| The SASEHAVR Interface Engine |
| LIBNAME libref SASEHAVR Statement |
- LIBNAME libref sasehavr 'physical name' options ;
The 'physical name' specifies the location of the folder where your Haver DLX database resides.
You can use the following options in the LIBNAME libref SASEHAVR statement:
- FREQ=haver_frequency
- FREQUENCY=haver_frequency
- INTERVAL=haver_frequency
specifies the Haver frequency. All Haver frequencies are supported by the SASEHAVR engine. Accepted frequency values are annual, year, yearly, quarter, quarterly, qtr, monthly, month, mon, week.1, week.2, week.3, week.4, week.5, week.6, week.7, weekly, week, daily, and day.
- START=start_date
- STARTDATE=start_date
- STDATE=start_date
- BEGIN=start_date
specifies the start date for the time series in the form YYYYMMDD.
- END=end_date
- ENDDATE=end_date
- ENDATE=end_date
specifies the end date for the time series in the form YYYYMMDD.
- KEEP="haver_variable_list"
specifies the list of Haver variables to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROP="haver_variable_list"
specifies the list of Haver variables to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- GROUP="haver_group_list"
- KEEPGROUP="haver_group_list"
specifies the list of Haver groups to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPGROUP="haver_group_list"
specifies the list of Haver groups to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- SOURCE="haver_source_list"
- KEEPSOURCE="haver_source_list"
specifies the list of Haver sources to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPSOURCE="haver_source_list"
specifies the list of Haver sources to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- SHORT="haver_shortsource_list"
- KEEPSHORT="haver_shortsource_list"
- SHORTSOURCE="haver_shortsource_list"
specifies the list of Haver short sources to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPSHORT="haver_shortsource_list"
- DROPSHORTSOURCE="haver_shortsource_list"
specifies the list of Haver short sources to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- LONG="haver_longsource_list"
- KEEPLONG="haver_longsource_list"
- LONGSOURCE="haver_longsource_list"
specifies the list of Haver long sources to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPLONG="haver_longsource_list"
- DROPLONGSOURCE="haver_longsource_list"
specifies the list of Haver long sources to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- GEOG1="haver_geographycode1_list"
- KEEPGEOG1="haver_geographycode1_list"
- GEOGCODE1="haver_geographycode1_list"
specifies the list of Haver geography1 codes to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPGEOG1="haver_geographycode1_list"
- DROPGEOGCODE1="haver_geographycode1_list"
specifies the list of Haver geography1 codes to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- GEOG2="haver_geographycode2_list"
- KEEPGEOG2="haver_geographycode2_list"
- GEOGCODE2="haver_geographycode2_list"
specifies the list of Haver geography2 codes to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- DROPGEOG2="haver_geographycode2_list"
- DROPGEOGCODE2="haver_geographycode2_list"
specifies the list of Haver geography2 codes to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotes "".
- OUTSELECT=ON
specifies that the output data set show values of selection keys (such as geography codes, groups, sources, short sources, and long sources) for each selected variable name (time series) in the database.
- OUTSELECT=OFF
specifies that the output data set show the observations in the range for all selected time series. This is the default for this option.
- AGGMODE=STRICT
specifies that the SASEHAVR engine use a strict aggregation method when converting time series from a higher to lower frequency. A strict aggregation method returns a missing value whenever there is a missing observation in a time period. For instance, if a monthly time series has a missing value for the month of February, 2005, then attempting to aggregate to a quarterly frequency results in a missing value for the first quarter of 2005. The SAS log reports the status of this option.
- AGGMODE=RELAXED
specifies that the SASEHAVR engine use a relaxed aggregation method when converting time series from a higher to lower frequency. When a relaxed aggregation method is used, some observations can be missing, but the relaxed method returns an aggregated value calculated from the non-missing data points according to the series aggregation type (average, sum, or end of period). Average type only needs one valid (non-missing) data point to calculate the average. Sum type needs all the data points to be available in order to sum the values. End of period type calculates the end of period value if there is at least one valid (non-missing) data point in the aggregated span. It returns the last available valid data point in the aggregated span. This is the default for this option.
