The NETFLOW Procedure
This statement invokes the procedure. The following options and the options listed with the RESET statement can appear in the PROC NETFLOW statement.
This section briefly describes all the input and output data sets used by PROC NETFLOW. The ARCDATA=
data set, NODEDATA=
data set, and CONDATA=
data set can contain SAS variables that have special names, for instance _CAPAC_, _COST_, and _HEAD_. PROC NETFLOW looks for such variables if you do not give explicit variable list specifications. If a SAS variable with a
special name is found and that SAS variable is not in another variable list specification, PROC NETFLOW determines that values
of the SAS variable are to be interpreted in a special way. By using SAS variables that have special names, you may not need
to have any variable list specifications.
The following is a list of options you can use with PROC NETFLOW. The options are listed in alphabetical order.
- ALLART
-
indicates that PROC NETFLOW uses an all artificial initial solution (Kennington and Helgason 1980, p. 68) instead of the default good path method for determining an initial solution (Kennington and Helgason 1980, p. 245). The ALLART initial solution is generally not as good; more iterations are usually required before the optimal solution is obtained. However, because less time is used when setting up an ALLART start, it can offset the added expenditure of CPU time in later computations.
- ARCS_ONLY_ARCDATA
-
indicates that data for only arcs are in the ARCDATA= data set. When PROC NETFLOW reads the data in ARCDATA= data set, memory would not be wasted to receive data for nonarc variables. The read might then be performed faster. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- ARC_SINGLE_OBS
-
indicates that for all arcs and nonarc variables, data for each arc or nonarc variable is found in only one observation of the ARCDATA= data set. When reading the data in the ARCDATA= data set, PROC NETFLOW knows that the data in an observation is for an arc or a nonarc variable that has not had data previously read that needs to be checked for consistency. The read might then be performed faster.
If you specify ARC_SINGLE_OBS, PROC NETFLOW automatically works as if GROUPED= ARCDATA is also specified. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
-
BYPASSDIVIDE=b
BYPASSDIV=b
BPD=b -
should be used only when the MAXFLOW option has been specified; that is, PROC NETFLOW is solving a maximal flow problem. PROC NETFLOW prepares to solve maximal flow problems by setting up a bypass arc. This arc is directed from the SOURCE to the SINK and will eventually convey flow equal to INFINITY minus the maximal flow through the network. The cost of the bypass arc must be expensive enough to drive flow through the network, rather than through the bypass arc. However, the cost of the bypass arc must be less than the cost of artificial variables (otherwise these might have nonzero optimal value and a false infeasibility error will result). Also, the cost of the bypass arc must be greater than the eventual total cost of the maximal flow, which can be nonzero if some network arcs have nonzero costs. The cost of the bypass is set to the value of the INFINITY= option. Valid values for the BYPASSDIVIDE= option must be greater than or equal to 1.1.
If there are no nonzero costs of arcs in the MAXFLOW problem, the cost of the bypass arc is set to 1.0 (-1.0 if maximizing) if you do not specify the BYPASSDIVIDE= option. The reduced costs in the ARCOUT= data set and the CONOUT= data set will correctly reflect the value that would be added to the maximal flow if the capacity of the arc is increased by one unit. If there are nonzero costs, or if you specify the BYPASSDIVIDE= option, the reduced costs may be contaminated by the cost of the bypass arc and no economic interpretation can be given to reduced cost values. The default value for the BYPASSDIVIDE= option (in the presence of nonzero arc costs) is 100.0.
- BYTES=b
-
indicates the size of the main working memory (in bytes) that PROC NETFLOW will allocate. The default value for the BYTES= option is near to the number of bytes of the largest contiguous memory that can be allocated for this purpose. The working memory is used to store all the arrays and buffers used by PROC NETFLOW. If this memory has a size smaller than what is required to store all arrays and buffers, PROC NETFLOW uses various schemes that page information between memory and disk.
PROC NETFLOW uses more memory than the main working memory. The additional memory requirements cannot be determined at the time when the main working memory is allocated. For example, every time an output data set is created, some additional memory is required. Do not specify a value for the BYTES= option equal to the size of available memory.
- CON_SINGLE_OBS
-
improves how the CONDATA= data set is read. How it works depends on whether the CONDATA has a dense or sparse format.
