Determining the Observation Boundary to Select the Best Columns
This example imports
an XML document that illustrates how to determine the observation
boundary so that the result is the best collection of columns.
The observation boundary
translates into a collection of rows with a constant set of columns.
Using an XMLMap, you determine the observation boundary with the TABLE-PATH
element by specifying a location path.
In the following XML
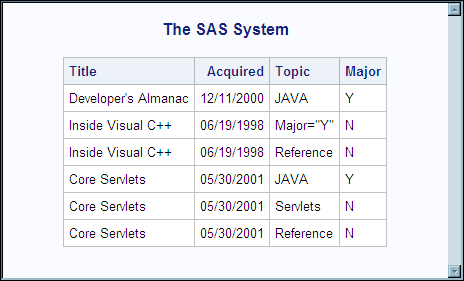
document, PUBLICATION appears to be a possible element to use as the
observation boundary, which would result in these columns: TITLE,
ACQUIRED, TOPIC. However, the TOPIC element occurs arbitrarily within
a single PUBLICATION container, so the result would be a set of columns
with TOPIC occurring more than once. Therefore, the TOPIC element
is the better choice to use as the observation boundary in order to
result in these columns: TITLE, ACQUIRED, TOPIC, and MAJOR.
<?xml version="1.0" encoding="iso-8859-1" ?>
<Library>
<Publication>
<Title>Developer's Almanac</Title>
<Acquired>12-11-2000</Acquired>
<Topic Major="Y">JAVA</Topic>
</Publication>
<Publication>
<Title>Inside Visual C++</Title>
<Acquired>06-19-1998</Acquired>
<Topic>Major="Y">C</Topic>
<Topic>Reference</Topic>
</Publication>
<Publication>
<Title>Core Servlets</Title>
<Acquired>05-30-2001</Acquired>
<Topic Major="Y">JAVA</Topic>
<Topic>Servlets</Topic>
<Topic>Reference</Topic>
</Publication>
</Library><?xml version="1.0" ?>
<SXLEMAP version="1.2">
<TABLE name="Publication">
<TABLE-PATH syntax="XPath">
/Library/Publication/Topic 1
</TABLE-PATH>
<COLUMN name="Title" retain="YES">
<PATH>
/Library/Publication/Title
</PATH>
<TYPE>character</TYPE>
<DATATYPE>STRING</DATATYPE>
<LENGTH>19</LENGTH>
</COLUMN>
<COLUMN name="Acquired" retain="YES">
<PATH>
/Library/Publication/Acquired
</PATH>
<TYPE>numeric</TYPE>
<DATATYPE>FLOAT</DATATYPE>
<LENGTH>10</LENGTH>
<FORMAT width="10" >mmddyy</FORMAT> 2
<INFORMAT width="10" >mmddyy</INFORMAT>
</COLUMN>
<COLUMN name="Topic">
<PATH>
/Library/Publication/Topic</PATH>
<TYPE>character</TYPE>
<DATATYPE>STRING</DATATYPE>
<LENGTH>9</LENGTH>
</COLUMN>
<COLUMN name="Major">
<PATH>
/Library/Publication/Topic/@Major
</PATH>
<TYPE>character</TYPE>
<DATATYPE>STRING</DATATYPE>
<LENGTH>1</LENGTH>
<ENUM> 3
<VALUE>Y</VALUE>
<VALUE>N</VALUE>
</ENUM>
<DEFAULT>N</DEFAULT> 4
</COLUMN>
</TABLE>
</SXLEMAP>The previous XMLMap tells the XML engine how to interpret
the XML markup as explained below:
| 1 | The TOPIC element determines the location path that defines where in the XML document to collect variables for the SAS data set. An observation is written each time a </TOPIC> end tag is encountered in the XML document. |
| 2 | For the ACQUIRED column, the date is constructed using the XMLMap syntax FORMAT element. Elements like FORMAT and INFORMAT are useful for situations where data must be converted for use by SAS. The XML engine also supports user-written formats and informats, which can be used independently of each other. |
| 3 | Enumerations are also supported by XMLMap syntax. The ENUM element specifies that the value for the column MAJOR must be either Y or N. Incoming values not contained within the ENUM list are set to MISSING. |
| 4 | By default, a missing value is set to MISSING. The DEFAULT element specifies a default value for a missing value, which, for this example, is specified as N. Note that when the ENUM element is used, a value specified by DEFAULT must be one of the ENUM values to be valid. |