The following example presents comparisons of LMS, V7 LTS, and FAST-LTS. The data analyzed are the stackloss data of Brownlee (1965), which are also used for documenting the L1 regression module. The three explanatory variables correspond to measurements for a plant oxidizing ammonia to nitric acid on 21 consecutive days:
-
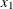 air flow to the plant
air flow to the plant
-
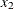 cooling water inlet temperature
cooling water inlet temperature
-
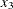 acid concentration
acid concentration
The response variable ![]() gives the permillage of ammonia lost (stackloss). The following data are also given in Rousseeuw and Leroy (1987) and Osborne (1985):
gives the permillage of ammonia lost (stackloss). The following data are also given in Rousseeuw and Leroy (1987) and Osborne (1985):
print "Stackloss Data";
aa = { 1 80 27 89 42,
1 80 27 88 37,
1 75 25 90 37,
1 62 24 87 28,
1 62 22 87 18,
1 62 23 87 18,
1 62 24 93 19,
1 62 24 93 20,
1 58 23 87 15,
1 58 18 80 14,
1 58 18 89 14,
1 58 17 88 13,
1 58 18 82 11,
1 58 19 93 12,
1 50 18 89 8,
1 50 18 86 7,
1 50 19 72 8,
1 50 19 79 8,
1 50 20 80 9,
1 56 20 82 15,
1 70 20 91 15 };
Rousseeuw and Leroy (1987) cite a large number of papers in which the preceding data set was analyzed. They state that most researchers “concluded that observations 1, 3, 4, and 21 were outliers” and that some people also reported observation 2 as an outlier.
For ![]() and
and ![]() (three explanatory variables including intercept), you obtain a total of 5,985 different subsets of 4 observations out of
21. If you do not specify OPTN[5], the LMS algorithms draw
(three explanatory variables including intercept), you obtain a total of 5,985 different subsets of 4 observations out of
21. If you do not specify OPTN[5], the LMS algorithms draw ![]() random sample subsets. Since there is a large number of subsets with singular linear systems that you do not want to print,
you can choose OPTN[2]=2 for reduced printed output, as in the following:
random sample subsets. Since there is a large number of subsets with singular linear systems that you do not want to print,
you can choose OPTN[2]=2 for reduced printed output, as in the following:
title2 "***Use 2000 Random Subsets for LMS***"; a = aa[,2:4]; b = aa[,5]; optn = j(9,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[8]= 3; /* icov */ call lms(sc,coef,wgt,optn,b,a);
Summary statistics are shown in Output 12.2.1. Output 12.2.2 displays the results of LS regression. Output 12.2.3 displays the LMS results for the 2000 random subsets.
Output 12.2.1: Some Simple Statistics
| ***Use 2000 Random Subsets for LMS*** |
| Median and Mean | ||
|---|---|---|
| Median | Mean | |
| VAR1 | 58 | 60.428571429 |
| VAR2 | 20 | 21.095238095 |
| VAR3 | 87 | 86.285714286 |
| Intercep | 1 | 1 |
| Response | 15 | 17.523809524 |
| Dispersion and Standard Deviation | ||
|---|---|---|
| Dispersion | StdDev | |
| VAR1 | 5.930408874 | 9.1682682584 |
| VAR2 | 2.965204437 | 3.160771455 |
| VAR3 | 4.4478066555 | 5.3585712381 |
| Intercep | 0 | 0 |
| Response | 5.930408874 | 10.171622524 |
Output 12.2.2: Table of Unweighted LS Regression
| LS Parameter Estimates | ||||||
|---|---|---|---|---|---|---|
| Variable | Estimate | Approx Std Err |
t Value | Pr > |t| | Lower WCI | Upper WCI |
| VAR1 | 0.7156402 | 0.13485819 | 5.31 | <.0001 | 0.45132301 | 0.97995739 |
| VAR2 | 1.29528612 | 0.36802427 | 3.52 | 0.0026 | 0.57397182 | 2.01660043 |
| VAR3 | -0.1521225 | 0.15629404 | -0.97 | 0.3440 | -0.4584532 | 0.15420818 |
| Intercep | -39.919674 | 11.8959969 | -3.36 | 0.0038 | -63.2354 | -16.603949 |
| Cov Matrix of Parameter Estimates | ||||
|---|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep | |
| VAR1 | 0.0181867302 | -0.036510675 | -0.007143521 | 0.2875871057 |
| VAR2 | -0.036510675 | 0.1354418598 | 0.0000104768 | -0.651794369 |
| VAR3 | -0.007143521 | 0.0000104768 | 0.024427828 | -1.676320797 |
| Intercep | 0.2875871057 | -0.651794369 | -1.676320797 | 141.51474107 |
Output 12.2.3: Iteration History and Optimization Results
| Subset | Singular | Best Criterion |
Percent |
|---|---|---|---|
| 500 | 23 | 0.163262 | 25 |
| 1000 | 55 | 0.140519 | 50 |
| 1500 | 79 | 0.140519 | 75 |
| 2000 | 103 | 0.126467 | 100 |
| Observations of Best Subset | |||
|---|---|---|---|
| 15 | 11 | 19 | 10 |
| Estimated Coefficients | |||
|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep |
| 0.75 | 0.5 | 0 | -39.25 |
For LMS, observations 1, 3, 4, and 21 have scaled residuals larger than 2.5 (output not shown), and they are considered outliers. Output 12.2.4 displays the corresponding WLS results.