If CONDATA has the dense format, specifying CON_SINGLE_OBS indicates that, for each constraint, data can be found in only one observation of CONDATA.
If CONDATA has a sparse format, and data for each arc and nonarc variable can be found in only one observation of CONDATA, then specify the CON_SINGLE_OBS option. If there are n SAS variables in the ROW and COEF list, then each arc or nonarc can have at most n constraint coefficients in the model. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
-
COREFACTOR=c
CF=c -
enables you to specify the maximum proportion of memory to be used by the arrays frequently accessed by PROC NETFLOW. PROC NETFLOW strives to maintain all information required during optimization in core. If the amount of available memory is not great enough to store the arrays completely in core, either initially or as memory requirements grow, PROC NETFLOW can change the memory management scheme it uses. Large problems can still be solved. When necessary, PROC NETFLOW transfers data from random access memory (RAM) or core that can be accessed quickly but is of limited size to slower access large capacity disk memory. This is called paging.
Some of the arrays and buffers used during constrained optimization either vary in size, are not required as frequently as other arrays, or are not required throughout the simplex iteration. Let a be the amount of memory in bytes required to store frequently accessed arrays of nonvarying size. Specify the MEMREP option in the PROC NETFLOW statement to get the value for a and a report of memory usage. If the size of the main working memory BYTES= b multiplied by COREFACTOR=c is greater than a, PROC NETFLOW keeps the frequently accessed arrays of nonvarying size resident in core throughout the optimization. If the other arrays cannot fit into core, they are paged in and out of the remaining part of the main working memory.
If b multiplied by c is less than a, PROC NETFLOW uses a different memory scheme. The working memory is used to store only the arrays needed in the part of the algorithm being executed. If necessary, these arrays are read from disk into the main working area. Paging, if required, is done for all these arrays, and sometimes information is written back to disk at the end of that part of the algorithm. This memory scheme is not as fast as the other memory schemes. However, problems can be solved with memory that is too small to store every array.
PROC NETFLOW is capable of solving very large problems in a modest amount of available memory. However, as more time is spent doing input/output operations, the speed of PROC NETFLOW decreases. It is important to choose the value of the COREFACTOR= option carefully. If the value is too small, the memory scheme that needs to be used might not be as efficient as another that could have been used had a larger value been specified. If the value is too large, too much of the main working memory is occupied by the frequently accessed, nonvarying sized arrays, leaving too little for the other arrays. The amount of input/output operations for these other arrays can be so high that another memory scheme might have been used more beneficially.
The valid values of COREFACTOR=c are between 0.0 and 0.95, inclusive. The default value for c is 0.75 when there are over 200 side constraints, and 0.9 when there is only one side constraint. When the problem has between 2 and 200 constraints, the value of c lies between the two points (1, 0.9) and (201, 0.75).
-
DEFCAPACITY=c
DC=c -
requests that the default arc capacity and the default nonarc variable value upper bound be c. If this option is not specified, then DEFCAPACITY= INFINITY .
-
DEFCONTYPE=c
DEFTYPE=c
DCT=c -
specifies the default constraint type. This default constraint type is either less than or equal to or is the type indicated by DEFCONTYPE=c. Valid values for this option are
- LE, le,
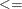
-
for less than or equal to
- EQ, eq, =
-
for equal to
- GE, ge,
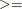
-
for greater than or equal to
The values do not need to be enclosed in quotes.
- LE, le,
- DEFCOST=c
-
requests that the default arc cost and the default nonarc variable objective function coefficient be c. If this option is not specified, then DEFCOST=0.0.
-
DEFMINFLOW=m
DMF=m -
requests that the default lower flow bound through arcs and the default lower value bound of nonarc variables be m. If a value is not specified, then DEFMINFLOW=0.0.
- DEMAND=d
-
specifies the demand at the SINK node specified by the SINK= option. The DEMAND= option should be used only if the SINK= option is given in the PROC NETFLOW statement and neither the SHORTPATH option nor the MAXFLOW option is specified. If you are solving a minimum cost network problem and the SINK= option is used to identify the sink node, but the DEMAND= option is not specified, then the demand at the sink node is made equal to the network’s total supply.
