About Dimension Tables
About Change Tracking
Dimension tables that are loaded with the SCD Type 2 Loader consist of a surrogate key column, a business key column, change tracking columns, and any number of detail data columns. The surrogate
key column is often loaded with values that are generated by the transformation. The
business keys are supplied in the source data. Both the business key and the surrogate key can be defined to consist of more than
one column, as determined by the structure of the source data. A surrogate key is typically a system-generated value that contains no semantic
meaning. It is almost always a numeric value that you can use to improve join performance
between fact and dimension tables.
Change tracking columns
can consist of begin and end datetime columns, a version number column,
or a current-row indicator column. You can combine tracking methods
as needed to optimize your analyses. Using a current-row indicator
column improves the performance of the SCD Type 2 Loader.
Begin and end datetime
values specify the period of time in which each row was the current
row for that member. The following diagram shows how data is added
to begin and end datetime columns. The begin datetime for the new
current row is one second greater than the end datetime of the former
current row. The end value for the current row is a placeholder future
date.
Structure of an SCD Dimension Table
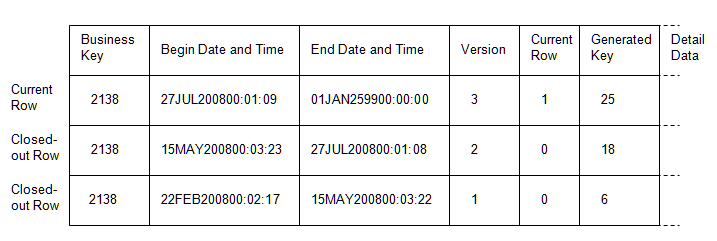
Tracking changes by version number increments a counter when a new row is added. The
current row has the highest version number for that business key. The version number
for new business keys is current_version_number + 1.
Tracking changes using
a current–row indicator column loads a 1 for the current row
and 0s for all of the other rows that apply to that same member.
The preceding diagram shows a surrogate key column, the values for which are generated
by the SCD Type 2 Loader. The generated
surrogate key is necessary in order to uniquely identify individual rows in the dimension table. The generated surrogate key values are loaded into the star schema's fact table as foreign keys, to connect factual or numerical events to the detail data that describes
those events.
About Change Detection and Loading for SCD
In jobs that run the SCD Type 2 Loader transformation, the dimension table
loading process repeats the following process for each source row:
-
Compare the business key of the source row to the business keys of all of the current rows in the dimension table. If no match is found, then the source row represents a new member. The source row is written to the target as the new current member for that business key. The current member contains the latest information. The loading process moves to the next source row.
-
If the business key in the source matches a business key in the target, then specified detail data columns are compared between the matching rows. If no differences in data are detected, then the source row is a duplicate of the target row. The source row is not loaded into the target as the new current row for that business key. The loading process moves on to the next source row.
-
If business keys match and data differences are detected in the columns specified for Type 2 SCD, then the source row represents a new current row for that member. The source row is written to the target, and the previous current row for that member is closed out. To close out a row, the change tracking column or columns are updated as specified, depending on the selected method of change tracking. If changes are detected in the Type 1 columns in Type 1 upgrades, the source data overwrites the target data in the current row. The data is overwritten even when data differences are not detected in the Type 2 columns.
About Generated Keys
The SCD Type 2 Loader enables you to generate surrogate key values when you load
a dimension table. The generated surrogate key values replace the business key as
the primary key. This is because the business key from the source table identifies the member, not
the unique row in the dimension table.
You can configure a simple surrogate key in the Generated Keys tab
of the SCD Type 2 Loader. This surrogate key increments the highest
existing value in a specified column for each new row. You can also
use an expression to generate key values in other increments. To specify
a unique starting point for the keys that are generated in each load,
you can specify a lookup column. The initial key value is the highest
value in the lookup column.
Note: When loading a fact table
instead of a dimension table, you can generate simple surrogate keys
using the Lookup transformation.
In addition to surrogate keys, you can also generate retained keys. Retained keys
provide a primary key value that consists of two columns, the begin datetime change
tracking column and
a numeric column that receives generated values. The combination of the two columns
uniquely identifies each row in the table.
