| Fit Analyses |
The Likelihood Function and Maximum-Likelihood Estimation
The log-likelihood function
- Normal
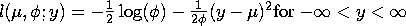
- Inverse Gaussian
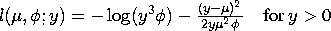
- Gamma
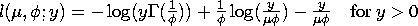
- Poisson
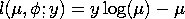 for y = 0, 1, 2, ...
for y = 0, 1, 2, ...
- Binomial
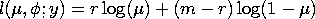
for y=r/m, r=0, 1, 2,..., m
Note |
Some terms in the density function have been dropped in the log-likelihood function since they do not affect the estimation of the mean and scale parameters. |
SAS/INSIGHT software uses a ridge stabilized Newton-Raphson algorithm to maximize the log-likelihood function l(
- b(r) = b(r-1) - H-1(r-1) u(r-1)
The Hessian matrix H can be expressed as
- H = - X' Wo X
SAS/INSIGHT software uses either the full Hessian matrix H = - X' Wo X or the Fisher's scoring method in the maximum-likelihood estimation. In the Fisher's scoring method, Wo is replaced by its expected value We with ith element wei.
- H = X' We X
The estimated variance-covariance matrix of the parameter estimates is
The estimated correlation matrix of the parameter estimates is derived by scaling the estimated variance-covariance matrix to 1 on the diagonal.
Note |
A warning message appears when the specified model fails to converge. The output tables, graphs, and variables are based on the results from the last iteration. |
Copyright © 2007 by SAS Institute Inc., Cary, NC, USA. All rights reserved.