- DWIA=i
-
controls the initial amount of memory to be allocated to store the LU factors of the working basis matrix. DWIA stands for
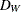 initial allocation and i is the number of nonzeros and matrix row operations in the LU factors that can be stored in this memory. Due to fill-in in the U factor and the growth in the number of row operations, it is often necessary to move information about elements of a particular
row or column to another location in the memory allocated for the LU factors. This process leaves some memory temporarily unoccupied. Therefore, DWIA=i must be greater than the memory required to store only the LU factors.
initial allocation and i is the number of nonzeros and matrix row operations in the LU factors that can be stored in this memory. Due to fill-in in the U factor and the growth in the number of row operations, it is often necessary to move information about elements of a particular
row or column to another location in the memory allocated for the LU factors. This process leaves some memory temporarily unoccupied. Therefore, DWIA=i must be greater than the memory required to store only the LU factors.
Occasionally, it is necessary to compress the U factor so that it again occupies contiguous memory. Specifying too large a value for DWIA means that more memory is required by PROC NETFLOW. This might cause more expensive memory mechanisms to be used than if a smaller but adequate value had been specified for DWIA=. Specifying too small a value for the DWIA= option can make time-consuming compressions more numerous. The default value for the DWIA= option is eight times the number of side constraints.
- EXCESS=option
-
enables you to specify how to handle excess supply or demand in a network, if it exists.
For pure networks EXCESS=ARCS and EXCESS=SLACKS are valid options. By default EXCESS=ARCS is used. Note that if you specify EXCESS=SLACKS, then the interior point solver is used and you need to specify the output data set using the CONOUT= data set. For more details see the section Using the New EXCESS= Option in Pure Networks: NETFLOW Procedure.
For generalized networks you can either specify EXCESS=DEMAND or EXCESS=SUPPLY to indicate that the network has excess demand or excess supply, respectively. For more details see the section Using the New EXCESS= Option in Generalized Networks: NETFLOW Procedure.
- GENNET
-
This option is necessary if you need to solve a generalized network flow problem and there are no arc multipliers specified in the ARCDATA= data set.
- GROUPED=grouped
-
PROC NETFLOW can take a much shorter time to read data if the data have been grouped prior to the PROC NETFLOW call. This enables PROC NETFLOW to conclude that, for instance, a new NAME list variable value seen in an ARCDATA= data set grouped by the values of the NAME list variable before PROC NETFLOW was called is new. PROC NETFLOW does not need to check that the NAME has been read in a previous observation. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
-
GROUPED=ARCDATA indicates that the ARCDATA= data set has been grouped by values of the NAME list variable. If
_NAME_is the name of the NAME list variable, you could use PROC SORT DATA=ARCDATA; BY _NAME_; prior to calling PROC NETFLOW. Technically, you do not have to sort the data, only ensure that all similar values of the NAME list variable are grouped together. If you specify the ARCS_ONLY_ARCDATA option, PROC NETFLOW automatically works as if GROUPED=ARCDATA is also specified. -
GROUPED=CONDATA indicates that the CONDATA= data set has been grouped.
If the CONDATA= data set has a dense format, GROUPED=CONDATA indicates that the CONDATA= data set has been grouped by values of the ROW list variable. If
_ROW_is the name of the ROW list variable, you could use PROC SORT DATA=CONDATA; BY _ROW_; prior to calling PROC NETFLOW. Technically, you do not have to sort the data, only ensure that all similar values of the ROW list variable are grouped together. If you specify the CON_SINGLE_OBS option, or if there is no ROW list variable, PROC NETFLOW automatically works as if GROUPED=CONDATA has been specified.If the CONDATA= data set has the sparse format, GROUPED=CONDATA indicates that the CONDATA= data set has been grouped by values of the COLUMN list variable. If
_COL_is the name of the COLUMN list variable, you could use PROC SORT DATA=CONDATA; BY _COL_; prior to calling PROC NETFLOW. Technically, you do not have to sort the data, only ensure that all similar values of the COLUMN list variable are grouped together. -
GROUPED=BOTH indicates that both GROUPED=ARCDATA and GROUPED=CONDATA are TRUE.
