SIMPLE
displays simple descriptive statistics (mean, standard deviation, minimum, and maximum) for each explanatory variable in the MODEL statement.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.