Output 12.2.4: Table of Weighted LS Regression
| RLS Parameter Estimates Based on LMS | ||||||
|---|---|---|---|---|---|---|
| Variable | Estimate | Approx Std Err |
t Value | Pr > |t| | Lower WCI | Upper WCI |
| VAR1 | 0.79768556 | 0.06743906 | 11.83 | <.0001 | 0.66550742 | 0.9298637 |
| VAR2 | 0.57734046 | 0.16596894 | 3.48 | 0.0041 | 0.25204731 | 0.9026336 |
| VAR3 | -0.0670602 | 0.06160314 | -1.09 | 0.2961 | -0.1878001 | 0.05367975 |
| Intercep | -37.652459 | 4.73205086 | -7.96 | <.0001 | -46.927108 | -28.37781 |
| Cov Matrix of Parameter Estimates | ||||
|---|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep | |
| VAR1 | 0.0045480273 | -0.007921409 | -0.001198689 | 0.0015681747 |
| VAR2 | -0.007921409 | 0.0275456893 | -0.00046339 | -0.065017508 |
| VAR3 | -0.001198689 | -0.00046339 | 0.0037949466 | -0.246102248 |
| Intercep | 0.0015681747 | -0.065017508 | -0.246102248 | 22.392305355 |
The V7 LTS algorithm is similar to the LMS algorithm. Here is the code:
title2 "***Use 2000 Random Subsets for LTS***"; a = aa[,2:4]; b = aa[,5]; optn = j(9,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[8]= 3; /* icov */ optn[9]= 1; /* V7 LTS */ call lts(sc,coef,wgt,optn,b,a);
Output 12.2.5: Iteration History and Optimization Results
| ***Use 2000 Random Subsets for LTS*** |
| Subset | Singular | Best Criterion |
Percent |
|---|---|---|---|
| 500 | 23 | 0.099507 | 25 |
| 1000 | 55 | 0.087814 | 50 |
| 1500 | 79 | 0.084061 | 75 |
| 2000 | 103 | 0.084061 | 100 |
| Observations of Best Subset | |||
|---|---|---|---|
| 10 | 11 | 7 | 15 |
| Estimated Coefficients | |||
|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep |
| 0.75 | 0.3333333333 | 0 | -35.70512821 |
In addition to observations 1, 3, 4, and 21, which were considered outliers in LMS, observations 2 and 13 for LTS have absolute scaled residuals that are larger (but not as significantly as observations 1, 3, 4, and 21) than 2.5 (output not shown). Therefore, the WLS results based on LTS are different from those based on LMS.
Output 12.2.6 displays the results for the weighted LS regression.
