General Statistics Examples
Example 10.15 Nonlinear Regression and Specifying a Model at Run Time
This example demonstrates two techniques: The first is an iterative statistical technique for fitting a nonlinear regression model (Hartley 1961). The second is a programming technique for generating modules at run time by using the QUEUE subroutine .
The typical nonlinear regression program defines modules for the regression model and its derivative as follows:
start nlfit; /* fit model, residuals, and SSE for current parameter values */ finish; start nlderiv; /* evaluate derivatives of model w.r.t parameters */ finish;
However, there might be situations in which the regression model is not known until run time. For example, the model might be specified in a file or from an equation that is typed into a dialog box.
In this situtation, you can use the QUEUE subroutine to write the NLFIT and NLDERIV modules at run time. You can insert equations for the model and its derivative into the module definitions by using the techniques that are described in the section Statements That Define and Execute Modules in Chapter 6: Programming Statements.
The following module specifies the model and its derivatives as character strings:
proc iml;
/* _FUN and _DER are text strings that define model and deriv */
/* _parm contains parm names */
/* _beta contains initial values for parameters */
/* _k is the number of parameters */
start nlinit;
_dep = "uspop"; /* dependent variable */
_fun = "a0*exp(a1*time)"; /* nonlinear regression model */
/* deriv w.r.t. parameters */
_der = {"exp(a1*time)", "time*a0*exp(a1*time)"};
_parm = {"a0", "a1"}; /* names of parameters */
_beta = {3.9, 0}; /* initial guess for parameters */
_k= nrow(_parm); /* number of parameters */
finish nlinit;
All variables are global in scope. Consequently, their names are prefixed by an underscore in order to reduce the likelihood of conflicting with other variables in your program.
The following statements use equations for the model to write the NLFIT and NLDERIV modules:
/* Generate the following modules at run time: */
/* NLFIT: evaluate the model. After RUN NLFIT: */
/* _y contains response, */
/* _p contains predictor after call */
/* _r contains residuals */
/* _sse contains sse */
/* NLDERIV: evaluate derivs w.r.t params. After RUN NLDERIV: */
/* _x contains jacobian */
start nlgen;
call change(_fun, '*', '#', 0); /* substitute '#' for '*' */
call change(_der, '*', '#', 0);
/* Write the NLFIT module at run time */
call queue('start nlfit;');
do i=1 to _k;
call queue(_parm[i], "=_beta[", char(i,2), "];");
end;
call queue("_y = ", _dep, ";",
"_p = ", _fun, ";",
"_r = _y - _p;",
"_sse = ssq(_r);",
"finish;" );
/* Write the NLDERIV function at run time */
call queue('start nlderiv; free _NULL_; _x = ');
do i=1 to _k;
call queue("(", _der[i], ")||");
end;
call queue("_NULL_; finish;");
call queue("resume;"); /* Pause to compile the functions */
pause *;
finish nlgen;
The program proceeds by calling the NLFIT and NLDERIV modules. The algorithm uses a Gauss-Newton nonlinear regression with step-halving to solve the nonlinear least squares estimation problem:
/* Gauss-Newton nonlinear regression with Hartley step-halving */
start nlest;
run nlfit; /* f, r, and sse for initial beta */
/* Gauss-Newton iterations to estimate parameters */
do _iter=1 to 30 until(_eps<1e-8);
run nlderiv; /* subroutine for derivatives */
_lastsse = _sse;
_xpxi=sweep(_x`*_x);
_delta = _xpxi*_x`*_r; /* correction vector */
_old = _beta; /* save previous parameters */
_beta = _beta + _delta; /* apply the correction */
run nlfit; /* compute residual */
_eps = abs((_lastsse-_sse)) / (_sse+1e-6);
/* Hartley subiterations */
do _subit=1 to 10 while(_sse>_lastsse);
_delta = _delta/2; /* halve the correction vector */
_beta = _old+_delta; /* apply the halved correction */
run nlfit; /* find sse et al */
end;
/* if no improvement after 10 halvings, exit iter loop */
if _subit>10 then _eps=0;
end;
/* display table of results */
if _iter < 30 then do; /* convergence */
_dfe = nrow(_y) - _k;
_mse = _sse/_dfe;
_std = sqrt(vecdiag(_xpxi)#_mse);
_t = _beta/_std;
_prob = 1 - cdf("F", _t#_t, 1, _dfe);
print _beta[label="Estimate"] _std[label="Std Error"]
_t[label="t Ratio"] _prob[format=pvalue6.];
print _iter[label="Iterations"] _lastsse[label="SSE"];
end;
else print "Convergence failed";
finish nlest;
Finally, the following statements define the data for the problem. The dependent variable is the US population from 1790–1970.
The explanatory variable is the number of years since 1790. The program fits an exponential model 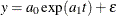 , where
, where  is an error term. The program estimates the parameters
is an error term. The program estimates the parameters 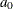 and
and 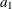 . The results are shown in Output 10.15.1.
. The results are shown in Output 10.15.1.
/* main program: run nonlinear regression on data */
uspop = {3929, 5308, 7239, 9638, 12866, 17069, 23191, 31443, 39818,
50155, 62947, 75994, 91972, 105710, 122775, 131669, 151325,
179323, 203211}/1000; /* US population, in thousands */
year = do(1790,1970,10)`;
time = year - 1790;
run nlinit; /* define strings that define the regression model */
run nlgen; /* write modules that evaluate the model */
run nlest; /* compute param estimates, std errs, and p-values */
Output 10.15.1: Nonlinear Regression Estimates
Output 10.15.1 shows that the US population data are best fit by the model 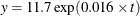 .
.