Creating a Hadoop Container Job
Problem
You want to run multiple Hadoop processes without creating an overly complicated SAS
Data Integration Studio job.
Solution
You can create a SAS Data Integration Studio job that contains the Hadoop Container
transformation. This transformation enables you
to use one transformation to perform a series of steps in one connection to the Hadoop
cluster. The steps can include transfers to and from Hadoop, Map Reduce processing, and Pig
Latin processing.
For example, you can
create a sample job that performs the following tasks that are run
through the Hadoop Container transformation:
-
Transfer data from a text source file to a Hadoop output file (Transfer To Hadoop step).
-
Transfer data from a Hadoop source file to a text output file (Transfer From Hadoop step).
-
Process data using a Map Reduce step.
-
Process data using a Pig step.
Tasks
Create a Hadoop Container Job
You can create a Hadoop Container job similar to the sample job, which contains four
Hadoop steps that correspond to four
rows of tables and transformations.
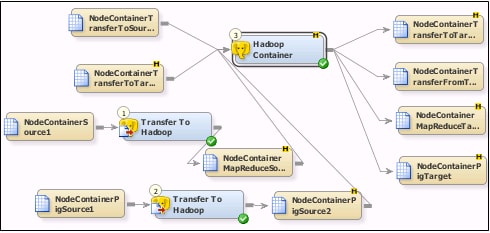
The two rows at the top of the tab are used for the Transfer To and Transfer From
steps. Note that the first row contains a text source table and Hadoop target table, where the second row contains a Hadoop source table and a text target table.
The two rows at the bottom of the tab are used for the Map Reduce and Pig steps. Note
that each row begins with a text source and a Transfer To Hadoop transformation that
creates the Hadoop source table for the Hadoop Container transformation. Both rows
feed steps that send output to Hadoop target tables.
Add and Review Hadoop Steps
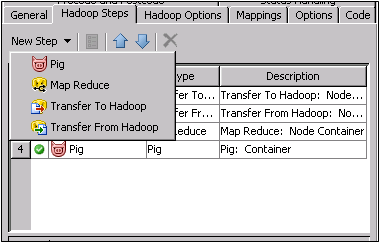
The steps processed
in the Hadoop Container transformation are listed in a table on the Hadoop
Steps tab. You can add, edit, reorder, and delete steps
by clicking the buttons in the toolbar at the top of the tab.
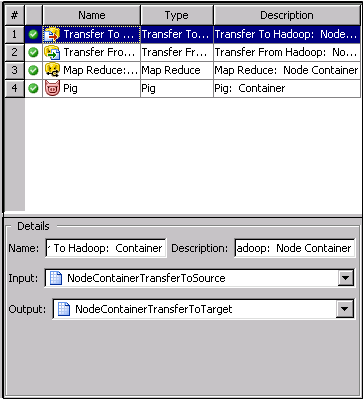
You can click a row
in the table to review its name, description, input, and output in
the Details panel at the bottom of the tab. If a step has multiple
inputs or outputs, you can use the drop-down arrow to select the object
that you need.
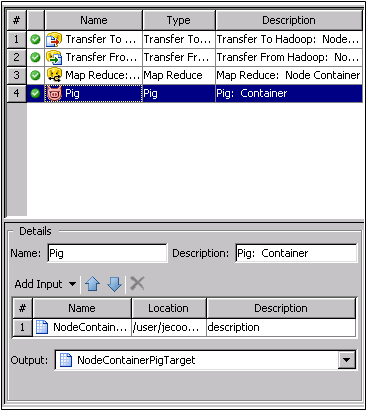
You can select a step
and click the Properties button to configure,
review, and edit its properties.
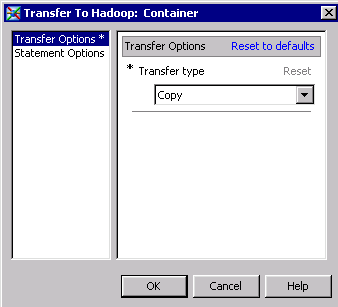
Configure a Map Reduce Step
The Map Reduce step enables you to submit your own Map Reduce code in the context
of a job. It is assumed that you know Map Reduce well enough to use it in a production
environment.
