| The QLIM Procedure |
| ENDOGENOUS Statement |
- ENDOGENOUS variables
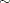 options ;
options ;
The ENDOGENOUS statement specifies the type of dependent variables that appear on the left-hand side of the equation. Endogenous variables listed refer to the dependent variables that appear on the left-hand side of the equation. Currently, no right-hand side endogeneity is handled in PROC QLIM. All variables appearing on the right-hand side of the equation are treated as exogenous.
Discrete Variable Options
- DISCRETE <(discrete-options )>
specifies that the endogenous variables in this statement are discrete. Valid discrete-options are as follows:
- ORDER=DATA | FORMATTED | FREQ | INTERNAL
specifies the sorting order for the levels of the discrete variables specified in the ENDOGENOUS statement. This ordering determines which parameters in the model correspond to each level in the data. The following table shows how PROC QLIM interprets values of the ORDER= option.
Value of ORDER=
Levels Sorted By
DATA
order of appearance in the input data set
FORMATTED
formatted value
FREQ
descending frequency count; levels with the
most observations come first in the order
INTERNAL
unformatted value
By default, ORDER=FORMATTED. For the values FORMATTED and INTERNAL, the sort order is machine dependent. For more information about sorting order, see the chapter on the SORT procedure in the Base SAS Procedures Guide.
- DISTRIBUTION=distribution-type
- DIST=distribution-type
- D=distribution-type
specifies the cumulative distribution function used to model the response probabilities. Valid values for distribution-type are as follows:
- NORMAL
the normal distribution for the probit model
- LOGISTIC
the logistic distribution for the logit model
By default, DISTRIBUTION=NORMAL.
If a multivariate model is specified, logistic distribution is not allowed. Only normal distribution is supported.
Censored Variable Options
- CENSORED <(censored-options )>
specifies that the endogenous variables in this statement be censored. Valid censored-options are as follows:
- LB=value or variable
- LOWERBOUND=value or variable
specifies the lower bound of the censored variables. If value is missing or the value in variable is missing, no lower bound is set. By default, no lower bound is set.
- UB=value or variable
- UPPERBOUND=value or variable
specifies the upper bound of the censored variables. If value is missing or the value in variable is missing, no upper bound is set. By default, no upper bound is set.
Truncated Variable Options
- TRUNCATED <(truncated-options )>
specifies that the endogenous variables in this statement be truncated. Valid truncated-options are as follows:
- LB=value or variable
- LOWERBOUND=value or variable
specifies the lower bound of the truncated variables. If value is missing or the value in variable is missing, no lower bound is set. By default, no lower bound is set.
- UB=value or variable
- UPPERBOUND=value or variable
specifies the upper bound of the truncated variables. If value is missing or the value in variable is missing, no upper bound is set. By default, no upper bound is set.
Stochastic Frontier Variable Options
- FRONTIER <(frontier-options )>
specifies that the endogenous variable in this statement follow a production or cost frontier. Valid frontier-options are as follows:
- TYPE=
- HALF
specifies half-normal model.
- EXPONENTIAL
specifies exponential model.
- TRUNCATED
specifies truncated normal model.
- PRODUCTION
specifies that the model estimated be a production function.
- COST
specifies that the model estimated be a cost function.
If neither PRODUCTION nor COST option is specified, production function is estimated by default.
Selection Options
- SELECT (select-option )
specifies selection criteria for sample selection model. Select-option specifies the condition for the endogenous variable to be selected. It is written as a variable name, followed by an equality operator (=) or an inequality operator (<, >, <=, >=), followed by a number:
variable operator number
The variable is the endogenous variable that the selection is based on. The operator can be =, <, >, <= , or >=. Multiple select-options can be combined with the logic operators: AND, OR. The following example illustrates the use of the SELECT option:
endogenous y1 ~ select(z=0); endogenous y2 ~ select(z=1 or z=2);
The SELECT option can be used together with the DISCRETE, CENSORED, or TRUNCATED option. For example:
endogenous y1 ~ select(z=0) discrete; endogenous y2 ~ select(z=1) censored (lb=0); endogenous y3 ~ select(z=1 or z=2) truncated (ub=10);
For more details about selection models with censoring or truncation, see the section Selection Models.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.