Introduction to Optimization
The LP Procedure
A small product-mix problem serves as a starting point for a discussion of different types of model formats that are supported in SAS/OR software.
A candy manufacturer makes two products: chocolates and toffee. What combination of chocolates and toffee should be produced in a day in order to maximize the company’s profit? Chocolates contribute $0.25 per pound to profit, and toffee contributes $0.75 per pound. The decision variables are chocolates and toffee.
Four processes are used to manufacture the candy:
-
Process 1 combines and cooks the basic ingredients for both chocolates and toffee.
-
Process 2 adds colors and flavors to the toffee, then cools and shapes the confection.
-
Process 3 chops and mixes nuts and raisins, adds them to the chocolates, and then cools and cuts the bars.
-
Process 4 is packaging: chocolates are placed in individual paper shells; toffee is wrapped in cellophane packages.
During the day, there are 7.5 hours (27,000 seconds) available for each process.
Firm time standards have been established for each process. For Process 1, mixing and cooking take 15 seconds for each pound of chocolate, and 40 seconds for each pound of toffee. Process 2 takes 56.25 seconds per pound of toffee. For Process 3, each pound of chocolate requires 18.75 seconds of processing. In packaging, a pound of chocolates can be wrapped in 12 seconds, whereas a pound of toffee requires 50 seconds. These data are summarized as follows:
Available Required per Pound
Time chocolates toffee
Process (sec) (sec) (sec)
1 Cooking 27,000 15 40
2 Color/Flavor 27,000 56.25
3 Condiments 27,000 18.75
4 Packaging 27,000 12 50
The objective is to maximize the company’s total profit, which is represented as:
Maximize: 0.25(chocolates) + 0.75(toffee)
The production of the candy is limited by the time available for each process. The limits placed on production by Process 1 are expressed by the following inequality:
Process 1: 15(chocolates) + 40(toffee)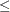 27,000
27,000
Process 1 can handle any combination of chocolates and toffee that satisfies this inequality.
The limits on production by other processes generate constraints described by the following inequalities:
Process 2: 56.25(toffee) 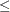 27,000
27,000
Process 3: 18.75(chocolates) 27,000
Process 4: 12(chocolates) + 50(toffee) 27,000
This sample linear program illustrates a product mix problem. The mix of products that maximizes the objective without violating the constraints is the solution. For input to PROC LP, this model can be represented in a SAS data set that uses either dense or sparse format.
Dense Format
The following DATA step creates a SAS data set for this product mix problem. Notice that the values of CHOCO and TOFFEE in the data set are the coefficients of those variables in the objective function and constraints. The variable _id_ contains a character string that names the rows in the data set. The variable _type_ is a character variable that contains keywords that describe the type of each row in the problem data set. The variable _rhs_ contains the right-hand-side values.
data factory; input _id_ $ CHOCO TOFFEE _type_ $ _rhs_; datalines; object 0.25 0.75 MAX . process1 15.00 40.00 LE 27000 process2 0.00 56.25 LE 27000 process3 18.75 0.00 LE 27000 process4 12.00 50.00 LE 27000 ;
To solve this problem by using PROC LP, specify the following:
proc lp data=factory; run;
Sparse Format
Typically, mathematical programming models are sparse; that is, few of the coefficients in the constraint matrix are nonzero. For this reason the LP procedure also accepts data in a sparse format SAS data set. In this format only the nonzero coefficients for the constraints and objective function must be specified.
An example of a sparse format data set is shown here. The following data set contains the data from the product mix problem of the preceding section.
data sp_factory; format _type_ $8. _row_ $10. _col_ $10.; input _type_ $_row_ $ _col_ $ _coef_; datalines; max object . . . object chocolate .25 . object toffee .75 le process1 . . . process1 chocolate 15 . process1 toffee 40 . process1 _RHS_ 27000 le process2 . . . process2 toffee 56.25 . process2 _RHS_ 27000 le process3 . . . process3 chocolate 18.75 . process3 _RHS_ 27000 le process4 . . . process4 chocolate 12 . process4 toffee 50 . process4 _RHS_ 27000 ;
To solve this problem by using PROC LP, specify the following:
proc lp data=sp_factory sparsedata; run;
The “Solution Summary” table (shown in Figure 2.1) contains information about the solution that was found, including whether the optimizer terminated successfully after finding the optimum.
PROC LP uses an iterative process to solve problems. First, the procedure finds a feasible solution that satisfies the constraints. Second, it finds an optimal solution from the set of feasible solutions. The “Solution Summary” table lists information about the optimization process such as the number of iterations, the infeasibilities of the solution, and the time required to solve the problem.
