Usage Notes for HPA Software and Hadoop
High-Performance Analytics Software
Target Table for HPA Transformations Must Have the Same SAS Name as the Source Table
The properties window
for a table enables you to specify both a descriptive name and a physical
storage name (SAS name) for the table. The descriptive name is specified
on the General tab. The physical storage
name is specified on the Physical Storage tab.
In a SAS Data Integration Studio job, the physical storage name for the target of a SAS Data in HDFS Loader must match the physical storage name of the source table. The same is true for the target of a SAS LASR Analytic Server Loader.
For example, suppose
that you had a job with a flow similar to that of the next display.
Example Flow for High-Performance Analytics Transformations
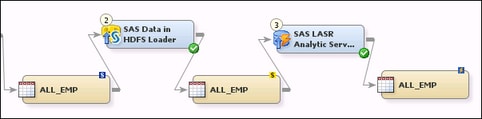
In the previous flow, the SAS Data in HDFS Loader reads a source table with the physical
storage name of ALL_EMP. It writes a target table with the same physical name. Likewise,
the SAS LASR Analytic Server Loader
reads a source table with the physical storage name of ALL_EMP, and it writes a target
table with the same physical name. Otherwise, the job would fail. This requirement
is due to the underlying SAS procedures that are used
by these transformations.
Using HDFS Tables and LASR Tables in Jobs
Tables in a SAS Data in HDFS library or a SAS LASR Analytic Server library have special
loader transformations just for them. You cannot use the standard Table Loader transformation
to load these tables. However, these tables can be used as the target of the following
transformations: Extract, Sort, Append, Splitter, Frequency, Compare
Tables, SQL Create Table, SQL Join, and SQL Set Operators.
Turn Off Collect Table Statistics for Jobs with the SAS Data in HDFS Unloader
The properties window for a SAS Data Integration Studio job enables the Options tab Diagnostics/Statistics
panelCollect Statistics option by default. If this option is enabled for a job with
a SAS Data in HDFS Unloader, the job will fail with the following
error:
Diagnostics/Statistics
panelCollect Statistics option by default. If this option is enabled for a job with
a SAS Data in HDFS Unloader, the job will fail with the following
error:
“ERROR: The SASHDAT
engine is a uni-directional engine. Data flows from the SAS client
to the Hadoop Distributed File System. The engine cannot be used to
fetch data from HDFS.”
If you deselect the Collect
Statistics option for the job, the job will run correctly.
View Data Window Cannot Display Tables in an HDFS Library or a LASR Library
The View
Data window cannot display tables in a SAS Data in HDFS
Library or a SAS LASR Analytic Server Library. For more information
about the View Data window, see Browsing Table Data.
Load Multiple Copies of a Table in a SAS LASR Analytic Server
Use the FULLCOPYTO=n
option in the PROC LASR statement to load multiple copies of a table
in a LASR server. This can be set on the SAS LASR Analytic Server
Loader transformation under PropertiesOptionsPROC LASR Options in the Additional LASR procedure options field.
Hadoop
General Usage Notes for Cloudera Impala
The following usage
notes apply to Cloudera Impala, a query engine that runs on Apache
Hadoop.
Impala does not support
SQL DELETE or UPDATE statements. Accordingly, any SAS Data Integration
Studio transformation that generates SQL DELETE or UPDATE statements
will fail if these operations are attempted on an Impala table. Affected
transformations include the SQL Delete transformation, the SQL Update
transformation, and the Table Loader transformation. For more information
about the loader transformation, see Cloudera Impala: Usage Notes for Loaders.
Impala Requires SQL
ORDER BY statements to specify a limit. The SQL Join transformation
does not specify a limit on an ORDER BY statement by default. Accordingly,
if an SQL Join transformation attempts to execute an ORDER BY statement,
the transformation will fail. If explicit pass-through is set for
the SQL Join, one remedy is to add the limit clause in the generated
code.
One way to add the limit
clause is as follows:
-
Open the properties window for the SQL Join.
-
Click the Code tab.
-
Change the Code generation mode to All user written.
-
Add the limit clause after the ORDER BY clause.Here is an example where the limit is 100 observations:
order by <column> limit 100
-
Click OK to close the properties window and save your changes.
If implicit pass-through
is set for the SQL join, one remedy is to specify a data set option,
such as OBS=100, in the properties
window for the Impala table.
One way to specify a
data set option is as follows:
-
Open the properties window for the table.
-
Select Options tabGeneralAdditional Table Options.
-
Specify an option such as OBS=100.
Usage Notes for Table Loader and Cloudera Impala Tables
Cloudera Impala is optimized for queries rather than inserts into HDFS. Accordingly,
avoid using a table in a SAS Impala library as the target of any table loader transformation.
Impala does not support
SQL DELETE or UPDATE statements. Accordingly, any SAS Data Integration
Studio transformation that generates SQL DELETE or UPDATE statements
will fail if these operations are attempted on an Impala table. Affected
transformations include the Table Loader transformation. Specifically,
the following combination of load options on the Load
Techniques tab do not work for Impala tables: Load
style: Update/Insert and Matching Rows:
SQL Set.
Copyright © SAS Institute Inc. All Rights Reserved.
Last updated: January 16, 2018