SPD Server STARJOIN Facility
Overview of the SPD Server STARJOIN Facility
The SPD Server SQL Planner
includes the STARJOIN facility. The SPD Server STARJOIN facility validates,
optimizes, and executes SQL queries on data that is configured in
a star schema. Star schemas consist of two or more normalized dimension
tables that surround a centralized fact table. The centralized fact
table contains data elements of interest, which are derived from the
dimension tables.
In data warehouses with
large numbers of tables and millions or billions of rows of data,
a properly constructed STARJOIN can minimize overhead data redundancy
during query evaluation. If the SPD Server STARJOIN facility is not
enabled or if SPD Server SQL does not detect a star schema, then the
SQL is processed using pairwise joins.
How does a star join
differ from a pairwise join? In SPD Server, a properly configured
star join requires only three steps to complete, regardless of the
number of dimension tables. SPD Server pairwise joins require one
step for each table to complete the join. If a star schema consists
of 25 dimension tables and one fact table, the star join is accomplished
in three steps; joining the tables in the star schema using pairwise
joins requires 26 steps.
Star Schemas
Overview of Star Schemas
To exploit the SPD Server
STARJOIN facility, the data must be configured as a star schema, and
it must meet specific SPD Server SQL star schema requirements.
Star schemas are the
simplest data warehouse schema. They consist of a central fact table
that is surrounded by multiple normalized dimension tables. Fact tables
contain the measures of interest. Dimension tables provide detailed
information about the attributes within each dimension. The columns
that are in the fact tables are either foreign key columns that define
the links between the fact table and individual dimension tables,
or they are columns that calculate numeric values that are based on
foreign key data.
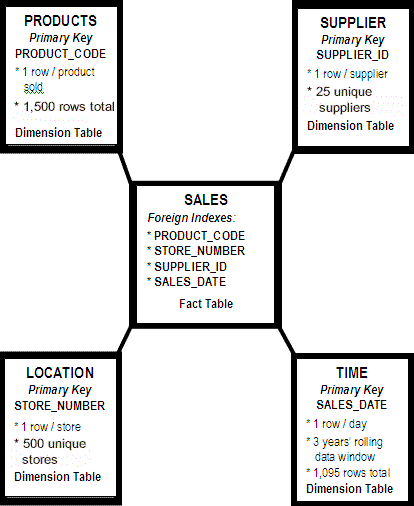
Example Dimension Tables Information
In the preceding figure,
the Products table contains information about products, with one row
per unique product SKU. The row for each unique SKU contains information
such as product name, height, width, depth, weight, pallet cube, and
so on. The Products table contains 1,500 rows.
The Supplier table contains
information about the suppliers that supply the products. The row
for each unique supplier contains information such as supplier name,
address, state, contact representative, and so on. The Supplier table
contains 25 rows.
Fact Table Information
The fact table Sales
is a table that combines information from the four dimension tables
(Products, Supplier, Location, and Time). Its foreign keys are imported,
one from each dimension table: PRODUCT_CODE from Products, STORE_NUMBER
from Location, SUPPLIER_ID from Supplier, and SALES_DATE from Time.
The fact table Sales might have other columns that contain facts or
information that is not found in any dimension table. Examples of
fact table columns that are not foreign keys from a dimension table
are columns such as QTY_SOLD or NET_SALES. The fact table in this
example can contain as many as 1,500 x 25 x 500 x 1,095 = 20,531,250,000
rows.
SPD Server STARJOIN Requirements
For SPD Server SQL to
take advantage of the STARJOIN Planner, the following conditions must
be true:
When you submit SPD
Server SQL that does not meet these STARJOIN conditions, SPD Server
performs the requested SQL task using SPD Server's pairwise join
strategy. For
examples that of valid, invalid, and restricted candidates for the
SPD Server STARJOIN facility, see SPD Server STARJOIN Examples.
Invoking the SPD Server STARJOIN Facility
SPD Server knows when
to use the STARJOIN facility because of the topology of the data and
the query. SPD Server invokes STARJOIN based on the SQL that you submit.
When you submit SQL and STARJOIN optimization is enabled, SPD Server
checks the SQL for admissible STARJOIN patterns. SPD Server SQL identifies
a fact table by scanning for a common equally joined table among multiple
join predicates in a WHERE clause. When SPD Server SQL detects patterns
that have multiple equally joined operators that share a common table,
the common table becomes the star schema's fact table.
Indexing Strategies to Optimize STARJOIN Query Performance
Overview of Indexing Strategies
When you have determined
the baseline criteria for creating an SQL STARJOIN in SPD Server,
you can configure the indexes to influence which strategy the SPD
Server STARJOIN facility chooses.
With the IN-SET strategy,
the SPD Server STARJOIN facility can use multiple simple indexes on
the fact table. The IN-SET strategy is the simplest to configure,
and usually provides the best performance. To configure your indexes
so that the STARJOIN facility chooses the IN-SET strategy, create
a simple index on each SQL column in the fact table and dimension
table that you want to use in a join relation. A simple index prevents
STARJOIN Phase I from rejecting a Phase I dimension table so that
it becomes a non-optimized Phase II table. Simple indexes also facilitate
the Phase II fact-table-to-dimension-table join lookup.