The generated value
is retained because a single generated value is applied to all of
the rows that apply to a given member. When a new row is added to
an existing member, it receives the same generated value as the other
rows that apply to that member.
As with surrogate keys, you can generate retained key values using expressions and lookup columns.
In order to generate
unique retained keys, begin and end datetime change tracking is required.
To enhance performance, you should create an index for your generated key column. If you identify your generated key column as the primary key of the table,
then the index is created automatically. Surrogate keys should receive
a unique or simple index that consists of one column. Retained keys should receive
a complex index that includes the generated key column and the beginning datetime
column.
To create an index,
open the Properties dialog box for the table
and use the Index and Keys tabs.
About Cross-Reference Tables
During the process of loading an SCD dimension table, the comparison of incoming
source rows to the current rows in the target is facilitated by a cross-reference table. The cross-reference table consists of all of the current rows in the dimension table,
one row for each member. The columns consist of the generated key, the business key,
and a digest column named DIGEST_VALUE.
The digest column is used to detect changes in data between the source row and the
target row that has a matching business key. DIGEST_VALUE is a character column with
a length of 32. The values in this column
are encrypted concatenations of the data columns that were selected for change detection.
The encryption uses the MD5 algorithm, which is described in detail at http://www.faqs.org/rfcs/rfc1321.html.
If a cross-reference table exists and has been identified, it is used and updated.
If a cross-reference table
has not been identified, then a new temporary table is created each time you run the
job.
To increase performance
in large jobs, enable change tracking by current row indicator. This
method of change tracking can be combined with the other change tracking
methods (begin and end datetime and version number). The current row
indicator speeds up the process of creating or updating the digest
file. The performance improvement is provided by a WHERE clause that
efficiently separates current rows from closed-out rows.
Cross-reference tables
are identified on the Options tabs of the
following transformations: SCD Type 2 Loader and Key Effective Date,
in the field Cross-Reference Table Name.
Three Methods for Generating the Change Digest Column
The SCD Type 2 Loader supports three methods for generating the change digest column
(DIGEST_VALUE column) in a cross-reference table: v1.1 method, v2.1 method, and v2.2
method.
To specify one of these
methods:
-
Open the properties window for the applicable transformation.
-
Select Options
 SCD Options.
SCD Options.
-
In the Change digest version field, select v.1.1, v2.1, or v2.2.
The v1.1 method is the
default. The v2.1 method uses a different algorithm to concatenate
the data columns that are selected for change detection. Try v2.1
if the SCD Type 2 transformation does not detect changes in certain
scenarios.
For example, suppose
that two consecutive Type 2 columns with data type char are loaded
on day X with the following values: col_1="AB" , col_2="C"
The following delta
record might contain these values: col_1="A" , col_2="BC"
The v1.1 method uses
string handling functions that concatenate these values into an intermediate
string value of "ABC" for both the original record and the
delta record. As a result, identical DIGEST_VALUEs are incorrectly
generated for both records, and the change is not detected. If you
encounter this problem, try the v2.1 method or the v2.2 method, which
use different string handling functions.
The v2.2 method includes
the ability to detect changes between numeric values that are very
close in precision. For example, the v1.1 and v2.1 methods do not
detect a change in value between the numbers 3.1415926536 and 3.14159265358979.
As a result, identical DIGEST_VALUEs are generated for both of these
values.
About Type 1 Updates
Type 1 updates are defined as overwrites of existing data in specified columns. When
you run a Type 1 update with the SCD Type 2 Loader transformation, digest values containing
the Type 1 columns are created for the source and target. The digest values are then
compared to determine the target rows that need to be
updated. When the rows are updated, the number of writes is optimized.
You can combine Type 2 and Type 1 updates in the same job. Use Type 2 updates to maintain
a history of changes for important columns. Use Type
1 updates to maintain accurate and complete information in your dimension table, without
generating new target rows for each change.
Copyright © SAS Institute Inc. All Rights Reserved.
Last updated: January 16, 2018