High Volume Access to Smaller Tables
Applicability and Special Considerations
The information about
providing high-volume access to smaller tables applies to distributed
servers only.
A distributed server
scales to handle large tables by adding more machines to the cluster.
This is commonly referred to as scaling horizontally. However, for
smaller tables, adding more machines to the cluster to support a large
number of concurrent users is not effective. Every request for data
requires communication between the machines in the server to process
the request. For smaller tables, typically less than 20G, the time
spent in communication is large compared to the computation time of
the request.
The SAS LASR Analytic Server
2.6 release introduces a strategy for high-volume requests for smaller
tables. The following sections provide more details.
Depictions of Data Distribution
The following figure
shows the conventional method of data distribution for a distributed
server. As data are read with the LASR procedure or the SAS LASR Analytic Server engine,
rows are distributed in a round-robin pattern to the machines in the
cluster. (There is one exception—for partitioned tables, all
the rows with the same partition key are placed on a single machine.)
This results in an even workload and best performance for most scenarios.
Conventional Data Distribution
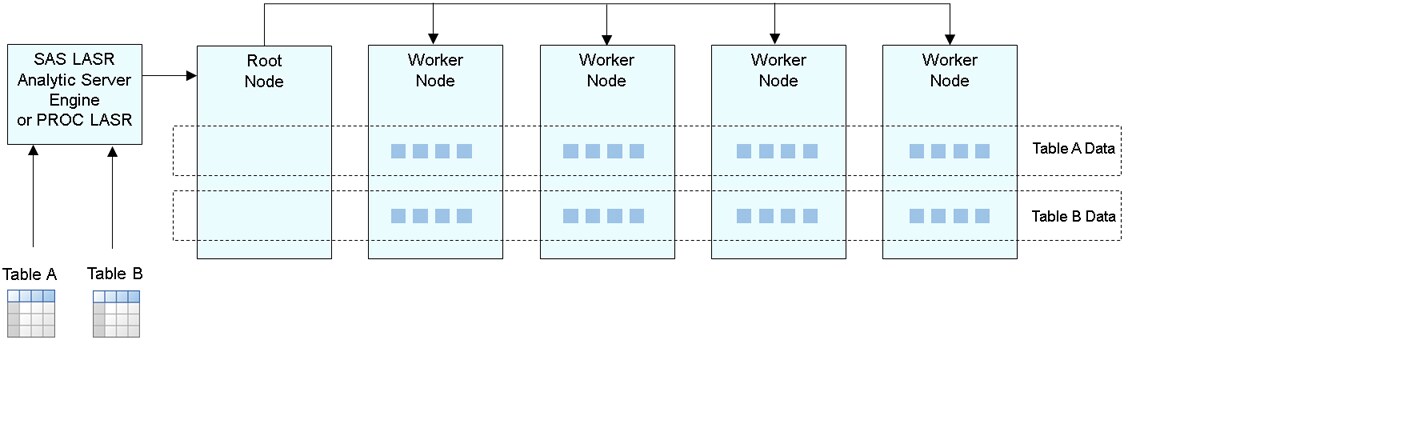
The following figure
represents the strategy for providing high-volume access to smaller
tables. The rows from the tables are distributed in the same conventional
fashion as before. However, a non-distributed server is started on
each of the machines and a full copy of the smaller tables is loaded
into a user-specified number of servers.
Full Copies of Tables Using Non-Distributed Servers

As the root node accepts requests for data access to one of the smaller tables, the root node directs
the request to one of the non-distributed servers with the table. Because a non-distributed
server has a full copy of the table, it can process the request independent of other
machines. The results are then sent back through the root node to the client.
Sample Code
The following shows
an example of using the FULLCOPYTO= option with the LASR procedure.
You can use the option with co-located SASHDAT files or with a libref
to any SAS engine.
options set=GRIDHOST="grid001.example.com" set=GRIDINSTALLLOC="/opt/TKGrid_REP"; libname hdfs sashdat path="/hps"; proc lasr add data=hdfs.iris fullcopyto=3 port=10010 ; run; libname example sasiola port=10010 tag="hps"; data example.prdsale(fullcopyto=5); set sashelp.prdsale; run; proc imstat; table example._T_TABLEMEMORY; where childsmptablememory > 0 and (tablename eq "HPS.IRIS" or tablename eq "HPS.PRDSALE"); fetch hostname tablename childsmptablememory / format; quit;
The results of the
FETCH statement are shown in the following figure. The Iris table
is on three machines and the Prdsale table is on machines. These results
were generated on a cluster that has more than 8 machines. As a result,
no machine has more than one full copy of a table. If the cluster
were smaller or if the FULLCOPYTO= value were increased, then the
results would show a host with more than one table.
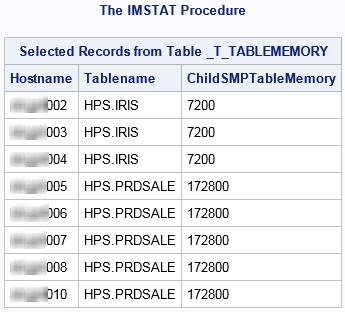
Requests for the Iris
table are load-balanced across machines 002 to 004. Requests for the
Prdsale table are load-balanced across machines 005 to 010. Information
about the _T_TABLEMEMORY table is provided in
Memory Management.
Details
-
Requests for a table are load-balanced across the machines that have a full copy of the table.
-
Programming statements (or requests from applications like SAS Visual Analytics) that create temporary tables result in creating a temporary table on the non-distributed server only. Subsequent requests for data from the temporary table are directed to the same non-distributed server.
-
The DROPTABLE statement runs on the distributed server first and then any non-distributed servers that have full copies.
-
The PROMOTE statement results in a regular in-memory table on the distributed server and the non-distributed server that had the temporary table.
-
The tables provide Read-Only access. Statements that attempt to modify the table, such as UPDATE, return an error.
-
Statements that use more than one input table (such as the SCHEMA statement) run on the distributed server only. If an input table exists on a non-distributed server, then the table is sent to the distributed server before the processing begins.
-
Some statements can run in the distribute server only, such as the SAVE statement. For these statements, if the table exists on a non-distributed server only, then the table is sent to the distributed server before the processing begins.
-
The non-distributed servers continue to run until the distributed server is stopped.
-
The non-distributed servers do not generate any logging records. If you have enabled logging, the log for the distributed server includes the requests that it handles and the requests that are sent to the non-distributed servers.
For information about
enabling high-volume access to smaller tables in a metadata environment,
see SAS Visual Analytics: Administration Guide.
Copyright © SAS Institute Inc. All rights reserved.