| The AUTOREG Procedure |
| Autoregressive Error Model |
The regression model with autocorrelated disturbances is as follows:
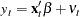 |
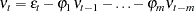 |
 |
In these equations, 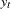 are the dependent values,
are the dependent values, 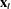 is a column vector of regressor variables,
is a column vector of regressor variables, 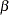 is a column vector of structural parameters, and
is a column vector of structural parameters, and 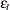 is normally and independently distributed with a mean of 0 and a variance of
is normally and independently distributed with a mean of 0 and a variance of 
 . Note that in this parameterization, the signs of the autoregressive parameters are reversed from the parameterization documented in most of the literature.
. Note that in this parameterization, the signs of the autoregressive parameters are reversed from the parameterization documented in most of the literature.
PROC AUTOREG offers four estimation methods for the autoregressive error model. The default method, Yule-Walker (YW) estimation, is the fastest computationally. The Yule-Walker method used by PROC AUTOREG is described in Gallant and Goebel (1976). Harvey (1981) calls this method the two-step full transform method. The other methods are iterated YW, unconditional least squares (ULS), and maximum likelihood (ML). The ULS method is also referred to as nonlinear least squares (NLS) or exact least squares (ELS).
You can use all of the methods with data containing missing values, but you should use ML estimation if the missing values are plentiful. See the section Alternative Autocorrelation Correction Methods later in this chapter for further discussion of the advantages of different methods.
The Yule-Walker Method
Let 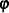 represent the vector of autoregressive parameters,
represent the vector of autoregressive parameters,
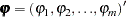 |
and let the variance matrix of the error vector 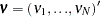 be
be 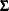 ,
,
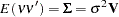 |
If the vector of autoregressive parameters is known, the matrix 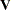 can be computed from the autoregressive parameters. is then
can be computed from the autoregressive parameters. is then 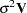 . Given , the efficient estimates of regression parameters
. Given , the efficient estimates of regression parameters 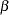 can be computed using generalized least squares (GLS). The GLS estimates then yield the unbiased estimate of the variance
can be computed using generalized least squares (GLS). The GLS estimates then yield the unbiased estimate of the variance 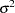 ,
,
The Yule-Walker method alternates estimation of using generalized least squares with estimation of using the Yule-Walker equations applied to the sample autocorrelation function. The YW method starts by forming the OLS estimate of . Next, is estimated from the sample autocorrelation function of the OLS residuals by using the Yule-Walker equations. Then is estimated from the estimate of , and is estimated from and the OLS estimate of . The autocorrelation corrected estimates of the regression parameters are then computed by GLS, using the estimated matrix. These are the Yule-Walker estimates.
If the ITER option is specified, the Yule-Walker residuals are used to form a new sample autocorrelation function, the new autocorrelation function is used to form a new estimate of and , and the GLS estimates are recomputed using the new variance matrix. This alternation of estimates continues until either the maximum change in the 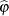 estimate between iterations is less than the value specified by the CONVERGE= option or the maximum number of allowed iterations is reached. This produces the iterated Yule-Walker estimates. Iteration of the estimates may not yield much improvement.
estimate between iterations is less than the value specified by the CONVERGE= option or the maximum number of allowed iterations is reached. This produces the iterated Yule-Walker estimates. Iteration of the estimates may not yield much improvement.
The Yule-Walker equations, solved to obtain and a preliminary estimate of 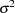 , are
, are
 |
Here  , where
, where  is the lag i sample autocorrelation. The matrix
is the lag i sample autocorrelation. The matrix 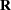 is the Toeplitz matrix whose i,jth element is
is the Toeplitz matrix whose i,jth element is 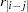 . If you specify a subset model, then only the rows and columns of and
. If you specify a subset model, then only the rows and columns of and  corresponding to the subset of lags specified are used.
corresponding to the subset of lags specified are used.
If the BACKSTEP option is specified, for purposes of significance testing, the matrix 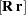 is treated as a sum-of-squares-and-crossproducts matrix arising from a simple regression with
is treated as a sum-of-squares-and-crossproducts matrix arising from a simple regression with 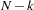 observations, where k is the number of estimated parameters.
observations, where k is the number of estimated parameters.
The Unconditional Least Squares and Maximum Likelihood Methods
Define the transformed error,  , as
, as
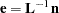 |
where 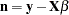 .
.
The unconditional sum of squares for the model,  , is
, is
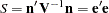 |
The ULS estimates are computed by minimizing  with respect to the parameters and
with respect to the parameters and 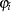 .
.
The full log likelihood function for the autoregressive error model is
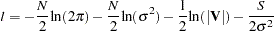 |
where 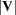 denotes determinant of
denotes determinant of 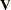 . For the ML method, the likelihood function is maximized by minimizing an equivalent sum-of-squares function.
. For the ML method, the likelihood function is maximized by minimizing an equivalent sum-of-squares function.
Maximizing l with respect to 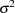 (and concentrating out of the likelihood) and dropping the constant term
(and concentrating out of the likelihood) and dropping the constant term 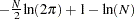 produces the concentrated log likelihood function
produces the concentrated log likelihood function
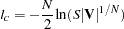 |
Rewriting the variable term within the logarithm gives
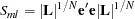 |
PROC AUTOREG computes the ML estimates by minimizing the objective function 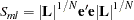 .
.
The maximum likelihood estimates may not exist for some data sets (Anderson and Mentz; 1980). This is the case for very regular data sets, such as an exact linear trend.
Computational Methods
Sample Autocorrelation Function
The sample autocorrelation function is computed from the structural residuals or noise 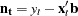 , where
, where  is the current estimate of . The sample autocorrelation function is the sum of all available lagged products of
is the current estimate of . The sample autocorrelation function is the sum of all available lagged products of 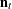 of order j divided by
of order j divided by 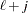 , where
, where 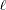 is the number of such products.
is the number of such products.