Indexing to Optimize the IN-SET Join Strategy
Consider the following
SQL code for a star schema with one fact table and two dimension tables:
PROC SQL; select F.FID, D1.DKEY, D2.DKEY from fact F, DIM1 D1, DIM2 D2 where D1.DKEY EQ F.D1KEY and D2.DKEY EQ F.D2KEY and D1.REGION EQ 'Midwest' and D2.PRODUCT EQ 'TV';
The SPD Server IN-SET
join strategy is the preferred strategy for almost every star join.
If you want the example code to trigger the IN-SET STARJOIN strategy,
create simple indexes on the join columns for the star schema's
fact table and dimension tables:
Indexing to Optimize the COMPOSITE Join Strategy
For the COMPOSITE join
strategy, the dimension tables with WHERE clause subsetting are collected
from the set of equally joined predicates. You need a composite index
for the fact table columns that correspond to the subsetted dimension
table columns. The composite index on the fact table is necessary
to facilitate the dimension tables' Cartesian product probes
on the fact table rows. The STARJOIN optimizer code looks for the
best composite index, based on the best and simplest left-to-right
match of the columns in the COMPOSITE join.
If the subsetting in
a star join is limited to a single dimension table, then you can enable
the COMPOSITE join strategy by creating a simple index on the join
column of the single dimension table.
For the example code
in Indexing to Optimize the IN-SET Join Strategy to
trigger the COMPOSITE STARJOIN strategy, create a composite index
named COMP1 on the fact table for each of the dimension table keys:
F.COMP1=(D1KEY D2KEY).
Other fact table and
dimension table indexes might exist that could filter WHERE clauses,
but you need the COMPOSITE index named COMP1 in order to enable the
STARJOIN COMPOSITE join strategy.
Although the COMPOSITE
join strategy might appear to be a simpler configuration, the strongest
utility of the COMPOSITE join strategy is limited to join relations
between the fact table and dimension tables. As the number of dimension
tables and join relations increases, the resulting increase in size
can become unmanageable. The performance of the IN-SET strategy is
robust enough that you should consider using the COMPOSITE join strategy
only if you have good evidence that it compares favorably with the
IN-SET strategy.
Example: Indexing Using the IN-SET Join Strategy
The example star schema
in Example Star Schema has four dimension tables (Supplier, Products, Location,
and Time) and one fact table (Sales). The schema has simple indexes
on the SUPPLIER_ID, PRODUCT_CODE, STORE_NUMBER, and SALES_DATE columns
in the Sales fact table.
Consider the following
SQL query to create a January sales report for an organization's
stores that are in North Carolina:
PROC SQL; select sum(s.sales_amt) as sales_amt sum(s.units_sold) as units_sold s.product)code, t.sales_month from spdslib.sales s, spdslib.supplier sup, spdslib.products p, spdslib.location l, spdslib.time t where s.store_number = l.store_number and s.sales_date = t.sales_date and s.product_code = p.product_code and s.supplier_id = sup.supplier_id and l.state = 'NC' and t.sales_date between '01JAN2005'd and '31JAN2005'd; quit;
During optimization,
the STARJOIN Planner examines the WHERE clause subsetting in the query
to determine which dimension tables are processed first.
The WHERE clause subsetting
of the STATE column of the Location dimension table (
where
... l.state = 'NC') and the subsetting of the
SALES_DATE column of the Time dimension table (where ...
t.sales_date between '01JAN2005'd and '31JAN2005'd)
cause SPD Server to process the Location and Time tables first. The
remaining dimension tables, Supplier and Products, are processed second.
The SPD Server STARJOIN
facility uses the first dimension tables to reduce the rows in the
fact table to candidate rows that contain the matching criteria. The
facility uses the values in each dimension table key to create a list
of values that meet the subsetting criteria of the fact table.
For example, the previous
SQL query is intended to create a January sales report for stores
located in North Carolina. The WHERE clause in the SQL code joins
the Location and Sales tables on the STORE_NUMBER column. Suppose
that there are 10 unique North Carolina stores, with consecutively
ordered STORE_NUMBER values that range from 101 to 110. When the WHERE
clause is evaluated, the results will include a list of the 10 North
Carolina store IDs that existed in January 2005.
Because the fact table
and dimension tables for the STORE_NUMBER column have simple indexes,
the STARJOIN facility chooses the IN-SET strategy. The facility subsets
the STATE column values to
'NC' in
order to build the set of store numbers that are associated with North
Carolina locations. The STARJOIN facility can use the set of North
Carolina store numbers to generate an SQLwhere ...
in expression. SQL uses the where ... in expression
to efficiently subset the candidate rows in the fact table before
the final SQL expression is evaluated.
Copyright © SAS Institute Inc. All rights reserved.