-
GROUPED=NONE indicates that the data sets have not been grouped, that is, neither GROUPED=ARCDATA nor GROUPED=CONDATA is TRUE. This is the default, but it is much better if GROUPED=ARCDATA, or GROUPED=CONDATA, or GROUPED=BOTH.
A data set like
... _XXXXX_ .... bbb bbb aaa ccc cccis a candidate for the GROUPED= option. Similar values are grouped together. When PROC NETFLOW is reading the ith observation, either the value of the
_XXXXX_variable is the same as the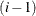 st (that is, the previous observation’s)
st (that is, the previous observation’s) _XXXXX_value, or it is a new_XXXXX_value not seen in any previous observation. This also means that if the ith_XXXXX_value is different from thest _XXXXX_value, the value of thest _XXXXX_variable will not be seen in any observations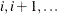 .
.
-
-
INFINITY=i
INF=i -
is the largest number used by PROC NETFLOW in computations. A number too small can adversely affect the solution process. You should avoid specifying an enormous value for the INFINITY= option because numerical roundoff errors can result. If a value is not specified, then INFINITY=99999999. The INFINITY= option cannot be assigned a value less than 9999.
- INTPOINT
-
indicates that the interior point algorithm is to be used. The INTPOINT option must be specified if you want the interior point algorithm to be used for solving network problems, otherwise the simplex algorithm is used instead. For linear programming problems (problems with no network component), PROC NETFLOW must use the interior point algorithm, so you need not specify the INTPOINT option.
- INVD_2D
-
controls the way in which the inverse of the working basis matrix is stored. How this matrix is stored affects computations as well as how the working basis or its inverse is updated. The working basis matrix is defined in the section Details: NETFLOW Procedure. If INVD_2D is specified, the working basis matrix inverse is stored as a matrix. Typically, this memory scheme is best when there are few side constraints or when the working basis is dense.
If INVD_2D is not specified, lower (L) and upper (U) factors of the working basis matrix are used. U is an upper triangular matrix and L is a lower triangular matrix corresponding to a sequence of elementary matrix row operations. The sparsity-exploiting variant of the Bartels-Golub decomposition is used to update the LU factors. This scheme works well when the side constraint coefficient matrix is sparse or when many side constraints are nonbinding.
- MAXARRAYBYTES=m
-
specifies the maximum number of bytes an individual array can occupy. This option is of most use when solving large problems and the amount of available memory is insufficient to store all arrays at once. Specifying the MAXARRAYBYTES= option ensures that arrays that need a large amount of memory do not consume too much memory at the expense of other arrays.
There is one array that contains information about nodes and the network basis spanning tree description. This tree description enables computations involving the network part of the basis to be performed very quickly and is the reason why PROC NETFLOW is more suited to solving constrained network problems than PROC LP. It is beneficial that this array be stored in core when possible, otherwise this array must be paged, slowing down the computations. Try not to specify a MAXARRAYBYTES=m value smaller than the amount of memory needed to store the main node array. You are told what this memory amount is on the SAS log if you specify the MEMREP option in the PROC NETFLOW statement.
-
MAXFLOW
MF -
specifies that PROC NETFLOW solve a maximum flow problem. In this case, the PROC NETFLOW procedure finds the maximum flow from the node specified by the SOURCE= option to the node specified by the SINK= option. PROC NETFLOW automatically assigns an INFINITY= option supply to the SOURCE= option node and the SINK= option is assigned the INFINITY= option demand. In this way, the MAXFLOW option sets up a maximum flow problem as an equivalent minimum cost problem.
You can use the MAXFLOW option when solving any flow problem (not necessarily a maximum flow problem) when the network has one supply node (with infinite supply) and one demand node (with infinite demand). The MAXFLOW option can be used in conjunction with all other options (except SHORTPATH , SUPPLY= , and DEMAND= ) and capabilities of PROC NETFLOW.
-
MAXIMIZE
MAX -
specifies that PROC NETFLOW find the maximum cost flow through the network. If both the MAXIMIZE and the SHORTPATH options are specified, the solution obtained is the longest path between the SOURCE= and SINK= nodes. Similarly, MAXIMIZE and MAXFLOW together cause PROC NETFLOW to find the minimum flow between these two nodes; this is zero if there are no nonzero lower flow bounds.