If there are no missing values, then 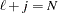 , the number of observations. In this case, the Toeplitz matrix of autocorrelations, , is at least positive semidefinite. If there are missing values, these autocorrelation estimates of r can yield an matrix that is not positive semidefinite. If such estimates occur, a warning message is printed, and the estimates are tapered by exponentially declining weights until is positive definite.
, the number of observations. In this case, the Toeplitz matrix of autocorrelations, , is at least positive semidefinite. If there are missing values, these autocorrelation estimates of r can yield an matrix that is not positive semidefinite. If such estimates occur, a warning message is printed, and the estimates are tapered by exponentially declining weights until is positive definite.
Data Transformation and the Kalman Filter
The calculation of from for the general AR model is complicated, and the size of depends on the number of observations. Instead of actually calculating and performing GLS in the usual way, in practice a Kalman filter algorithm is used to transform the data and compute the GLS results through a recursive process.
model is complicated, and the size of depends on the number of observations. Instead of actually calculating and performing GLS in the usual way, in practice a Kalman filter algorithm is used to transform the data and compute the GLS results through a recursive process.
In all of the estimation methods, the original data are transformed by the inverse of the Cholesky root of . Let  denote the Cholesky root of — that is,
denote the Cholesky root of — that is, 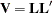 with lower triangular. For an AR model,
with lower triangular. For an AR model, 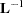 is a band diagonal matrix with m anomalous rows at the beginning and the autoregressive parameters along the remaining rows. Thus, if there are no missing values, after the first
is a band diagonal matrix with m anomalous rows at the beginning and the autoregressive parameters along the remaining rows. Thus, if there are no missing values, after the first 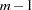 observations the data are transformed as
observations the data are transformed as
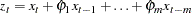 |
The transformation is carried out using a Kalman filter, and the lower triangular matrix is never directly computed. The Kalman filter algorithm, as it applies here, is described in Harvey and Phillips (1979) and Jones (1980). Although is not computed explicitly, for ease of presentation the remaining discussion is in terms of . If there are missing values, then the submatrix of consisting of the rows and columns with nonmissing values is used to generate the transformations.
Gauss-Newton Algorithms
The ULS and ML estimates employ a Gauss-Newton algorithm to minimize the sum of squares and maximize the log likelihood, respectively. The relevant optimization is performed simultaneously for both the regression and AR parameters. The OLS estimates of and the Yule-Walker estimates of are used as starting values for these methods.
The Gauss-Newton algorithm requires the derivatives of  or
or 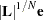 with respect to the parameters. The derivatives with respect to the parameter vector are
with respect to the parameters. The derivatives with respect to the parameter vector are
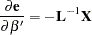 |
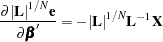 |
These derivatives are computed by the transformation described previously. The derivatives with respect to are computed by differentiating the Kalman filter recurrences and the equations for the initial conditions.
Variance Estimates and Standard Errors
For the Yule-Walker method, the estimate of the error variance,  , is the error sum of squares from the last application of GLS, divided by the error degrees of freedom (number of observations N minus the number of free parameters).
, is the error sum of squares from the last application of GLS, divided by the error degrees of freedom (number of observations N minus the number of free parameters).
The variance-covariance matrix for the components of is taken as  for the Yule-Walker method. For the ULS and ML methods, the variance-covariance matrix of the parameter estimates is computed as
for the Yule-Walker method. For the ULS and ML methods, the variance-covariance matrix of the parameter estimates is computed as 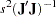 . For the ULS method,
. For the ULS method, 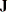 is the matrix of derivatives of with respect to the parameters. For the ML method, is the matrix of derivatives of divided by
is the matrix of derivatives of with respect to the parameters. For the ML method, is the matrix of derivatives of divided by 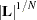 . The estimate of the variance-covariance matrix of assuming that is known is
. The estimate of the variance-covariance matrix of assuming that is known is 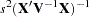 .
.
Park and Mitchell (1980) investigated the small sample performance of the standard error estimates obtained from some of these methods. In particular, simulating an AR(1) model for the noise term, they found that the standard errors calculated using GLS with an estimated autoregressive parameter underestimated the true standard errors. These estimates of standard errors are the ones calculated by PROC AUTOREG with the Yule-Walker method.
The estimates of the standard errors calculated with the ULS or ML method take into account the joint estimation of the AR and the regression parameters and may give more accurate standard-error values than the YW method. At the same values of the autoregressive parameters, the ULS and ML standard errors will always be larger than those computed from Yule-Walker. However, simulations of the models used by Park and Mitchell (1980) suggest that the ULS and ML standard error estimates can also be underestimates. Caution is advised, especially when the estimated autocorrelation is high and the sample size is small.
High autocorrelation in the residuals is a symptom of lack of fit. An autoregressive error model should not be used as a nostrum for models that simply do not fit. It is often the case that time series variables tend to move as a random walk. This means that an AR(1) process with a parameter near one absorbs a great deal of the variation. See Example 8.3 later in this chapter, which fits a linear trend to a sine wave.
For ULS or ML estimation, the joint variance-covariance matrix of all the regression and autoregression parameters is computed. For the Yule-Walker method, the variance-covariance matrix is computed only for the regression parameters.
Lagged Dependent Variables
The Yule-Walker estimation method is not directly appropriate for estimating models that include lagged dependent variables among the regressors. Therefore, the maximum likelihood method is the default when the LAGDEP or LAGDEP= option is specified in the MODEL statement. However, when lagged dependent variables are used, the maximum likelihood estimator is not exact maximum likelihood but is conditional on the first few values of the dependent variable.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.