Figure 2.1: Solution Summary
| Solution Summary | |
|---|---|
|
Terminated Successfully |
|
| Objective Value | 475 |
| Phase 1 Iterations | 0 |
| Phase 2 Iterations | 3 |
| Phase 3 Iterations | 0 |
| Integer Iterations | 0 |
| Integer Solutions | 0 |
| Initial Basic Feasible Variables | 6 |
| Time Used (seconds) | 0 |
| Number of Inversions | 3 |
| Epsilon | 1E-8 |
| Infinity | 1.797693E308 |
| Maximum Phase 1 Iterations | 100 |
| Maximum Phase 2 Iterations | 100 |
| Maximum Phase 3 Iterations | 99999999 |
| Maximum Integer Iterations | 100 |
| Time Limit (seconds) | 120 |
Separating the Data from the Model Structure
It is often desirable to keep the data separate from the structure of the model. This is useful for large models with numerous identifiable components. The data are best organized in rectangular tables that can be easily examined and modified. Then, before the problem is solved, the model is built using the stored data. This process of model building is known as matrix generation. In conjunction with the sparse format used by the legacy procedures, the SAS DATA step provides a good matrix generation language.
For example, consider the candy manufacturing example introduced previously. Suppose that, for the user interface, it is more convenient to organize the data so that each record describes the information related to each product (namely, the contribution to the objective function and the unit amount needed for each process). A DATA step for saving the data might look like this:
data manfg; format product $12.; input product $ object process1 - process4 ; datalines; chocolate .25 15 0.00 18.75 12 toffee .75 40 56.25 0.00 50 licorice 1.00 29 30.00 20.00 20 jelly_beans .85 10 0.00 30.00 10 _RHS_ . 27000 27000 27000 27000 ;
Notice that there is a special record at the end that has product _RHS_. This record gives the amounts of time available for each of the processes. This information could have been stored in another data set. The next example illustrates a model in which the data are stored in separate data sets.
Building the model involves adding the data to the structure. There are as many ways to add data as there are programmers and problems. The following DATA step shows one way to use the candy data to build a sparse format model to solve the product mix problem:
data model;
array process {5} object process1-process4;
format _type_ $8. _row_ $12. _col_ $12. ;
keep _type_ _row_ _col_ _coef_;
set manfg; /* read the manufacturing data */
/* build the object function */
if _n_=1 then do;
_type_='max'; _row_='object'; _col_=' '; _coef_=.;
output;
end;
/* build the constraints */
do i=1 to 5;
if i>1 then do;
_type_='le'; _row_='process'||put(_i_-1,1.);
end;
else _row_='object';
_col_=product; _coef_=process[i];
output;
end;
run;
The sparse format data set is shown in Figure 2.2.
Figure 2.2: Sparse Data Format
| Obs | _type_ | _row_ | _col_ | _coef_ |
|---|---|---|---|---|
| 1 | max | object | . | |
| 2 | max | object | chocolate | 0.25 |
| 3 | le | process. | chocolate | 15.00 |
| 4 | le | process. | chocolate | 0.00 |
| 5 | le | process. | chocolate | 18.75 |
| 6 | le | process. | chocolate | 12.00 |
| 7 | object | toffee | 0.75 | |
| 8 | le | process. | toffee | 40.00 |
| 9 | le | process. | toffee | 56.25 |
| 10 | le | process. | toffee | 0.00 |
| 11 | le | process. | toffee | 50.00 |
| 12 | object | licorice | 1.00 | |
| 13 | le | process. | licorice | 29.00 |
| 14 | le | process. | licorice | 30.00 |
| 15 | le | process. | licorice | 20.00 |
| 16 | le | process. | licorice | 20.00 |
| 17 | object | jelly_beans | 0.85 | |
| 18 | le | process. | jelly_beans | 10.00 |
| 19 | le | process. | jelly_beans | 0.00 |
| 20 | le | process. | jelly_beans | 30.00 |
| 21 | le | process. | jelly_beans | 10.00 |
| 22 | object | _RHS_ | . | |
| 23 | le | process. | _RHS_ | 27000.00 |
| 24 | le | process. | _RHS_ | 27000.00 |
| 25 | le | process. | _RHS_ | 27000.00 |
| 26 | le | process. | _RHS_ | 27000.00 |
The model data set looks a little different from the sparse representation of the candy model shown earlier. It not only includes additional
products (licorice and jelly beans), but it also defines the model in a different order. Since the sparse format is robust,
the model can be generated in ways that are convenient for the DATA step program.
If the problem had more products, you could increase the size of the manfg data set to include the new product data. Also, if the problem had more than four processes, you could add the new process
variables to the manfg data set and increase the size of the process array in the model data set. With these two simple changes and additional data, a product mix problem that has hundreds of processes and products
can be modeled and solved.