Distribution Analysis: Outlier Detection
Overview of the Outlier Detection Analysis
The Outlier Detection analysis computes outliers in contaminated normally distributed data. This analysis defines outliers as values that are sufficiently far from an estimate of the central tendency of the data.
More formally, suppose the data are normally distributed with location parameter 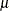 and scale parameter
and scale parameter  .
Let
.
Let 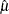 be an estimate of the location parameter. Let
be an estimate of the location parameter. Let 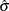 be an estimate of the scale parameter. Then a value x is considered an outlier if
be an estimate of the scale parameter. Then a value x is considered an outlier if
![\[ | x - \hat{\mu } | > c \hat{\sigma } \]](images/imlsug_ugdistoutliers0005.png)
where c is a constant that you can specify. The constant c is called the scale multiplier.
The basic idea is that if the data are normally distributed, then about 99% of the data are within three standard deviations of the mean. Therefore, if you can accurately estimate the mean (location parameter) and standard deviation (scale parameter), you can identify values in the tails of the distribution. However, if the data contain outliers, then you need to use robust estimators of the location and scale parameters. Robust estimates are described in the "Details" section of the documentation for the UNIVARIATE procedure in the Base SAS Procedures Guide.
You can use the analysis to specify traditional or robust estimates of location and scale parameters for a numerical variable. You can create a histogram with a normal curve overlaid. You can create an indicator variable that has the value 1 for observations that are sufficiently far from the location estimate.
You can run an Outlier Detection analysis by selecting → → from the main menu. When you request outlier detection, SAS/IML Studio calls the UNIVARIATE procedure in Base SAS software to compute location and scale estimates. SAS/IML statements are then used to compute the outliers.