Combining SAS Data Sets: Basic Concepts
What You Need to Know Before Combining Information Stored in Multiple SAS Data Sets
Many applications require
input data to be in a specific format before the data can be processed
to produce meaningful results. The data typically comes from multiple
sources and might be in different formats. Therefore, you often, if
not always, have to take intermediate steps to logically relate and
process data before you can analyze it or create reports from it.
The Four Ways That Data Can Be Related
Data Relationship Categories
Relationships among multiple
sources of input data exist when each of the sources contains common
data, either at the physical or logical level. For example, employee
data and department data could be related through an employee ID variable
that shares common values. Another data set could contain numeric
sequence numbers whose partial values logically relate it to a separate
data set by observation number.
You must be able to
identify the existing relationships in your data. This knowledge is
crucial for understanding how to process input data in order to produce
desired results. All related data fall into one of these four categories,
characterized by how observations relate among the data sets:
To obtain the results
that you want, you should understand how each of these methods combines
observations, how each method treats duplicate values of common variables,
and how each method treats missing values or nonmatched values of
common variables. Some of the methods also require that you preprocess
your data sets by sorting them or by creating indexes. See the description
of each method in Combining SAS Data Sets: Methods.
One-to-One Relationship
In a one-to-one relationship, typically a single observation
in one data set is related to a single observation from another based
on the values of one or more selected variables. A one-to-one relationship
implies that each value of the selected variable occurs no more than
once in each data set. When you work with multiple selected variables,
this relationship implies that each combination of values occurs no
more than once in each data set.
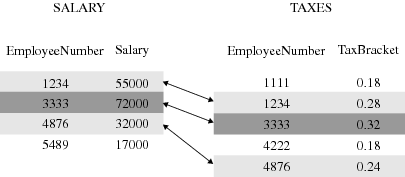
One-to-Many and Many-to-One Relationships
A one-to-many
or many-to-one relationship between input data sets implies that one
data set has at most one observation with a specific value of the
selected variable, but the other input data set can have more than
one occurrence of each value. When you work with multiple selected
variables, this relationship implies that each combination of values
occurs no more than once in one data set. However, the combination
can occur more than once in the other data set. The order in which
the input data sets are processed determines whether the relationship
is one-to-many or many-to-one.
In the following example,
observations in data sets ONE and TWO are related by common values
for variable A. Values of A are unique in data set ONE but not in
data set TWO.
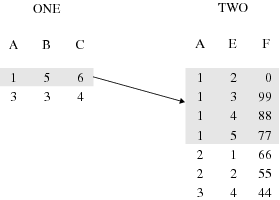
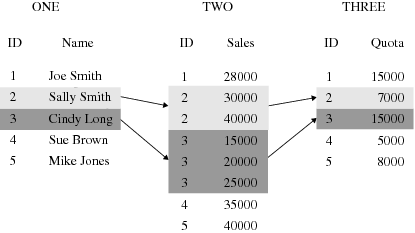
In the following example,
observations in data sets ONE, TWO, and THREE are related by common
values for variable ID. Values of ID are unique in data sets ONE and
THREE but not in TWO. For values 2 and 3 of ID, a one-to-many relationship
exists between observations in data sets ONE and TWO, and a many-to-one
relationship exists between observations in data sets TWO and THREE.
Many-to-Many Relationships
The many-to-many category implies that multiple observations
from each input data set can be related based on values of one or
more common variables.
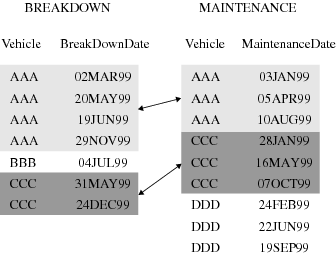
Access Methods: Sequential versus Direct
Overview
Once you have established
data relationships, the next step is to determine the best mode of
data access to relate the data. You can access observations sequentially
in the order in which they appear in the physical file. Or you can
access them directly. That is, you can go straight to an observation
in a SAS data set without having to process each observation that
precedes it.
