MapR Distribution for Apache Hadoop
How Does SAS LASR Analytic Server Work with MapR?
The machines that are
used for SAS LASR Analytic Server
act as NFS clients to mount the MapR cluster. No client software is
required.
At installation time,
there is a configuration prompt that is related to specifying the
mount point, such as
/mapr/my.cluster.com.
When the path is specified, SAS LASR Analytic Server
and the SAS Data in HDFS engine
(SASHDAT engine) use the specified path as a root directory path.
For example, if the directory /mapr/my.cluster.com/hps exists
and /mapr/my.cluster.com was specified
as the mount point, then the following SASHDAT engine LIBNAME statement
refers to the /hps directory:
options set=GRIDHOST="grid001.example.com" set=GRIDINSTALLLOC="/opt/TKGrid"; libname hps sashdat path="/hps";
How is working with MapR different from working with HDFS?
Working with MapR instead of HDFS is largely transparent. All the benefits of working
with HDFS apply to working with
MapR.
-
SAS programs that use the SAS Data in HDFS engine to distribute data can run without modification.
-
SAS programs that use the LASR procedure to load tables from HDFS can load data over the NFS mounts from MapR without modification.
From an architectural or network topology standpoint, a deployment that is co-located
with HDFS has to run the server on every machine in the Hadoop cluster. With MapR,
the number
of machines used for the server does not need to be the same as the number of machines
used for MapR. The use of NFS also means that the server can be co-located and use
the same machines as MapR or the MapR cluster can be remote. In either case, NFS provides
the advantages of co-located data access.
Sample Code
The following code sample
shows how the following components are used with the MapR distribution:
-
SAS LASR Analytic Server engine
-
SAS Data in HDFS engine
-
LASR procedure
-
IMSTAT procedure
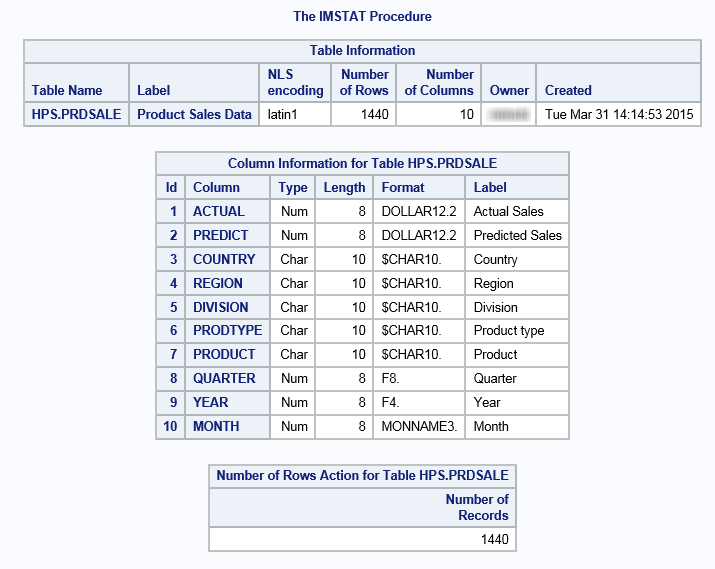
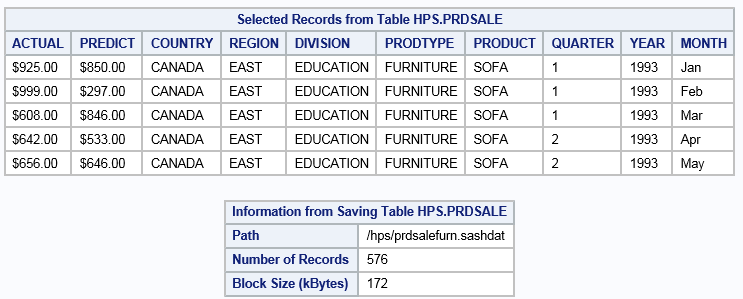
options set=GRIDHOST="grid001.example.com" set=GRIDINSTALLLOC="/opt/TKGrid"; proc lasr create port=10010; performance nodes=all; run; libname example sasiola tag="hps" port=10010; 1 libname hps sashdat path="/hps"; 2 data hps.prdsale(squeeze=yes copies=2); 3 set sashelp.prdsale; run; /* proc datasets lib=hps; 4 quit; */ proc lasr add data=hps.prdsale noclass port=10010; 5 run; proc imstat data=example.prdsale; tableinfo; columninfo; numrows; fetch / format to=5; 6 run; where prodtype="FURNITURE"; save path="/hps/prdsalefurn.sashdat" fullpath copies=2; 7 run; quit;
| 1 | The
example libref is created. It references the server that was started
with the PROC LASR CREATE statement. The libref uses TAG="hps"
because the PATH= option in the next step is a directory named /hps.
|
| 2 | The
Hps libref references the /hps directory
in MapR-FS. No special options are required to work with MapR.
|
| 3 | A DATA step is used to distribute the Sashelp.Prdsale data set. All SASHDAT engine data set options are supported. No special options are required to work with MapR. |
| 4 | You can use the DATASETS procedure to list the SASHDAT tables. The engine ignores files that are not SASHDAT tables. |
| 5 | The LASR procedure loads the table to memory from MapR transparently over the NFS mounts. |
| 6 | The example libref is used with the IMSTAT procedure to reference the in-memory table. All the analytic and management capabilities of the server are available to operate on the in-memory table. |
| 7 | The WHERE clause sets a limit on the Prodtype variable. The SAVE statement creates a new SASHDAT table in MapR-FS that include observations that pass the WHERE clause. |
Results for PROC LASR ADD

Results for TABLEINFO, COLUMNINFO, and NUMROWS
Results for FETCH and SAVE
Copyright © SAS Institute Inc. All rights reserved.