Your Hadoop installation usually includes an example Map Reduce program. You must
create your own Map Reduce program in Java and save it to a JAR file. You then specify
this JAR file in the properties window for the Map Reduce step, along with some relevant
arguments.

Use the Additional
Map Reduce jars field to specify a JAR file that contains
your user-written Map Reduce code. Use the other fields to specify
relevant arguments from that code.
The Map Reduce Options section
of the Advanced Options window also contains several other options that are not set in the sample job.
Finally, the Map Reduce
step in the sample job includes the following advanced options (accessed
by clicking Advanced Options):
-
Output format class name: org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
-
Output key class name: org.apache.hadoop.io.Text
-
Output value class name: org.apache.hadoop.io.IntWritable
Note that the All
files in this location check box must be selected on
the File Location tab in the properties window for the Map Reduce target table. This step enables you
to see the data in the table after the job has completed successfully.
Configure a Pig Step
The Pig step enables
you to submit your own Pig Latin code in the context of a job. It
is assumed that you know Pig Latin well enough to use it in a production
environment. The properties for the Pig step in the sample job are
shown in the following display:
Pig Properties
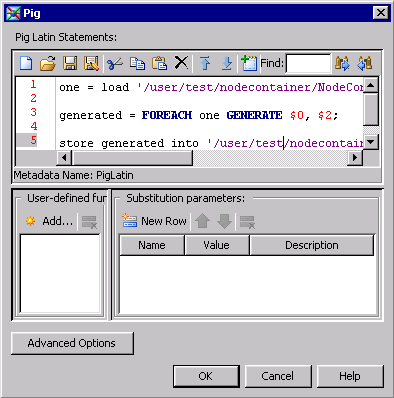
The Pig step contains
the following statements:
one = load '/user/test/nodecontainer/NodeContainerPigSource2.txt' using PigStorage();
generated = FOREACH one GENERATE $0, $2;
store generated into '/user/test/nodecontainer/NodeContainerPigTarget.txt'
USING PigStorage(',')Note that the All
files in this location check box must be selected in
the File Location tab in the properties window for the Pig target table. This step enables you to see
the data in the table after the job has completed successfully.
Configure the Hadoop Options Tab
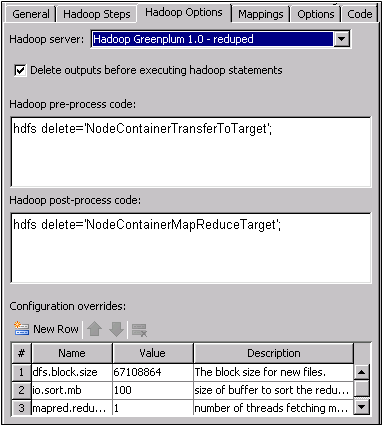
The Hadoop
Options tab enables you to set options such as server
selection, output deletion, pre- and post-process code, and configuration
overrides for all of the steps. Note that the pre- and post-process
code on this tab is run against the Hadoop server only. This code
is not the standard pre- and post-process code that is run on the
SAS workspace server. Therefore, SAS code is not appropriate input
for these fields.
Run the Job and Review the Output
Run the job and verify that the job completes without error. Then, review the output.
You should
see the following results:
-
The Hadoop external file target NodeContainerTransferToTarget has the same 6 observations as its NodeContainerTransferToSource source external file.
-
The external file target NodeContainerTransferFromTarget, which is not a Hadoop target, has the same 6 observations as its NodeContainerTransferToTarget source external file.
-
The Hadoop external file target NodeContainerMapReduce has 7,816 different words, each in separate observations.
-
The Hadoop external File target NodeContainerPigTarget has the same 6 observations as its NodeContainerPigSource2 source external file.
Copyright © SAS Institute Inc. All rights reserved.