Sequential Access
The simplest and perhaps most common way to process
data with a DATA step is to read observations in a data set sequentially.
You can read observations sequentially using the SET, MERGE, UPDATE,
or MODIFY statements. You can also use the SAS File I/O functions.
OPEN, FETCH, and FETCHOBS are examples.
Direct Access
To access observations
directly by their observation number, use the POINT= option with
the SET or MODIFY statement. The POINT= option names a variable whose
current value determines which observation a SET or MODIFY statement
reads.
To access observations
directly based on the values of one or more specified variables, you
must first create an index for the variables and then read the data
set using the KEY= statement option with the SET or MODIFY statement.
An index is a separate structure that contains the data values of
the key variable or variables, paired with a location identifier for
the observations containing the value.
Overview of Methods for Combining SAS Data Sets
Concatenating
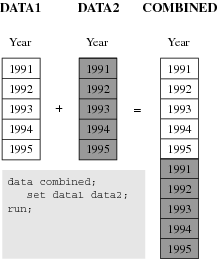
The
following figure shows the results of concatenating two SAS data sets.
Concatenating the data sets appends the observations from one data
set to another data set. The DATA step reads DATA1 sequentially until
all observations have been processed, and then reads DATA2. Data set
COMBINED contains the results of the concatenation. Note that the
data sets are processed in the order in which they are listed in the
SET statement.
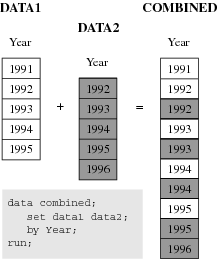
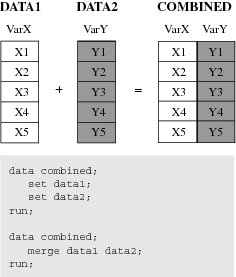
One-to-One Reading and One-to-One Merging
The following
figure shows the results of one-to-one reading and one-to-one merging.
One-to-one reading combines observations from two or more SAS data
sets by creating observations that contain all of the variables from
each contributing data set. Observations are combined based on their
relative position in each data set, that is, the first observation
in one data set with the first in the other, and so on. The DATA step
stops after it has read the last observation from the smallest data
set. One-to-one merging is similar to a one-to-one reading, with two
exceptions: you use the MERGE statement instead of multiple SET statements,
and the DATA step reads all observations from all data sets. Data
set COMBINED shows the result.

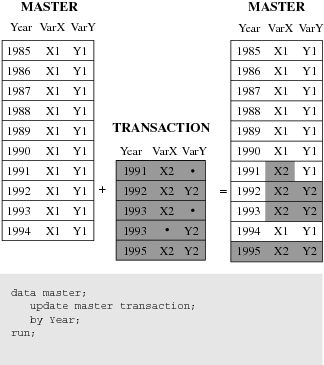
Updating
The
following figure shows the results of updating a master data set.
Updating uses information from observations in a transaction data
set to delete, add, or alter information in observations in a master
data set. You can update a master data set by using the UPDATE statement
or the MODIFY statement. If you use the UPDATE statement, your input
data sets must be sorted by the values of the variables listed in
the BY statement. (In this example, MASTER and TRANSACTION are both
sorted by Year.) If you use the MODIFY statement, your input data
does not need to be sorted.
UPDATE replaces an existing
file with a new file, allowing you to add, delete, or rename columns.
MODIFY performs an update in place by rewriting only those records
that have changed, or by appending new records to the end of the file.
Overview of Tools for Combining SAS Data Sets
Using Statements and Procedures
Once you understand the basics
of establishing relationships among data, the ways to access data,
and the ways that you can combine SAS data sets, you can choose from
a variety of SAS tools for accessing, combining, and processing your
data. The following table lists and briefly describes the DATA step
statements and the procedures that you can use for combining SAS data
sets.
