The MDC Procedure
Multinomial Probit
The multinomial probit model allows the random components of the utility of the different alternatives to be nonindependent and nonidentical. Thus, it does not have the IIA property. The increase in the flexibility of the error structure comes at the expense of introducing several additional parameters in the covariance matrix of the errors.
Consider the random utility function
![\[ U_{ij} = \mathbf{x}_{ij}’\bbeta + \epsilon _{ij} \]](images/etsug_mdc0126.png)
where the joint distribution of 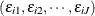 is multivariate normal:
is multivariate normal:
![\[ \left[ \begin{array}{c} \epsilon _{i1} \\ \epsilon _{i2} \\ \vdots \\ \epsilon _{iJ} \\ \end{array} \right] \sim N(\mathbf{0},\bSigma ) \]](images/etsug_mdc0128.png)
![\[ \bSigma = \left[ \sigma _{jk} \right]_{j,k=1,\ldots ,J} \]](images/etsug_mdc0129.png)
The dimension of the error covariance matrix is determined by the number of alternatives J. Given 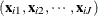 , the jth alternative is chosen if and only if
, the jth alternative is chosen if and only if 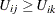 for all
for all 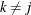 . Thus, the probability that the jth alternative is chosen is
. Thus, the probability that the jth alternative is chosen is
![\[ P(y_{i} = j) = P_{ij} = P[\epsilon _{i1}-\epsilon _{ij}< (\mathbf{x}_{ij}-\mathbf{x}_{i1})’\bbeta ,\ldots , \epsilon _{iJ}-\epsilon _{ij} <(\mathbf{x}_{ij}-\mathbf{x}_{iJ})’\bbeta ] \]](images/etsug_mdc0133.png)
where 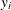 is a random variable that indicates the choice made. This is a cumulative probability from a
is a random variable that indicates the choice made. This is a cumulative probability from a 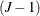 -variate normal distribution. Since evaluation of this probability involves multidimensional integration, it is practical
to use a simulation method to estimate the model. Many studies have shown that the simulators proposed by the following authors
(henceforth referred to as GHK) perform well: Geweke (1989); Hajivassiliou (1993); Keane (1994). For example, Hajivassiliou, McFadden, and Ruud (1996) compare 13 simulators using 11 different simulation methods and conclude that the GHK simulation method is the most reliable.
To compute the probability of the multivariate normal distribution, the recursive simulation method is used. Refer to Hajivassiliou
(1993) for more details about GHK simulators.
-variate normal distribution. Since evaluation of this probability involves multidimensional integration, it is practical
to use a simulation method to estimate the model. Many studies have shown that the simulators proposed by the following authors
(henceforth referred to as GHK) perform well: Geweke (1989); Hajivassiliou (1993); Keane (1994). For example, Hajivassiliou, McFadden, and Ruud (1996) compare 13 simulators using 11 different simulation methods and conclude that the GHK simulation method is the most reliable.
To compute the probability of the multivariate normal distribution, the recursive simulation method is used. Refer to Hajivassiliou
(1993) for more details about GHK simulators.
The log-likelihood function for the multinomial probit model can be written as
![\[ \mathcal{L} = \sum _{i=1}^{N}\sum _{j=1}^{J}d_{ij}\ln P(y_{i} = j) \]](images/etsug_mdc0135.png)
where
![\[ d_{ij} = \left\{ \begin{array}{cl} 1 & \mr{if \; individual} \; i \; \mr{chooses \; alternative} \; j \\ 0 & \mr{otherwise} \end{array} \right. \]](images/etsug_mdc0076.png)
For identification of the multinomial probit model, two of the diagonal elements of 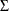 are normalized to 1, and it is assumed that for one of the choices whose error variance is normalized to 1 (say, k), it is also true that
are normalized to 1, and it is assumed that for one of the choices whose error variance is normalized to 1 (say, k), it is also true that 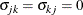 for
for 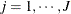 and
and 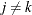 . Thus, a model with J alternatives has at most
. Thus, a model with J alternatives has at most 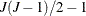 covariance parameters after normalization.
covariance parameters after normalization.
Let D and R be defined as
![\[ D = \left[ \begin{array}{cccc} \sigma _{1} & 0 & \cdots & 0 \\ 0 & \sigma _{2} & \cdots & 0 \\ \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & \cdots & \sigma _{J} \\ \end{array} \right] \]](images/etsug_mdc0141.png)
![\[ R = \left[ \begin{array}{cccc} 1 & \rho _{12} & \cdots & \rho _{1J} \\ \rho _{21} & 1 & \cdots & \rho _{2J} \\ \vdots & \vdots & \vdots & \vdots \\ \rho _{J1} & \rho _{J2} & \cdots & 1 \\ \end{array} \right] \]](images/etsug_mdc0142.png)
where 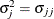 and
and 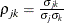 . Then, for identification,
. Then, for identification, 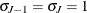 and
and 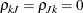 , for all
, for all 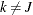 can be imposed, and the error covariance matrix is
can be imposed, and the error covariance matrix is 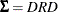 .
.
In the standard MDC output, the parameter estimates STD_j and RHO_jk correspond to 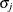 and
and 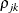 .
.
In principle, the multinomial probit model is fully identified with the preceding normalizations. However, in practice, convergence
in applications of the model with more than three alternatives often requires additional restrictions on the elements of 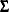 .
.
It must also be noted that the unrestricted structure of the error covariance matrix makes it impossible to forecast demand
for a new alternative without knowledge of the new 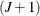 by error covariance matrix.
by error covariance matrix.