- MEMREP
-
indicates that information on the memory usage and paging schemes (if necessary) is reported by PROC NETFLOW on the SAS log. As optimization proceeds, you are informed of any changes in the memory requirements and schemes used by PROC NETFLOW.
- NAMECTRL=i
-
is used to interpret arc and nonarc variable names in the CONDATA= data set.
In the ARCDATA= data set, an arc is identified by its tail and head node. In the CONDATA= data set, arcs are identified by names. You can give a name to an arc by having a NAME list specification that indicates a SAS variable in the ARCDATA= data set that has names of arcs as values.
PROC NETFLOW requires arcs that have information about them in the CONDATA= data set to have names, but arcs that do not have information about them in the CONDATA= data set can also have names. Unlike a nonarc variable whose name uniquely identifies it, an arc can have several different names. An arc has a default name in the form tail_head, that is, the name of the arc’s tail node followed by an underscore and the name of the arc’s head node.
In the CONDATA= data set, if the dense data format is used, (described in the section CONDATA= Data Set) a name of an arc or a nonarc variable is the name of a SAS variable listed in the VAR list specification. If the sparse data format of the CONDATA= data set is used, a name of an arc or a nonarc variable is a value of the SAS variable listed in the COLUMN list specification.
The NAMECTRL= option is used when a name of an arc or nonarc variable in the CONDATA= data set (either a VAR list SAS variable name or value of the COLUMN list SAS variable) is in the form tail_head and there exists an arc with these end nodes. If tail_head has not already been tagged as belonging to an arc or nonarc variable in the ARCDATA= data set, PROC NETFLOW needs to know whether tail_head is the name of the arc or the name of a nonarc variable.
If you specify NAMECTRL=1, a name that is not defined in the ARCDATA= data set is assumed to be the name of a nonarc variable. NAMECTRL=2 treats tail_head as the name of the arc with these endnodes, provided no other name is used to associate data in the CONDATA= data set with this arc. If the arc does have other names that appear in the CONDATA= data set, tail_head is assumed to be the name of a nonarc variable. If you specify NAMECTRL=3, tail_head is assumed to be a name of the arc with these end nodes, whether the arc has other names or not. The default value of NAMECTRL is 3. Note that if you use the dense side constraint input format, the default arc name tail_head is not recognized (regardless of the NAMECTRL value) unless the head node and tail node names contain no lowercase letters.
If the dense format is used for the CONDATA= data set, the SAS System converts SAS variable names in a SAS program to uppercase. The VAR list variable names are uppercased. Because of this, PROC NETFLOW automatically uppercases names of arcs and nonarc variables (the values of the NAME list variable) in the ARCDATA= data set. The names of arcs and nonarc variables (the values of the NAME list variable) appear uppercased in the ARCOUT= data set and the CONOUT= data set, and in the PRINT statement output.
Also, if the dense format is used for the CONDATA= data set, be careful with default arc names (names in the form
tailnode_headnode). Node names (values in the TAILNODE and HEADNODE list variables) in the ARCDATA= data set are not uppercased by PROC NETFLOW. Consider the following code:data arcdata; input _from_ $ _to_ $ _name $ ; datalines; from to1 . from to2 arc2 TAIL TO3 . ; data densecon; input from_to1 from_to2 arc2 tail_to3; datalines; 2 3 3 5 ; proc netflow arcdata=arcdata condata=densecon; run;
The SAS System does not uppercase character string values. PROC NETFLOW never uppercases node names, so the arcs in observations 1, 2, and 3 in the preceding ARCDATA= data set have the default names "from_to1", "from_to2", and "TAIL_TO3", respectively. When the dense format of the CONDATA= data set is used, PROC NETFLOW does uppercase values of the NAME list variable, so the name of the arc in the second observation of the ARCDATA= data set is "ARC2". Thus, the second arc has two names: its default "from_to2" and the other that was specified "ARC2".
