Summarizing Data
Overview of Summarizing Data
You
can use an aggregate function (or summary
function) to produce a statistical summary of data in a table. The
aggregate function instructs PROC SQL in how to combine data in one
or more columns. If you specify one column as the argument to an aggregate
function, then the values in that column are calculated. If you specify
multiple arguments, then the arguments or columns that are listed
are calculated.
Note: When more than one argument
is used within an SQL aggregate function, the function is no longer
considered to be an SQL aggregate or summary function. If there is
a like-named Base SAS function, then PROC SQL executes the Base SAS
function and the results that are returned are based on the values
for the current row. If no like-named Base SAS function exists, then
an error will occur. For example, if you use multiple arguments for
the AVG function, an error will occur because there is no AVG function
for Base SAS.
When you use an aggregate
function, PROC SQL applies the function to the entire table, unless
you use a GROUP BY clause. You can use aggregate functions in the
SELECT or HAVING clauses.
Note: See
Grouping Data for information about producing summaries of individual
groups of data within a table.
Summarizing Data with a WHERE Clause
Overview of Summarizing Data with a WHERE Clause
You can use aggregate, or summary functions, by using
a WHERE clause. For a complete list of the aggregate functions that
you can use, see Aggregate Functions.
Using the MEAN Function with a WHERE Clause
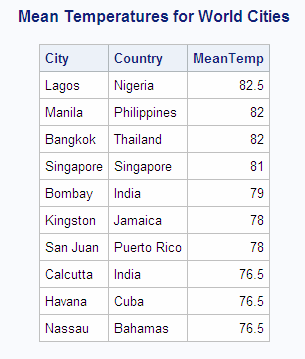
This
example uses the MEAN function to find the annual mean temperature
for each country in the SQL.WORLDTEMPS table. The WHERE clause returns
countries with a mean temperature that is greater than 75 degrees.
Displaying Sums
The following example uses the SUM function
to return the total oil reserves for all countries in the SQL.OILRSRVS
table:
libname sql 'SAS-library';
proc sql;
title 'World Oil Reserves';
select sum(Barrels) format=comma18. as TotalBarrels
from sql.oilrsrvs;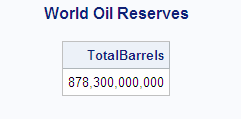
Combining Data from Multiple Rows into a Single Row
Remerging Summary Statistics
The following example uses
the MAX function to find the largest population in the SQL.COUNTRIES
table and displays it in a column called MaxPopulation. Aggregate
functions, such as the MAX function, can cause the same calculation
to repeat for every row. This occurs whenever PROC SQL remerges data.
Remerging occurs whenever any of the following conditions exist:
In this example, PROC
SQL writes the population of China, which is the largest population
in the table:
libname sql 'SAS-library';
proc sql outobs=12;
title 'Largest Country Populations';
select Name, Population format=comma20.,
max(Population) as MaxPopulation format=comma20.
from sql.countries
order by Population desc;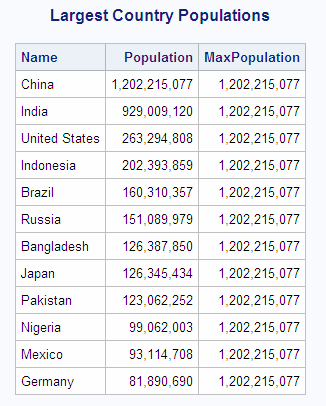
In some cases, you might
need to use an aggregate function so that you can use its results
in another calculation. To do this, you need only to construct one
query for PROC SQL to automatically perform both calculations. This
type of operation also causes PROC SQL to remerge the data.
For example, if you
want to find the percentage of the total world population that resides
in each country, then you construct a single query that performs the
following tasks:
PROC SQL runs an internal query to find the sum and
then runs another internal query to divide each country's population
by the sum.
libname sql 'SAS-library';
proc sql outobs=12;
title 'Percentage of World Population in Countries';
select Name, Population format=comma14.,
(Population / sum(Population) * 100) as Percentage
format=comma8.2
from sql.countries
order by Percentage desc;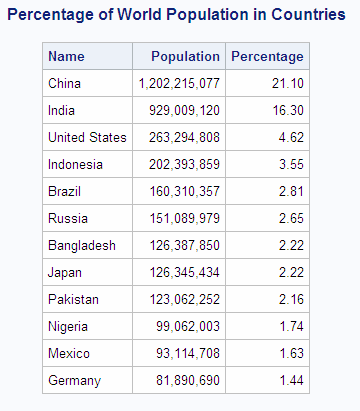
Using Aggregate Functions with Unique Values
Counting Unique Values
You can use DISTINCT
with an aggregate function to cause the function to use only unique
values from a column.
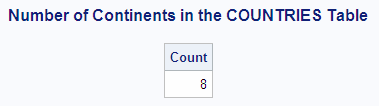
The following query
returns the number of distinct, nonmissing continents in the SQL.COUNTRIES
table:
Counting Nonmissing Values
Compare the previous example with the following query,
which does not use the DISTINCT keyword. This query counts every nonmissing
occurrence of a continent in the SQL.COUNTRIES table, including duplicate
values:
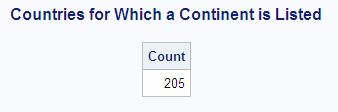
Counting All Rows
In the previous two
examples, countries that have a missing value in the Continent column
are ignored by the COUNT function. To obtain a count of all rows in
the table, including countries that are not on a continent, you can
use the following code in the SELECT clause:

Summarizing Data with Missing Values
Finding Errors Caused by Missing Values
The AVG function returns the average of only the nonmissing
values. The following query calculates the average length of three
features in the SQL.FEATURES table: Angel Falls and the Amazon and
Nile rivers:
libname sql 'SAS-library';
/* unexpected output */
proc sql;
title 'Average Length of Angel Falls, Amazon and Nile Rivers';
select Name, Length, avg(Length) as AvgLength
from sql.features
where Name in ('Angel Falls', 'Amazon', 'Nile');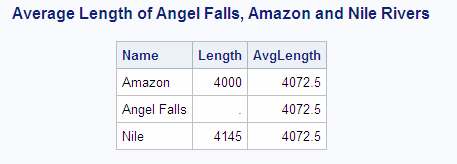
Because no length is
stored for Angel Falls, the average includes only the values for the
Amazon and Nile rivers. Therefore, the average contains unexpected
output results.
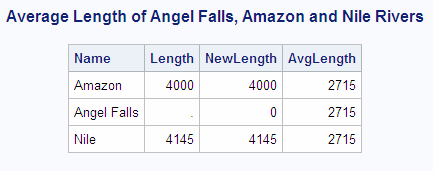
Compare the results
from the previous example with the following query, which includes
a COALESCE expression to handle missing values:
Copyright © SAS Institute Inc. All rights reserved.