Output 12.2.6: Table of Weighted LS Regression
| RLS Parameter Estimates Based on LTS | ||||||
|---|---|---|---|---|---|---|
| Variable | Estimate | Approx Std Err |
t Value | Pr > |t| | Lower WCI | Upper WCI |
| VAR1 | 0.75694055 | 0.07860766 | 9.63 | <.0001 | 0.60287236 | 0.91100874 |
| VAR2 | 0.45353029 | 0.13605033 | 3.33 | 0.0067 | 0.18687654 | 0.72018405 |
| VAR3 | -0.05211 | 0.05463722 | -0.95 | 0.3607 | -0.159197 | 0.054977 |
| Intercep | -34.05751 | 3.82881873 | -8.90 | <.0001 | -41.561857 | -26.553163 |
| Cov Matrix of Parameter Estimates | ||||
|---|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep | |
| VAR1 | 0.0061791648 | -0.005776855 | -0.002300587 | -0.034290068 |
| VAR2 | -0.005776855 | 0.0185096933 | 0.0002582502 | -0.069740883 |
| VAR3 | -0.002300587 | 0.0002582502 | 0.0029852254 | -0.131487406 |
| Intercep | -0.034290068 | -0.069740883 | -0.131487406 | 14.659852903 |
The FAST-LTS algorithm uses only 500 random subsets and gets better optimization results. Here is the code:
title2 "***Use 500 Random Subsets for FAST-LTS***"; a = aa[,2:4]; b = aa[,5]; optn = j(9,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[8]= 3; /* icov */ optn[9]= 0; /* FAST-LTS */ call lts(sc,coef,wgt,optn,b,a);
For this example, the two LTS algorithms identify the same outliers; however, the FAST-LTS algorithm uses only 500 random subsets and gets a smaller objective function, as seen in Output 12.2.7. For large data sets, the advantages of the FAST-LTS algorithm are more obvious.
Output 12.2.7: Optimization Results for FAST-LTS
| ***Use 500 Random Subsets for FAST-LTS*** |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 15 | 16 | 17 | 18 | 19 |
| Estimated Coefficients | |||
|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep |
| 0.7409210642 | 0.3915267228 | 0.0111345398 | -37.32332647 |
You now report the results of LMS for all different subsets. Here is the code:
title2 "*** Use All 5985 Subsets***"; a = aa[,2:4]; b = aa[,5]; optn = j(9,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[5]= -1; /* nrep: all 5985 subsets */ optn[8]= 3; /* icov */ ods select IterHist0 BestSubset EstCoeff; call lms(sc,coef,wgt,optn,b,a);
Output 12.2.8 displays the results for LMS.
Output 12.2.8: Iteration History and Optimization Results for LMS
| *** Use All 5985 Subsets*** |
| Subset | Singular | Best Criterion |
Percent |
|---|---|---|---|
| 1497 | 36 | 0.185899 | 25 |
| 2993 | 87 | 0.158268 | 50 |
| 4489 | 149 | 0.140519 | 75 |
| 5985 | 266 | 0.126467 | 100 |
| Observations of Best Subset | |||
|---|---|---|---|
| 8 | 10 | 15 | 19 |
| Estimated Coefficients | |||
|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep |
| 0.75 | 0.5 | 1.29526E-16 | -39.25 |
Next, report the results of LTS for all different subsets, as follows:
title2 "*** Use All 5985 Subsets***"; a = aa[,2:4]; b = aa[,5]; optn = j(9,1,.); optn[2]= 2; /* ipri */ optn[3]= 3; /* ilsq */ optn[5]= -1; /* nrep: all 5985 subsets */ optn[8]= 3; /* icov */ optn[9]= 1; /* V7 LTS */ ods select IterHist0 BestSubset EstCoeff; call lts(sc,coef,wgt,optn,b,a);
Output 12.2.9 displays the results for LTS.
Output 12.2.9: Iteration History and Optimization Results for LTS
| Subset | Singular | Best Criterion |
Percent |
|---|---|---|---|
| 1497 | 36 | 0.135449 | 25 |
| 2993 | 87 | 0.107084 | 50 |
| 4489 | 149 | 0.081536 | 75 |
| 5985 | 266 | 0.081536 | 100 |
| Observations of Best Subset | |||
|---|---|---|---|
| 5 | 12 | 17 | 18 |
| Estimated Coefficients | |||
|---|---|---|---|
| VAR1 | VAR2 | VAR3 | Intercep |
| 0.7291666667 | 0.4166666667 | -8.54713E-18 | -36.22115385 |