LIBNAME Statement Syntax
Associates a SAS libref with SASHDAT tables stored in HDFS.
| Valid in: | Anywhere |
| Category: | Data Access |
Syntax
Required Arguments
libref
is a valid SAS name that serves as a shortcut name to associate with the SASHDAT tables that are stored in the Hadoop Distributed File System (HDFS). The name must conform to the rules for SAS names. A libref cannot exceed eight characters.
SASHDAT
is the engine name for the SAS Data in HDFS engine.
Optional Arguments
COPIES=n
specifies the number of replications to make for the data set (beyond the original blocks). The default value is 2 when the INNAMEONLY option is specified and otherwise is 1. Replicated blocks are used to provide fault tolerance for HDFS. If a machine in the cluster becomes unavailable, then the blocks needed for the SASHDAT file can be retrieved from replications on other machines. If you specify COPIES=0, then the original blocks are distributed, but no replications are made and there is no fault tolerance for the data.
HOST="grid-host"
specifies the grid host that has a running Hadoop NameNode. Enclose the host name in quotation marks. If you do not specify the HOST= option, it is determined from the GRIDHOST= environment variable.
INNAMEONLY= YES | NO
specifies that when data is added to HDFS, that it should be sent as a single block to the Hadoop NameNode for distribution. This option is appropriate for smaller data sets.
| Alias | NODIST |
INSTALL="grid-install-location"
specifies the path to the TKGrid software on the grid host. If you do not specify this option, it is determined from the GRIDINSTALLLOC= environment variable.
NODEFAULTFORMAT= YES | NO
specifies whether a default format that is applied to a variable is reported by the engine.
PATH="HDFS-path"
specifies the fully qualified path to the HDFS directory to use for SASHDAT files. You do not need to specify this option in the LIBNAME statement because it can be specified as a data set option.
VERBOSE= YES | NO
specifies whether the engine accepts and reports extra messages from TKGrid. For more information, see the VERBOSE= option for the SAS LASR Analytic Server engine.
Examples
Example 1: Submitting a LIBNAME Statement Using the Defaults
Program
option set=GRIDHOST="grid001.example.com"; 1 option set GRIDINSTALLLOC="/opt/TKGrid"; libname hdfs sashdat; 2
NOTE: Libref HDFS was successfully assigned as follows:
Engine: SASHDAT
Physical Name: grid001.example.com
Program Description
-
The host name for the Hadoop NameNode is specified in the GRIDHOST environment variable.
-
The LIBNAME statement uses host name from the GRIDHOST environment variable and the path to TKGrid from the GRIDINSTALLLOC environment variable. The PATH= and COPIES= options can be specified as data set options.
Example 2: Submitting a LIBNAME Statement Using the HOST=, INSTALL=, and PATH= Options
libname hdfs sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/user/sasdemo";NOTE: Libref HDFS was successfully assigned as follows:
Engine: SASHDAT
Physical Name: Directory '/user/sasdemo' of HDFS cluster on host
grid001.example.com
Example 3: Adding Tables to HDFS
libname arch "/data/archive";
libname hdfs sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/dept";
data hdfs.allyears(label="Sales records for previous years"
replace=yes blocksize=32m);
set arch.sales2012
arch.sales2011
...
;
run;Example 4: Adding a Table to HDFS with Partitioning
libname hdfs sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/dept";
data hdfs.prdsale(partition=(year month) orderby=(descending prodtype));
set sashelp.prdsale;
run;Example 5: Removing Tables from HDFS
libname hdfs sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/dept";
proc datasets lib=hdfs;
delete allyears;
run;NOTE: Deleting HDFS.ALLYEARS (memtype=DATA).
Example 6: Creating a SASHDAT File from Another SASHDAT File
libname hdfs sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/dept";
proc hpds2
in = hdfs.allyears(where=(region=212)) 1
out = hdfs.avgsales(blocksize=32m copies=0); 2
data DS2GTF.out;
dcl double avgsales;
method run();
set DS2GTF.in;
avgsales = avg(month1-month12);
end;
enddata;
run;| 1 | The WHERE clause is used to subset the data in the input SASHDAT file. |
| 2 | The BLOCKSIZE= and COPIES= options are used to override the default values. |
Example 7: Working with CSV Files
List the Variables in a CSV File
libname csvfiles sashdat host="grid001.example.com" install="/opt/TKGrid"
path="/user/sasdemo/csv";
proc contents data=csvfiles.rep(filetype=csv getnames=yes);
run;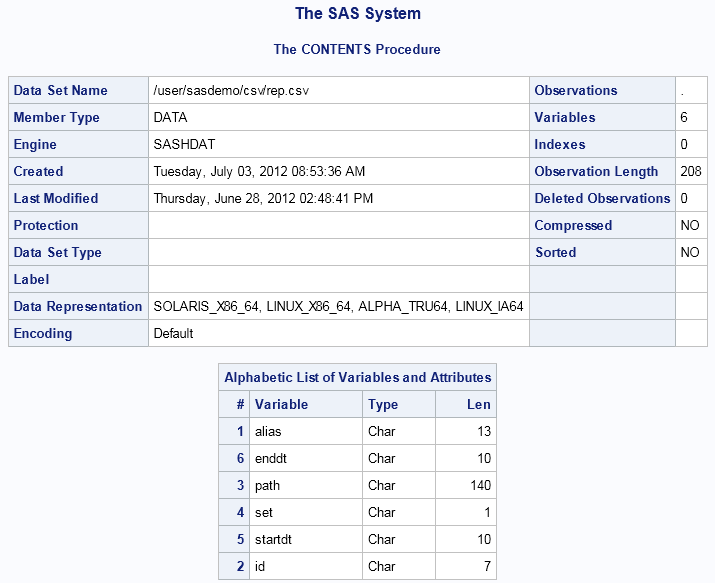
Convert a CSV File to SASHDAT
option set=GRIDHOST="grid001.example.com"; 1 option set=GRIDINSTALLLOC="/opt/TKGrid"; libname csvfiles sashdat path="/user/sasdemo/csv"; proc hpds2 in=csvfiles.rep(filetype=csv getnames=yes) 2 out=csvfiles.rephdat(path="/user/sasdemo" copies=0 blocksize=32m); 3 data DS2GTF.out; method run(); set DS2GTF.in; end; enddata; run;
| 1 | The values for the GRIDHOST and GRIDINSTALLLOC environment variables are read by the SAS Data in HDFS engine in the LIBNAME statement and by the HPDS2 procedure. |
| 2 | The FILETYPE=CSV data set option enables the engine to read the CSV file. The GETNAMES= data set option is used to read the variable names from the first line in the CSV file. |
| 3 | The PATH= data set
option is used to store the output as /user/sasdemo/rephdat.sashdat.
The COPIES=0 data set option is used to specify that no redundant
blocks are created for the rephdat.sashdat file.
|