As the SAS System does uppercase program code, you must think of the input statement
input from_to1 from_to2 arc2 tail_to3;
as really being
INPUT FROM_TO1 FROM_TO2 ARC2 TAIL_TO3;
The SAS variables named "FROM_TO1" and "FROM_TO2" are not associated with any of the arcs in the preceding ARCDATA= data set. The values "FROM_TO1" and "FROM_TO2" are different from all of the arc names "from_to1", "from_to2", "TAIL_TO3", and "ARC2". "FROM_TO1" and "FROM_TO2" could end up being the names of two nonarc variables. It is sometimes useful to specify PRINT NONARCS ; before commencing optimization to ensure that the model is correct (has the right set of nonarc variables).
The SAS variable named "ARC2" is the name of the second arc in the ARCDATA= data set, even though the name specified in the ARCDATA= data set looks like "arc2". The SAS variable named "TAIL_TO3" is the default name of the third arc in the ARCDATA= data set.
- NARCS=n
-
specifies the approximate number of arcs. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- NCOEFS=n
-
specifies the approximate number of constraint coefficients. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- NCONS=n
-
specifies the approximate number of constraints. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- NNAS=n
-
specifies the approximate number of nonarc variables. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- NNODES=n
-
specifies the approximate number of nodes. See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- NON_REPLIC=non_replic
-
prevents PROC NETFLOW from doing unnecessary checks of data previously read.
See the section How to Make the Data Read of PROC NETFLOW More Efficient.
- RHSOBS=charstr
-
specifies the keyword that identifies a right-hand-side observation when using the sparse format for data in the CONDATA= data set. The keyword is expected as a value of the SAS variable in the CONDATA= data set named in the COLUMN list specification. The default value of the RHSOBS= option is _RHS_ or _rhs_. If charstr is not a valid SAS variable name, enclose it in single quotes.
-
SAME_NONARC_DATA
SND -
If all nonarc variable data are given in the ARCDATA= data set, or if the problem has no nonarc variables, the unconstrained warm start can be read more quickly if the option SAME_NONARC_DATA is specified. SAME_NONARC_DATA indicates that any nonconstraint nonarc variable data in the CONDATA= data set is to be ignored. Only side constraint data in the CONDATA= data set are read.
If you use an unconstrained warm start and SAME_NONARC_DATA is not specified, any nonarc variable objective function coefficient, upper bound, or lower bound can be changed. Any nonarc variable data in the CONDATA= data set overrides (without warning messages) corresponding data in the ARCDATA= data set. You can possibly introduce new nonarc variables to the problem, that is, nonarc variables that were not in the problem when the warm start was generated.
SAME_NONARC_DATA should be specified if nonarc variable data in the CONDATA= data set are to be deliberately ignored. Consider
proc netflow options arcdata=arc0 nodedata=node0 condata=con0 /* this data set has nonarc variable */ /* objective function coefficient data */ future1 arcout=arc1 nodeout=node1; run; data arc2; reset arc1; /* this data set has nonarc variable obs */ if _cost_<50.0 then _cost_=_cost_*1.25; /* some objective coefficients of nonarc */ /* variable might be changed */ proc netflow options warm arcdata=arc2 nodedata=node1 condata=con0 same_nonarc_data /* This data set has old nonarc variable */ /* obj, fn. coefficients. same_nonarc_data */ /* indicates that the "new" coefs in the */ /* arcdata=arc2 are to be used. */ run; - SCALE=scale
-
indicates that the side constraints are to be scaled. Scaling is useful when some coefficients of a constraint or nonarc variable are either much larger or much smaller than other coefficients. Scaling might make all coefficients have values that have a smaller range, and this can make computations more stable numerically. Try the SCALE= option if PROC NETFLOW is unable to solve a problem because of numerical instability. Specify
-
SCALE=ROW, SCALE=CON, or SCALE=CONSTRAINT if the largest absolute value of coefficients in each constraint is about 1.0
-
SCALE=COL, SCALE=COLUMN, or SCALE=NONARC if nonarc variable columns are scaled so that the absolute value of the largest constraint coefficient of a nonarc variable is near to 1
-
SCALE=BOTH if the largest absolute value of coefficients in each constraint, and the absolute value of the largest constraint coefficient of a nonarc variable is near to 1. This is the default.