Statements or Procedures for Combining SAS Data Sets
|
PROC SQL1
|
|||||
| 1PROC SQL is the SAS implementation of Structured Query Language. In addition to expected SQL capabilities, PROC SQL includes additional capabilities specific to SAS, such as the use of formats and SAS macro language. | |||||
Using Error Checking
You can use the _IORC_ automatic variable and the SYSRC
autocall macro to perform error checking in a DATA step. Use these
tools with the MODIFY statement or with the SET statement and the
KEY= option. For more information about these tools, see
Error Checking When Using Indexes to Randomly Access or Update Data.
How to Prepare Your Data Sets
Guidelines to Prepare Your Data Sets
Knowing the Structure and Contents of the Data Sets
To help determine how your
data is related, look at the structure of the data sets. To see the
data set structure, execute the DATASETS procedure, the CONTENTS procedure,
or access the SAS Explorer window in your
windowing environment to display the descriptor information. Descriptor
information includes the number of observations in each data set,
the name and attributes of each variable, and which variables are
included in indexes. To print a sample of the observations, use the
PRINT procedure or the REPORT procedure.
You can also use functions
such as VTYPE, VLENGTH, and VLENGTHX to show specific descriptor information.
For complete information about these functions, see SAS Functions and CALL Routines: Reference.
Looking at Sources of Common Problems
If your program does not execute correctly, review
your input data for the following errors:
-
-
If the length attribute is different, SAS takes the length from the first data set that contains the variable. In the following example, all data sets that are listed in the MERGE statement contain the variable Mileage. In QUARTER1, the length of the variable Mileage is four bytes; in QUARTER2, it is eight bytes and in QUARTER3 and QUARTER4, it is six bytes. In the output data set YEARLY, the length of the variable Mileage is four bytes, which is the length derived from QUARTER1.
data yearly; merge quarter1 quarter2 quarter3 quarter4; by Account; run;
To override the default and set the length yourself, specify the appropriate length in a LENGTH statement that precedes the SET, MERGE, or UPDATE statement.Note: If the length of a variable changes as a result of combining data sets, SAS prints a warning message to the log and issues a nonzero return code (for example, onz/OS , SYSRC=4). If you expect truncation of data (for example, when removing insignificant blanks from the end of character values), the warning is expected and you do not want SAS to issue a nonzero return code. In this case, you can turn this warning off by setting the VARLENCHK system option to NOWARN. For more information, see VARLENCHK= System Option in SAS System Options: Reference. -
If any of these attributes are different, SAS takes the attribute from the first data set that contains the variable with that attribute. However, any label, format, or informat that you explicitly specify overrides a default. If all data sets contain explicitly specified attributes, the one specified in the first data set overrides the others. To ensure that the new output data set has the attributes that you prefer, use an ATTRIB statement.You can also use the SAS File I/O functions such as VLABEL, VLABELX, and other Variable Information functions to access this information. For complete information about these functions, see SAS Functions and CALL Routines: Reference.
Ensuring Correct Order
If you use BY-group processing with
the UPDATE, SET, and MERGE statements to combine data sets, ensure
that the observations in the data sets are sorted in the order of
the variables that are listed in the BY statement, or that the data
sets have an appropriate index. If you use BY-group processing in
a MODIFY statement, your data does not need to be sorted, but sorting
the data improves efficiency. The BY variable or variables must be
common to both data sets, and they must have the same attributes.
For more information, see BY-Group Processing in the DATA Step.
Testing Your Program
As a final step in preparing your
data sets, you should test your program. Create small temporary SAS
data sets that contain a sample of observations that test all of your
program's logic. If your logic is faulty and you get unexpected output,
you can use the DATA step debugger to debug your program. For complete
information about the DATA Step Debugger, see SAS Data Set Options: Reference.