- FORCE=FREQ
specifies that the selected variables be aggregated to the frequency in the FREQ= option. Aggregation is supported only from a more frequent time interval to a less frequent time interval, such as from weekly to monthly. See the section Aggregating to Quarterly Frequency Using the FORCE=FREQ Option for sample output and suggested error recovery from attempting a conversion that yields missing values when a higher frequency conversion is specified. This option is ignored if the FREQ= option is not set. For a more complete discussion of Haver frequencies and SAS time intervals, see the section Mapping Haver Frequencies to SAS Time Intervals.
Following is an example of the LIBNAME libref SASEHAVR statement:
LIBNAME libref sasehavr 'physical-name'
FREQ=MONTHLY;
By default, the SASEHAVR engine reads all time series in the Haver database that you reference by libref. The start_date is specified in the form YYYYMMDD. The start date is used to delimit the data to a specified start date.
For example, to read the time series in the TEST library starting on July 4, 1996, specify the following statement:
LIBNAME test sasehavr 'physical-name'
STARTDATE=19960704;
When you use the START= option, you limit the range of observations that are read from the time series and that are converted to the desired frequency. Start dates can help save resources when processing large databases or when processing a large number of observations. It is also possible to select specific variables to be included or excluded from the SAS data set by using the KEEP= or the DROP= option, respectively.
LIBNAME test sasehavr 'physical-name'
KEEP="ABC*, XYZ??";
LIBNAME test sasehavr 'physical-name'
DROP="*SC*, #T#";
When the KEEP= or the DROP= option is used, the resulting SAS data set keeps or drops the variables that you select in that option. Three wildcards are available: '*', '?' and '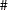 '. The '*' wildcard corresponds to any character string and includes any string pattern that corresponds to that position in the matching variable name. The '?' means that any single alphanumeric character is valid. The '' wildcard corresponds to a single numeric character. You can also select time series in your data by using the GROUP=, SOURCE=, SHORT=, LONG=, GEOG1=, or the GEOG2= option to select on group name, source name, short source name, long source name, geography1 code, or the geography2 code, respectively. Alternatively, you can deselect time series by using the DROPGROUP=, DROPSOURCE=, DROPSHORT=, DROPLONG=, DROPGEOG1=, or the DROPGEOG2= option, respectively.
'. The '*' wildcard corresponds to any character string and includes any string pattern that corresponds to that position in the matching variable name. The '?' means that any single alphanumeric character is valid. The '' wildcard corresponds to a single numeric character. You can also select time series in your data by using the GROUP=, SOURCE=, SHORT=, LONG=, GEOG1=, or the GEOG2= option to select on group name, source name, short source name, long source name, geography1 code, or the geography2 code, respectively. Alternatively, you can deselect time series by using the DROPGROUP=, DROPSOURCE=, DROPSHORT=, DROPLONG=, DROPGEOG1=, or the DROPGEOG2= option, respectively.
Following are examples that perform variable selection (or deselection) based on groups or sources:
LIBNAME test sasehavr 'physical-name'
GROUP="CBA, *ZYX";
LIBNAME test sasehavr 'physical-name'
DROPGROUP="TKN*, XCZ?";
LIBNAME test sasehavr 'physical-name'
SOURCE="FRB";
LIBNAME test sasehavr 'physical-name'
DROPSOURCE="NYSE";
SASEHAVR selects only the variables that are of the specified frequency in the FREQ= option. If this option is not specified, SASEHAVR selects the variables that match the frequency of the first selected variable. If no other selection criteria are specified, by default the first selected variable is the first physical DLX record read from the Haver database. You can specify the FORCE=FREQ option to force the aggregation of all variables selected to be of the frequency specified in the FREQ= option. Aggregation is supported only from a more frequent time interval to a less frequent time interval, such as from weekly to monthly. See the section Aggregating to Quarterly Frequency Using the FORCE=FREQ Option for suggested recovery from using a frequency that does not aggregate the data appropriately. The FORCE= option is ignored if the FREQ= option is not specified. The AGGMODE= STRICT option is used when a strict aggregation method is desired. The default value for AGGMODE is RELAXED, the same method that was used in prior releases of SASEHAVR.
Copyright © SAS Institute, Inc. All Rights Reserved.