-
-
SHORTPATH
SP -
specifies that PROC NETFLOW solve a shortest path problem. The NETFLOW procedure finds the shortest path between the nodes specified in the SOURCE= option and the SINK= option. The costs of arcs are their lengths. PROC NETFLOW automatically assigns a supply of one flow unit to the SOURCE= node, and the SINK= node is assigned to have a one flow unit demand. In this way, the SHORTPATH option sets up a shortest path problem as an equivalent minimum cost problem.
If a network has one supply node (with supply of one unit) and one demand node (with demand of one unit), you could specify the SHORTPATH option, with the SOURCE= and SINK= nodes, even if the problem is not a shortest path problem. You then should not provide any supply or demand data in the NODEDATA= data set or the ARCDATA= data set.
-
SINK=sinkname
SINKNODE=sinkname -
identifies the demand node. The SINK= option is useful when you specify the MAXFLOW option or the SHORTPATH option and need to specify toward which node the shortest path or maximum flow is directed. The SINK= option also can be used when a minimum cost problem has only one demand node. Rather than having this information in the ARCDATA= data set or the NODEDATA= data set, use the SINK= option with an accompanying DEMAND= specification for this node. The SINK= option must be the name of a head node of at least one arc; thus, it must have a character value. If the value of the SINK= option is not a valid SAS character variable name, it must be enclosed in single quotes and can contain embedded blanks.
-
SOURCE=sourcename
SOURCENODE=sourcename -
identifies a supply node. The SOURCE= option is useful when you specify the MAXFLOW or the SHORTPATH option and need to specify from which node the shortest path or maximum flow originates. The SOURCE= option also can be used when a minimum cost problem has only one supply node. Rather than having this information in the ARCDATA= data set or the NODEDATA= data set, use the SOURCE= option with an accompanying SUPPLY= amount of supply at this node. The SOURCE= option must be the name of a tail node of at least one arc; thus, it must have a character value. If the value of the SOURCE= option is not a valid SAS character variable name, it must be enclosed in single quotes and can contain embedded blanks.
-
SPARSECONDATA
SCDATA -
indicates that the CONDATA= data set has data in the sparse data format. Otherwise, it is assumed that the data are in the dense format.
Note: If the SPARSECONDATA option is not specified, and you are running SAS software Version 6 or you have specified options validvarname=v6;, all NAME list variable values in the ARCDATA= data set are uppercased. See the section Case Sensitivity.
-
SPARSEP2
SP2 -
indicates that the new column of the working basis matrix that replaces another column be held in a linked list. If the SPARSEP2 option is not specified, a one-dimensional array is used to store this column’s information, that can contain elements that are 0.0 and use more memory than the linked list. The linked list mechanism requires more work if the column has numerous nonzero elements in many iterations. Otherwise, it is superior. Sometimes, specifying SPARSEP2 is beneficial when the side constrained coefficient matrix is very sparse or when some paging is necessary.
- SUPPLY=s
-
specifies the supply at the source node specified by the SOURCE= option. The SUPPLY= option should be used only if the SOURCE= option is given in the PROC NETFLOW statement and neither the SHORTPATH option nor the MAXFLOW option is specified. If you are solving a minimum cost network problem and the SOURCE= option is used to identify the source node and the SUPPLY= option is not specified, then by default the supply at the source node is made equal to the network’s total demand.
- THRUNET
-
tells PROC NETFLOW to force through the network any excess supply (the amount by which total supply exceeds total demand) or any excess demand (the amount by which total demand exceeds total supply) as is required. If a network problem has unequal total supply and total demand and the THRUNET option is not specified, PROC NETFLOW drains away the excess supply or excess demand in an optimal manner. The consequences of specifying or not specifying THRUNET are discussed in the section Balancing Total Supply and Total Demand.
- TYPEOBS=charstr
-
specifies the keyword that identifies a type observation when using the sparse format for data in the CONDATA= data set. The keyword is expected as a value of the SAS variable in the CONDATA= data set named in the COLUMN list specification. The default value of the TYPEOBS= option is _TYPE_ or _type_. If charstr is not a valid SAS variable name, enclose it in single quotes.
- WARM
-
indicates that the NODEDATA= data set or the DUALIN= data set and the ARCDATA= data set contain extra information of a warm start to be used by PROC NETFLOW. See the section Warm Starts.