Multivariate Analysis: Factor Analysis
Like principal component analysis, common factor analysis is a technique for reducing the complexity of high-dimensional data. (For brevity, this chapter refers to common factor analysis as simply "factor analysis.") However, the techniques differ in how they construct a subspace of reduced dimensionality. Jackson (1981, 1991) provides an excellent comparison of the two methods.
Principal component analysis chooses a coordinate system for the vector space spanned by the variables. (Recall that the span of a set of vectors is the vector space consisting of all linear combinations of the vectors.) The first principal component points in the direction of maximum variation in the data. Subsequent components account for as much of the remaining variation as possible while being orthogonal to all of the previous principal components. Each principal component is a linear combination of the original variables. Dimensional reduction is achieved by ignoring dimensions that do not explain much variation.
While principal component analysis explains variability, factor analysis explains correlation. Suppose two variables, ![]() and
and ![]() , are correlated, but not collinear. Factor analysis assumes the existence of an unobserved variable (often called a latent variable) that is linearly related to
, are correlated, but not collinear. Factor analysis assumes the existence of an unobserved variable (often called a latent variable) that is linearly related to ![]() and
and ![]() , and explains the correlation between them. The goal of factor analysis is to estimate this latent variable from the structure
of the original variables. An estimate of the unobserved variable is called a common factor.
, and explains the correlation between them. The goal of factor analysis is to estimate this latent variable from the structure
of the original variables. An estimate of the unobserved variable is called a common factor.
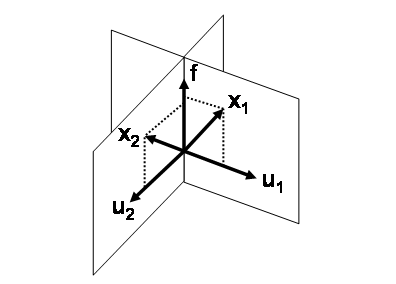
The geometry of the relationship between the original variables and the common factor is illustrated in Figure 27.1. (The figure is based on a similar figure in Wickens (1995), as is the following description of the geometry.) The correlated variables ![]() and
and ![]() are shown schematically in the figure. Each vector is decomposed into a linear combination of a common factor and a unique factor. That is,
are shown schematically in the figure. Each vector is decomposed into a linear combination of a common factor and a unique factor. That is, ![]() ,
, ![]() . The unique factors,
. The unique factors, ![]() and
and ![]() , are uncorrelated with the common factor,
, are uncorrelated with the common factor, ![]() , and with each other. Note that
, and with each other. Note that ![]() ,
, ![]() , and
, and ![]() are mutually orthogonal in the figure.
are mutually orthogonal in the figure.
In contrast to principal components, a factor is not, in general, a linear combination of the original variables. Furthermore, a principal component analysis depends only on the data, whereas a factor analysis requires fitting the theoretical structure in the previous paragraph to the observed data.
If there are p variables and you postulate the existence of m common factors, then each variable is represented as a linear combination of the m common factors and a single unique factor. Since the unique factors are uncorrelated with the common factors and with each
other, factor analysis requires ![]() dimensions. (Figure 27.1 illustrates the case
dimensions. (Figure 27.1 illustrates the case ![]() and
and ![]() .) However, the orthogonality of the unique factors means that the geometry is readily understood by projecting the original
variables onto the span of the m factors (called the factor space). A graph of this projection is called a pattern plot. In Figure 27.1, the pattern plot is the two points on
.) However, the orthogonality of the unique factors means that the geometry is readily understood by projecting the original
variables onto the span of the m factors (called the factor space). A graph of this projection is called a pattern plot. In Figure 27.1, the pattern plot is the two points on ![]() obtained by projecting
obtained by projecting ![]() and
and ![]() onto
onto ![]() .
.
The length of the projection of an original variable ![]() onto the factor space indicates the proportion of the variability of
onto the factor space indicates the proportion of the variability of ![]() that is shared with the other variables. This proportion is called the communality. Consequently, the variance of each original variable is the sum of the common variance (represented by the communality) and
the variance of the unique factor for that variable. In a pattern plot, the communality is the squared distance from the origin
to a point.
that is shared with the other variables. This proportion is called the communality. Consequently, the variance of each original variable is the sum of the common variance (represented by the communality) and
the variance of the unique factor for that variable. In a pattern plot, the communality is the squared distance from the origin
to a point.
In factor analysis, the common factors are not unique. Typically an initial orthonormal set of common factors is computed, but then these factors are rotated so that the factors are more easily interpreted in terms of the original variables. An orthogonal rotation preserves the orthonormality of the factors; an oblique transformation introduces correlations among one or more factors.
You can run the Factor analysis in SAS/IML Studio by selecting → → from the main menu. The analysis is implemented by calling the FACTOR procedure in SAS/STAT software. See the FACTOR procedure documentation in the SAS/STAT User's Guide for additional details.
The FACTOR procedure provides several methods of estimating the common factors and the communalities. Since an ![]() -dimensional model is fit by using the original p variables, you should interpret the results with caution. The following list describes special issues that can occur:
-dimensional model is fit by using the original p variables, you should interpret the results with caution. The following list describes special issues that can occur:
-
Some of the eigenvalues of the reduced correlation matrix might be negative. A reduced correlation matrix is the correlation matrix of the original variables, except that the 1’s on the diagonal are replaced by prior communality estimates. These estimates are less than 1, and so the reduced correlation matrix might not be positive definite. In this case, the factors that correspond to the largest eigenvalues might account for more than 100% of the common variance.
-
The communalities are the proportions of the variance of the original variables that can be attributed to the common factors. As such, the communalities should be in the interval
![$[0,1]$](images/imlsug_ugmultfactor0013.png) . However, factor analyses that use iterative fitting estimate the communality at each iteration. For some data, the estimate
might equal (or exceed) 1 before the analysis has converged to a solution. This is known as a Heywood (or an ultra-Heywood)
case, and it implies that one or more unique factor has a nonpositive variance. When this occurs, the factor analysis stops iterating and reports an error.
. However, factor analyses that use iterative fitting estimate the communality at each iteration. For some data, the estimate
might equal (or exceed) 1 before the analysis has converged to a solution. This is known as a Heywood (or an ultra-Heywood)
case, and it implies that one or more unique factor has a nonpositive variance. When this occurs, the factor analysis stops iterating and reports an error.
These and other issues are described in the section "Heywood Cases and Other Anomalies about Communality Estimates" in the documentation for the FACTOR procedure.
You can use many different methods to perform a factor analysis. Two popular methods are the principal factor method and the maximum likelihood method. The principal factor method is computationally efficient and has similarities to principal component analysis. The maximum likelihood (ML) method is an iterative method that is computationally more demanding and is prone to Heywood cases, nonconvergence, and multiple optimal solutions. However, the ML method also provides statistics such as standard errors and confidence limits that help you to assess how well the model fits the data, and to interpret factors. Consequently, the ML method is often favored by statisticians.
In addition to these various methods of factor analysis, you can use SAS/IML Studio to compute various component analyses: principal component analysis, Harris component analysis, and image component analysis.