| The HTSNP Procedure |
Overview: HTSNP Procedure
Single nucleotide polymorphism (SNP) is the most abundant form of genetic variation and accounts for about 90% of human DNA polymorphism. There is roughly one SNP per 1 kilobase in the human genome. Studies of human haplotype variations that use SNPs over large genomic regions suggest the presence of discrete blocks with limited haplotype diversity punctuated by recombination hot spots. The intrablock linkage disequilibrium (LD) decreases only gradually with distance, while the interblock LD decays much more rapidly. Within each block, because of high LD, some allele(s) might always be coexistent with a particular allele at another locus such that (1) little haplotype diversity exists in the block, and (2) not all SNPs will be essential in characterizing the haplotype structure in the block. Therefore, the most common haplotypes could usually be captured by a small subset of SNPs, termed haplotype tagging SNPs (htSNPs) by Johnson et al. (2001).
The selection of such a SNP subset that distinguishes all haplotypes, however, is known as the minimum test set problem and is NP-complete. The search space of choosing 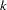 SNPs out of
SNPs out of 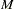 is
is 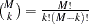 , for which enumerating all possible -SNP combinations becomes impractical even for moderate numbers of and . The HTSNP procedure implements some heuristic algorithms for fast identification of an optimal subset of SNPs without mining through all possible combinations. An exhaustive search algorithm throughout the
, for which enumerating all possible -SNP combinations becomes impractical even for moderate numbers of and . The HTSNP procedure implements some heuristic algorithms for fast identification of an optimal subset of SNPs without mining through all possible combinations. An exhaustive search algorithm throughout the 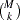 search space is also provided in PROC HTSNP.
search space is also provided in PROC HTSNP.
Note: This procedure is experimental.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.