| Restrictions and Bounds on Parameters |
Using the BOUNDS and RESTRICT statements, PROC MODEL can compute optimal estimates subject to equality or inequality constraints on the parameter estimates.
Equality restrictions can be written as a vector function:
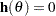 |
Inequality restrictions are either active or inactive. When an inequality restriction is active, it is treated as an equality restriction. All inactive inequality restrictions can be written as a vector function:
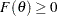 |
Strict inequalities, such as 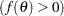 , are transformed into inequalities as
, are transformed into inequalities as 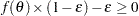 , where the tolerance
, where the tolerance  is controlled by the EPSILON= option in the FIT statement and defaults to
is controlled by the EPSILON= option in the FIT statement and defaults to  . The ith inequality restriction becomes active if
. The ith inequality restriction becomes active if 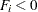 and remains active until its Lagrange multiplier becomes negative. Lagrange multipliers are computed for all the nonredundant equality restrictions and all the active inequality restrictions.
and remains active until its Lagrange multiplier becomes negative. Lagrange multipliers are computed for all the nonredundant equality restrictions and all the active inequality restrictions.
For the following, assume the vector  contains all the current active restrictions. The constraint matrix
contains all the current active restrictions. The constraint matrix 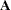 is
is
 |
The covariance matrix for the restricted parameter estimates is computed as
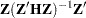 |
where  is Hessian or approximation to the Hessian of the objective function (
is Hessian or approximation to the Hessian of the objective function (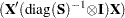 for OLS), and
for OLS), and 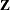 is the last
is the last 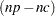 columns of
columns of 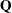 . is from an LQ factorization of the constraint matrix, nc is the number of active constraints, and np is the number of parameters. See Gill, Murray, and Wright (1981) for more details on LQ factorization. The covariance column in Table 19.1 summarizes the Hessian approximation used for each estimation method.
. is from an LQ factorization of the constraint matrix, nc is the number of active constraints, and np is the number of parameters. See Gill, Murray, and Wright (1981) for more details on LQ factorization. The covariance column in Table 19.1 summarizes the Hessian approximation used for each estimation method.
The covariance matrix for the Lagrange multipliers is computed as
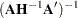 |
The p-value reported for a restriction is computed from a beta distribution rather than a t distribution because the numerator and the denominator of the t ratio for an estimated Lagrange multiplier are not independent.
The Lagrange multipliers for the active restrictions are printed with the parameter estimates. The Lagrange multiplier estimates are computed using the relationship
 |
where the dimensions of the constraint matrix are the number of constraints by the number of parameters, 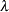 is the vector of Lagrange multipliers, and g is the gradient of the objective function at the final estimates.
is the vector of Lagrange multipliers, and g is the gradient of the objective function at the final estimates.
The final gradient includes the effects of the estimated 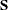 matrix. For example, for OLS the final gradient would be:
matrix. For example, for OLS the final gradient would be:
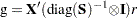 |
where r is the residual vector. Note that when nonlinear restrictions are imposed, the convergence measure R might have values greater than one for some iterations.